# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI的研究科学家布朗(Noam Brown),这两天在他的自我介绍中,加上了一条:OpanAI o1的联合创始人。
他在OpenAI主要研究多步推理、自我对弈和多智能体人工智能。之前他已经取得成就可谓辉煌:他和FAIR(Meta)的团队开发了CICERO,这是第一个在策略游戏《外交》中达到人类水平表现的人工智能。在卡内基梅隆大学期间,他与导师一起开发了Libratus和Pluribus,在人机对抗赛中击败了顶级人类扑克职业选手。
他早期的职业,其实是金融交易员。布朗在美联储的国际金融市场部门工作,研究金融市场的算法交易,之前是华尔街上一名从事算法交易的工程师。
2012年,深度学习开始进入黄金时代,他进入卡内基梅隆大学计算机系,硕士和博士的专业分别是机器人和计算机科学。2017年,布朗在Deepmind实习,参与了AlphaGO Zero项目。
早在大模型兴起之前,DeepMind用强化学习的方法,在游戏和博弈中,已经取得了超人的成就,问题在于,这种在给定领域的超人智能,能否泛化到其他领域,产生通用的人工智能。早在OpenAI之前,AGI已经是DeepMind的使命:解决智能,然后解决一切。
今年3月10日,布朗在X上发布了一组推文,纪念AlphaGo战胜围棋世界冠军8周年。他实际上是在向席尔弗(David Silver)致敬。
席尔弗是DeepMind的首席研究科学家,他领导了AlphaGo项目,首次在围棋比赛中击败顶级职业选手;之后的AlphaZero能自我对弈学习,成为世界上最强大的国际象棋、将棋和围棋程序。他还共同领导了AlphaStar项目,开发出了世界上首个达到特级大师水平的星际争霸玩家。西尔弗在谷歌的研究重点是基于强化学习的人工智能代理,共同领导了将深度学习和强化学习相结合的项目。
最近,西尔弗在MIT的一次演讲中指出,强化学习,正在引领AI跨越大型语言模型(LLM)之谷。他认为,单靠LLMs不足以取得超级人工智能。超级规模的强化学习展开了一条通向超人智能的明确路径。其有效性已经一再得到证明(如Atari,AlphaGo,AlphaZero......)。同样的方法也适用于强大的LLM先验模型(例如AlphaProof)。而这一切“仅仅是开始”。
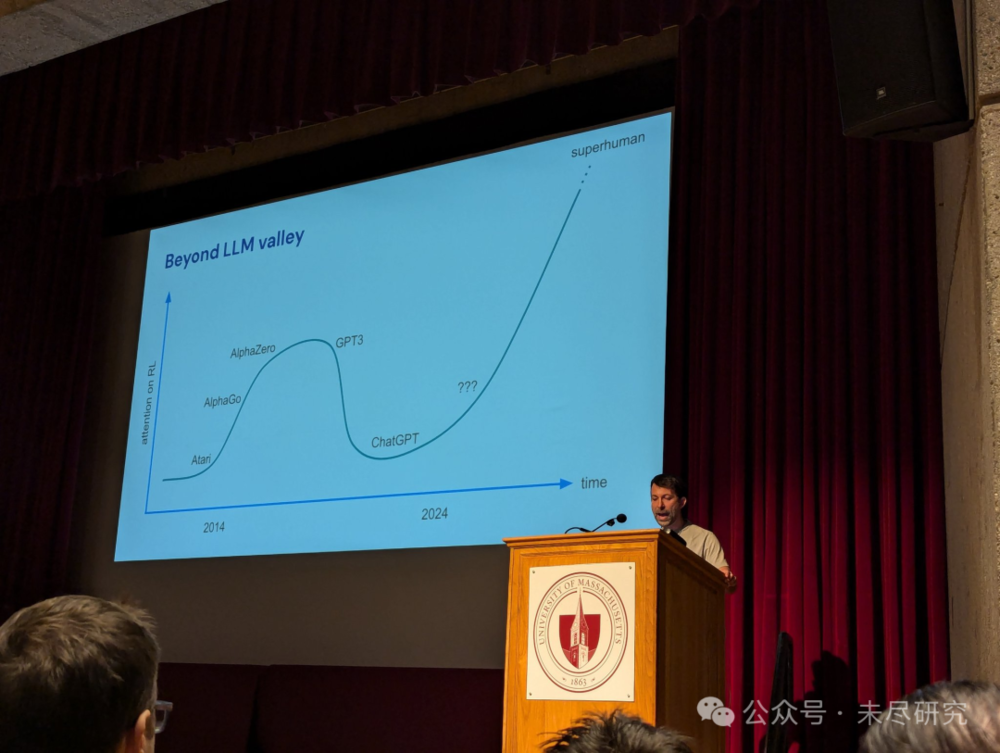
演讲截图
这个大模型新时代的机会,被布朗抓住了。2023年7月,布朗从Meta跳槽到OpenAI,当时他的想法很明确:“多年来,我一直在研究人工智能在扑克和外交等游戏中的自我博弈和推理。现在,我将探讨如何使这些方法真正通用。如果成功,我们或许有一天会看到比GPT-4强大1000倍的大型语言模型。”
布朗认为,AlphaGo在击败世界冠军李世石时,关键在于每下一步棋之前一分钟的“思考”。AlphaGoZero的学习和推理方法,相当于预训练10万倍的规模。布朗在扑克游戏中也发现了同样的规律,并且用AI首次在扑克游戏中战胜了人类顶级选手。2021年,琼斯(Andy Jones)在六边形游戏(Hex)的实验中,发现并总结了这一规律,他的论文《通过棋盘游戏扩展缩放定律》展示了如何在蒙特卡罗树搜索(MCTS)的训练计算和推理计算之间进行权衡。增加10倍的MCTS步骤几乎等同于多训练10倍。
布朗认为,如果发现一种通用的方法,不仅限于游戏,会带来巨大的好处。“是的,推理可能会慢上1000倍,而且会更昂贵,但是,为了研发一种治疗癌症的药物,或者证明黎曼猜想,多少推理的代价我们不会付出呢?”而且它会对AI大模型的安全对齐研究带来新的方法。
