# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
o1模型已经强到,能够直出博士论文代码了!
来自加州大学欧文分校(UCI)的物理学博士Kyle Kabasares,实测o1 preview+mini后发现:
自己肝了大约1年的博士代码,o1竟在1小时内完成了。

他称,在大约6次提示后,o1便创建了一个运行版本的Python代码,描述出研究论文「方法」部分的内容。
虽然AI生成的代码框架,模拟了Kabasares实际代码功能,但它使用的是「合成数据」,并非真实的天文数据。

论文地址:https://iopscience.iop.org/article/10.3847/1538-4357/ac7a38/meta
不过,o1能够在这么短时间输出复杂代码,足以震撼。
视频右下角中,Kabasares连连喊出「oh my god」,各种难以形容的动作表情,被震惊到怀疑人生。
YouTube视频一出,便在全网掀起热议,网友们纷纷表示太疯狂了。
好巧不巧的是,o1在最新门萨智商测试中,IQ水平竟超过了120分。
35个智商题,答对了25道,把其他模型甩出好几条街。

然而,这仅仅是o1模型的preview版本。
OpenAI研究人员David Dohan曾发文暗示,一个月后,o1模型还将有全新的升级版本。

届时,还不知o1性能,将有多么逆天?!
物理学博士论文,AI 1小时直出200行代码
2022年,物理学博士Kabasares以第一作者身份,在「天文物理期刊」发表了这篇关于,通过对天文数据建模来测量黑洞质量的论文。
当然,这篇研究不仅仅是写代码,但实现这段代码,是Kabasares博士第一年的关键突破。
可以说,在他博士研究的阶段的第一年(2018年7月-2019年4月),花费了大量时间,才让这段代码初版正确运行起来。
这也是,为什么o1能在1小时内,给出一个可运行的Python代码,让Kabasares印象深刻。

视频中,看到o1输出的代码后,Kabasares缓了好大一阵儿,才开始接下来的解释。
他向ChatGPT o1提供了论文中,「方法」部分的内容(即第4节),并提示阅读我的论文,根据所给信息,写出一段Python运行代码。
他多次强调,自己没有向o1展示自己代码。
在于ChatGPT对话页面中,Kabasares向大家展示,并细数了下o1是在6次提示下,完成200行代码。