o1在OpenAI准备了很久,在2023年3月微软发布了测评GPT-4的深度论文时,就提出解决大模型中的幻觉问题,需要开发出类似人脑的“第二系统”,即慢思考功能。直到去年10月份,o1的研发才开始展开,OpenAI逾百名员工参与。此时正值OpenAI董事会突然解除奥特曼的CEO职位前夕,传得沸沸扬扬的OpenAI的Q*模型项目,主要负责人之一正是布朗。Meta的首席AI科学家杨立昆认为布朗正在研究Q*,即强化学习中的Q-learning(值函数算法)。
o1预览版和轻量版发布了,被广泛认可开辟了大模型研究的新方向,也是扩展定律的新范式。布朗回忆自去年7月加入OpenAI,现在这一切都发生得快于预期。
随着最初创始人的纷纷离去,新一代的顶级人才正在接过火炬。o1正在接管OpenAI的一些工作——关于Codebase的公关稿,已经几乎完全由o1撰写。
据硅谷媒体报道,为了实现以1500亿美元的估值融资65亿美元,奥特曼可能会彻底改变OpenAI的治理结构,在2025年废除顶层非营利公司,让OpenAI完全成为一家营利性公司。
OpenAI还是原来的那家公司吗?它的创始人几乎走光了,它的治理结构已经改变,它所做的大模型发展方向已经发生改变,原先从事的工作,已经被称为“传统大模型”。现在,在OpenAI内部,有些人认为,已经没有必要做出一个GPT-6级别的基础模型,才能达到人类水平的推理表现,通向AGI,就差一个强化学习了。o1开启了这一进程,并且初步证明了这一点。

原联合创始人兼首席科学家苏茨克沃(Ilya Sutzkever)对于扩展定律的信仰,成为OpenAI的灵魂。苏茨克沃的离开,标志着OpenAI正在进入一个新的发展阶段。
苏茨沃克对强化学习的大模型不感兴趣吗?无论是当年西尔弗关于AlphaGo的论文,还是后来OpenAI的论文Let's Verify Step by Step,苏茨克沃都是其中的作者之一。他本人对于用强化学习实现Superman Intelligence那一套,一点都不陌生,而且当年正是他把布朗招至麾下。
如果说实现AGI,就差一个强化学习,这样的方向,苏茨克沃在离开之前就已经为OpenAI定下。他后来共同负责安全对齐工作,并且打算用4年时间解决“超级智能”的对齐问题。但他离开了OpenAI,创办了自己的公司SSI(Safe Superintelligence Inc)并且称他未来推出的第一个产品将是安全的超级人工智能。
现在,我们要面对三个概念,它们之间的关系要搞清楚:
o1出现之后,LLM+RL=AGI,AGI+Ilya=SSI或ASI?
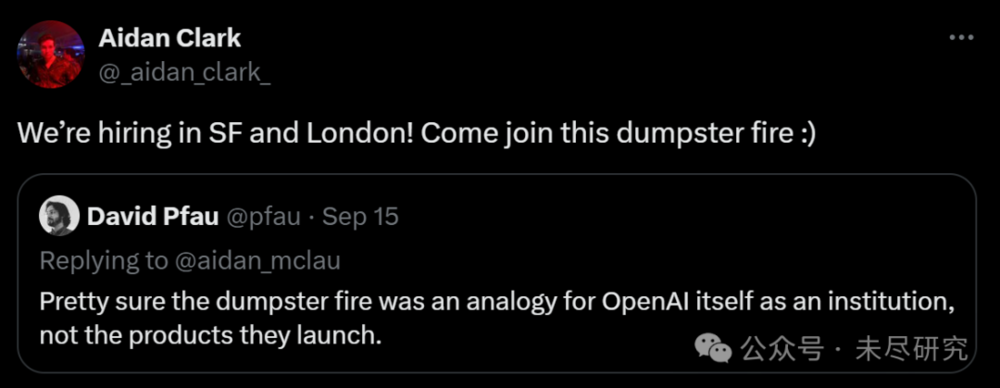
今年以来,OpenAI公司闹个不停,苏茨克沃等创始人及团队主力出走、奥特曼的领导力受到质疑、GPT-4已经被主要对手赶超而GPT-5迟迟没有发布,由于出现高达50亿美元的亏损,公司的财务可持续性也令人担忧。所以这一切,在让OpenAI看起来像是团正在燃烧的“垃圾箱大火”(dumpster fire)。现在,随着o1的发布,Open AI一时又成为街上最靓的仔,对外称不缺算力只缺人,展开了新一轮的招兵买马。
“来吧,加入这场垃圾箱大火。”
文章来自于微信公众号“未尽研究 ”,作者“未尽研究 ”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