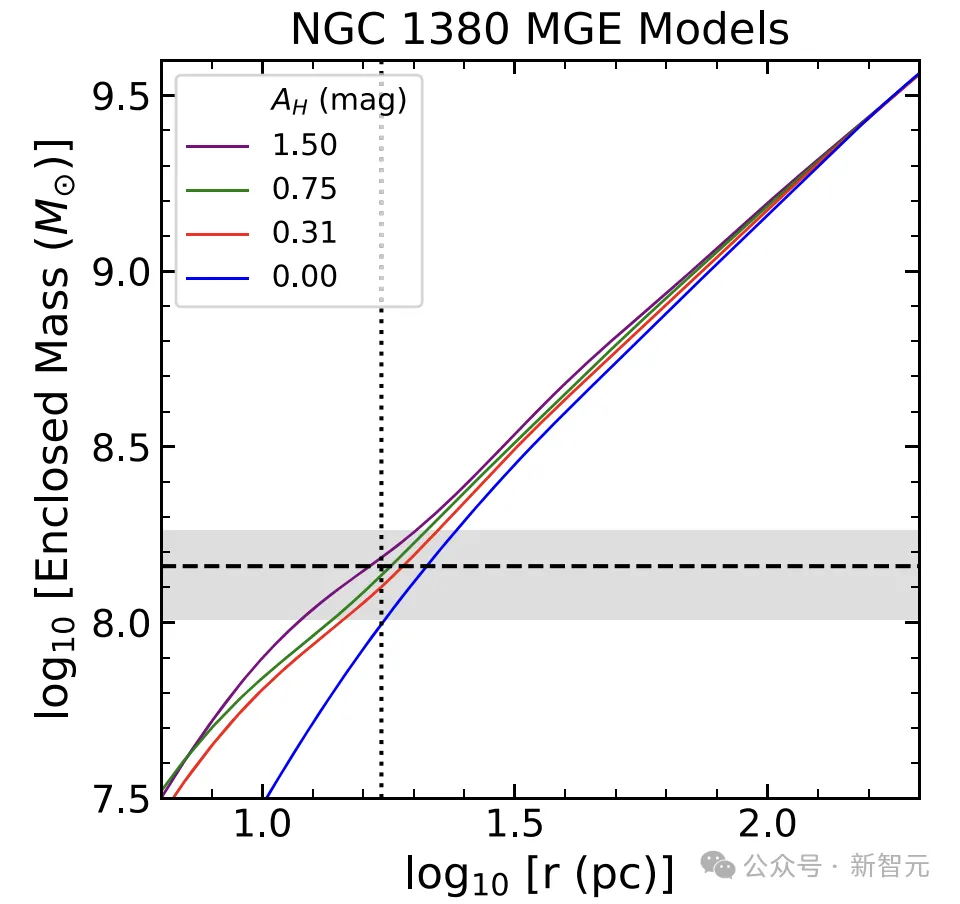
不过,他也提出警告,实际上还需要我们自己去做一些额外的工作。就像论文中这个曲线图,还得需要在另一个软件,比如银河图像软件中完成。
当网友询问到,有没有可能o1就着你自己的代码,完成的训练?
Kabasares认为,o1输出的200行代码,与自己1100行代码有着很大的不同,这是论文代码「最简版本」。

为此,Kabasares又发了第二弹视频,向所有人解释o1可能真的没有接受过数据训练。


值得一提的是,他从办公室拿到的私密文件,是由教授亲自设计的天体物理学问题。
这些题目,都是Kabasares在博士期间完成的,并没有发布到互联网上。
他专门为o1出了一个测试集,一共有4道题目。

而在没有训练数据的情况下,o1输出的结果不用说。甚至,有的题它仅在16秒内,完成了解答。

还记得,OpenAI CTO Mira Murati在接受采访中表示,GPT-4之后的新模型将达到博士级别的智能。
o1现在的表现,已经是关键的一瞥。

代码编程赛,大师级别
作为OpenAI的研究主管兼现任的IOI美国队教练,Mark Chen分享了o1模型在Codeforces比赛上的最新进展。
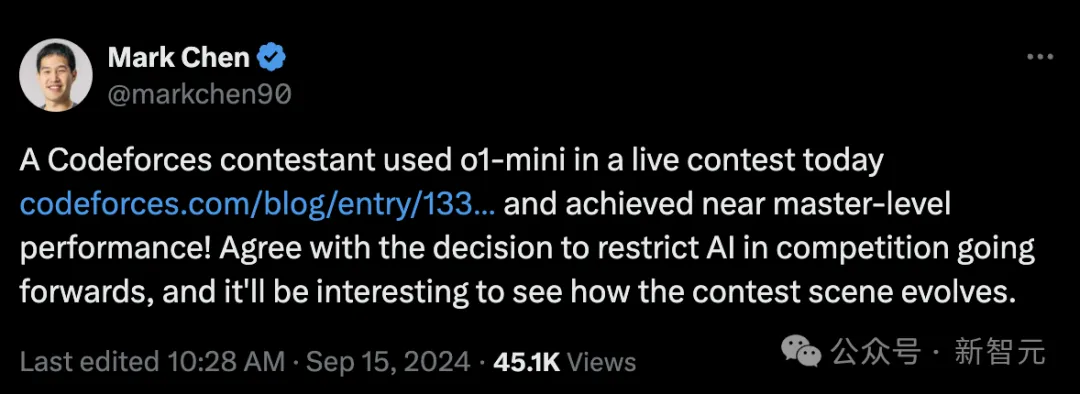
在Codeforces昨天的实时比赛中,一位名为AryanDLuffy的选手使用了o1-mini模型参加比赛,结果相当惊艳。
用Mark Chen的话来说,达到了「接近大师级别的表现」。
AryanDLuffy发帖表示,自己没有进行任何提示工程,仅仅是给出问题陈述,并告诉模型用C++解题。
7道题目中,o1-mini仅在B2、D和E2遇到了困难,其中D和E2是不少排名前50的选手也没能得分的,也是提交人数最少的两道题目。
最终,o1-mini帮助AryanDLuffy获得了3922分的总成绩,在超过16万参赛者中排名277,也就是排名在前0.17%。
这远远超过了OpenAI自己做的基准测试结果。o1模型在他们的模拟Codeforces比赛中还只是超过了89%的人类选手。
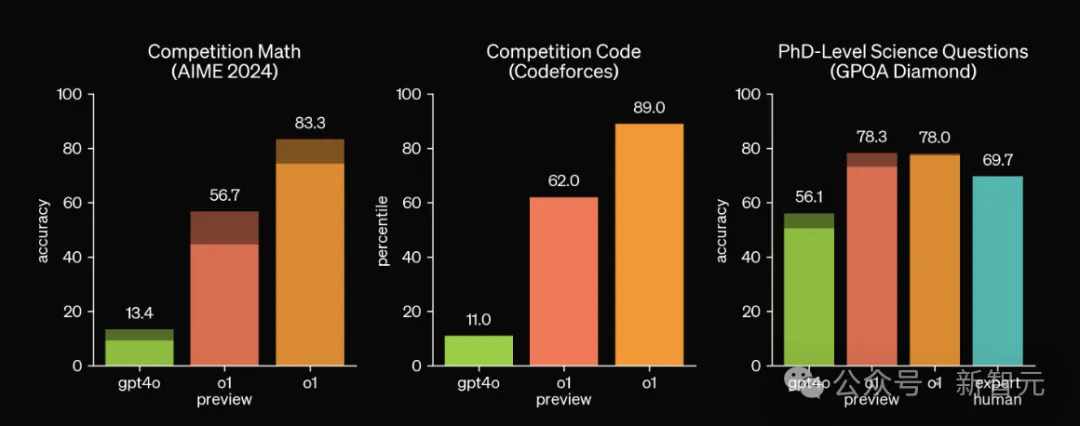
277的排名相比AryanDLuffy本人之前的纪录提高了158位,达到了4年来最大的进步幅度。
对此,Mark Chen和很多网友的想法是,IMO和Codeforces的竞赛题也许可以作为新型的LLM基准测试。然而,Codeforces的主办方担心的是另一件事。
竞赛创始人Mike Mirzayanov为此特地制定了一条新规:禁止使用GPT、Gemini、Gemma、Llama和Claude等各种模型来解决Codeforces竞赛中的编程问题。
但是这条新规并不是要求参赛者完全摒弃AI,他们依旧可以让模型辅助翻译问题陈述,或者向Copilot寻求语法帮助和次要的编码建议。
简而言之,竞赛问题的核心逻辑、算法,以及bug的诊断调试,都必须由人类选手独立完成,CF也会进行作弊检测。在非竞争性问题中,AI工具的使用则完全不受限制。
但也有用户指出,作弊检测实质上很难执行,参赛者简单修改一下AI生成的代码就可以「逃过法眼」。竞争性编程竞赛的未来,很大程度上决定于选手们自己能否守信。
CF也表示,会持续关注AI技术的进展,并根据需要及时调整规则。

在博文中,Mirzayanov将神经网络的进展称为「技术奇迹」,因为不久前这些模型还很难完成竞赛中最简单的任务,但现在却达到了不容忽视的高度。
他表示,「我们有理由相信,这种进步会持续下去,AI可能会在编程竞赛领域继续取得新的突破。」
陶哲轩实测后续
除了Codeforces,陶哲轩大神也表示,由于大家对他之前测试的兴趣,因此继续放出了一些其他的o1 preview实验结果。
第一个实验,是找术语。
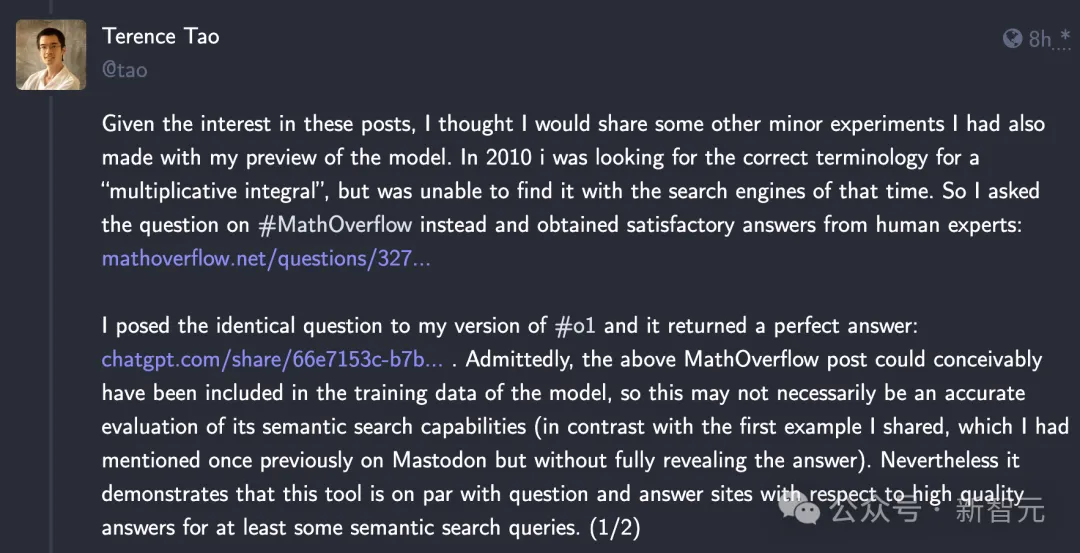
2010年,我正在寻找「乘法积分」的正确术语,但当时没有用搜索引擎找到。于是我转而在MathOverflow上提出了问题,并从人类专家那里得到了满意的答案:

14年后的今天,陶哲轩再次向o1模型提出了相同的问题,问题表述都和MathOverflow上的帖子几乎一模一样。
相比人类专家,o1给出的答案更加全面而且完美。不仅包含了5个可能的术语,还附上了相应的数学表示、应用领域和参考文献。
陶哲轩表示,虽然这篇MathOverflow上的帖子可能已经包含在o1的训练数据中了,但依旧能展现模型在语义搜索方面的强大功能,而且搜集、总结出的答案的质量可以与MathOverflow这类专业的问答网站相当。
另一个实验则更具创造性,与陶哲轩本人的研究直接相关。

作为另一个小实验,我给了o1我最近的博客文章的前半部分,其中总结了之前我自己能够解决的鄂尔多斯问题的进展。

要将之前的部分进展转换为全面的解决方案,仍缺失一些要素,我要求o1模型找到这些转换要素,但结果有点令人失望。
本质上,模型提出的策略与博客中重述的最新研究是相同的,并针对该策略没有提供任何创造性的改变。
总的来说,我觉得虽然LLM工具有一定的能力,可以随机生成创造性策略,但这方面的LLM工具仍然相当薄弱。
多篇论文阐述o1运作机制,DeepMind上大分
o1模型发布不到一周,我们就已经见证了这么多惊人的用例,AI技术界对o1背后的机制和原理也是众说纷纭。
前谷歌搜索工程师、Menlo Ventures风投家Deedy Das曾大胆猜测,其主要原理来自DeepMind一篇今年8月发表的论文。

论文地址:https://arxiv.org/abs/2408.03314
论文提出,让LLM进行更多的「测试时计算」(test-time computation),对于构建能在开放语境下操作、能实现自我提升的agent,是关键的一步
而这篇论文就重点研究了扩展「推理期计算」(inference-time computation)这个问题。
研究团队分析了扩展测试时计算的两种主要机制:(1)针对密集的、基于过程的验证器奖励模型进行搜索;(2)根据测试时得到的提示词,自适应更新模型对响应的分布。
结果显示,在这两种情况下,对测试时计算的不同扩展方法的有效性,很大程度上取决于提示词的难度。
基于此,研究团队提出了一种「计算最优」扩展策略——通过为每个提示词自适应地分配测试时计算,使测试时计算的扩展的效率提高4倍以上。
另外,在FLOPs一致的评估中,对于那些较小的基础模型已取得一定程度非平凡成功率的问题,测试时计算可以使其超越规模大14倍的模型。
此外,HuggingFace技术主管Philipp Schmid也开列了一份论文清单,包含了o1模型可能的工作原理,主要关于通过训练/RLHF而非提示工程,提升LLM在复杂任务上的推理性能。

这5篇论文都发表于今年或去年,可以说是代表了细分方向的前沿进展。
第一篇是斯坦福和Notbad在今年3月提出的Quiet-STaR(Self-Taught Reasoner)。

论文地址:https://arxiv.org/abs/2403.09629
论文的想法来源于这样一个直觉:在写作和说话时,人们有时会停下来思考,但思考和推理的内容不会显式地表达出来,而是隐含在书面文本中。
因此,理想情况下,语言模型可以学习推断文本中未阐明的基本原理。
Quiet-STaR是对2022年发表的STaR的推广,让模型为每个token生成基本原理来解释未来的文本,从而提升预测能力。
第二篇同样是斯坦福学者和MultiOn在今年8月合作发表的AgentQ框架。

论文地址:https://arxiv.org/abs/2408.07199
他们将蒙特卡罗树搜索(MCTS)与自我批评机制相结合,并使用直接偏好优化(DPO)算法的off-policy变体对agent的交互进行迭代微调。
这种方法允许LLM agent同时从成功和不成功的轨迹中进行有效学习,从而提高在复杂的多步骤推理任务中的泛化能力。
第三篇则针对数学推理,以期提升模型的问题理解能力和「反思」能力。

论文地址:https://arxiv.org/abs/2406.12050
具体来说,论文提出了一种新颖的「反思增强」方法,将问题的反思嵌入到每个训练实例,训练模型考虑其他可能的视角,并进行抽象和类比,通过反思性推理促进更全面的理解。
V-STaR这篇文章同样是对STaR框架的推广,发表于今年2月。

论文地址:https://arxiv.org/abs/2402.06457
论文提出,原有的STaR方法在迭代过程中丢弃了大量不正确的解决方案,可能忽略了其中有价值的信息。
V-STaR正是要弥补这个缺陷,它同时利用了自我改进过程中生成的正确和错误的解决方案,用DPO训练出一个验证模型,以判断生成的解决方案的正确性。该验证器在推理时使用,从候选解决方案中进行选择。
实验发现,运行V-STaR进行多次迭代,可以逐渐训练出性能更好的推理模型和验证模型。
Let's Verify Step by Step这篇论文,便是由AI大牛Ilya带队完成。

论文地址:https://arxiv.org/abs/2305.20050
论文中,主要探讨了大模型在复杂推理中,如何优化训练策略的问题,尤其是,如何利用CoT进行思考。
他们提出了过程监督方法(process supervision),由此训练的一种全新模型,在解决数学问题上取得了突破。
这一策略的强大之处在于,比起结果监督,在推理过程中逐步奖励,进而让模型性能显著提升。
除了推特帖中一开始涉及的5篇,Schimid还在HuggingFace上单开了一个网页,持续搜罗相关论文,目前已经涵盖了7篇。

https://huggingface.co/collections/philschmid/llm-reasoning-papers-66e6abbdf5579b829f214de8
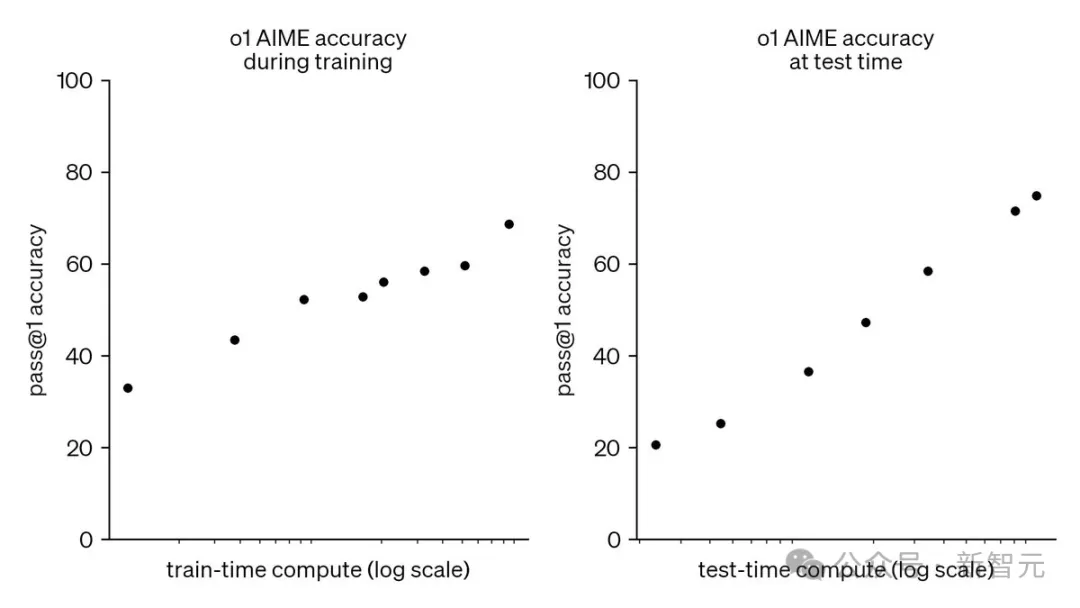
Jim Fan在一篇分析帖中指出,o1模型给我们带来的关键见解是这两条曲线的齐头并进——训练时的scaling law和推理时的scaling law,而后者才是真正战胜收益递减的关键因素。
此外,他还cue到了两篇论文,能够解决我们关于「o1自我提升能力」的疑问。一篇是Meta和NYU在今年1月提出的「自我奖励的语言模型」。

论文地址:https://arxiv.org/abs/2401.10020
这篇文章基于一个非常简单的想法:对同一个LLM进行提示,引导它生成响应并自我奖励,进行迭代自举。
论文称,奖励建模能力不再属于一个固定、独立的模型,而是可以跟随主模型的步伐提升。但有趣的是,最多3次迭代之后,依旧会出现模型饱和。
对此,Jim Fan的想法是,作为评论者(critic)的奖励模型,提升速度小于作为行动者(actor)的生成模型,因此尽管二者都在提升,最多3轮迭代后,后者就会追上前者,达到饱和。
另一篇文章是DeepMind去年8月就发表的ReST(Reinforced Self-Training),其实验结果也很类似:在达到收益递减前,最多进行3轮迭代。

论文地址:https://arxiv.org/abs/2308.08998
这两篇论文似乎证明了,评论家和行动者之间不存在可持续的能力差距,除非引入外部驱动信号,比如符号定理验证、单元测试套件或编译器反馈。
但这些都是特定领域的高度专业化的内容,要想实现我们理想中的LLM的通用自我提升,还需要发掘和探索更多的研究想法。
文章来源于“新智元”,作者“新智元”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
