# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI视频国内战场,阿里也下场了。
刚刚,通义万相AI生视频功能上线!
今天下午的阿里云栖大会上,CTO周靖人宣布,官网和App上都可以立刻试用了。
比起国外爆火的Sora、Gen-3 Alpha,通义万相是更能听懂中国话,更懂中国风的AI视频模型。
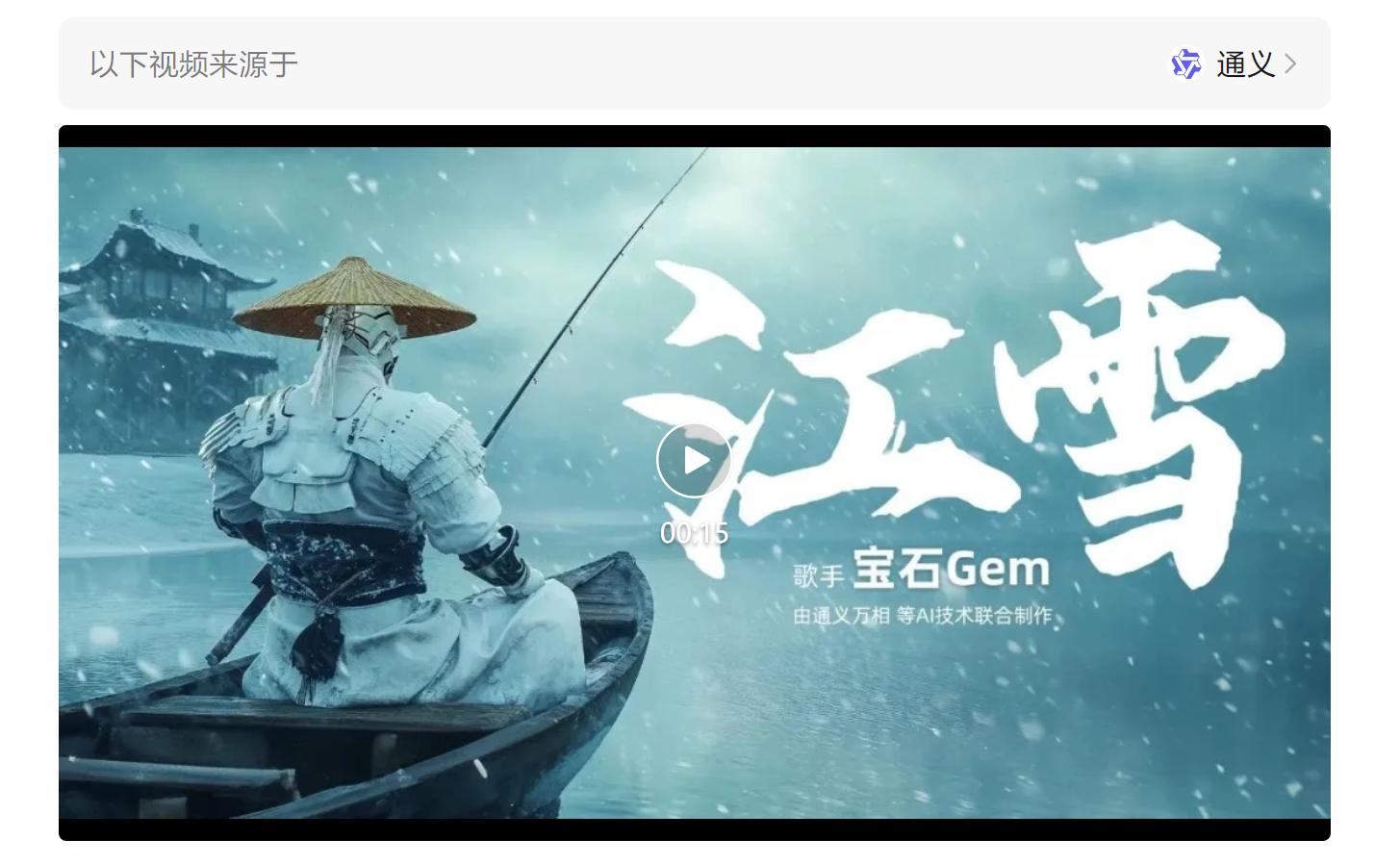
今晚飞天音乐节上的视频「江雪」,就是由通义万相生成的
它能够支持最长5秒视频生成,每秒30帧,分辨率为720P。更惊艳的是,它还能生成与画面匹配的音效。
这背后得到了阿里全自研的视觉大模型加持,并采用了业界领先的核心架构——Diffusion+Transformer。
划重点:手机端App不限次数,完全免费用!PC端,每天登陆送50个灵感值,可生成10次。
要知道,画饼的Sora还不能用,上线的Gen-3 Alpha等都得充值,还有一些仍然处于内测当中。
相比之下,通义万相是免费的,次数无限用,还不是期货,不需要排队!
更懂中国风、中国话
既然已经上线,我们就迫不及待地展开试用了。
在通义万相页面上输入提示「黑发古风女孩,快速转身微笑,国风发髻,纯色高清」,一条5s的视频就火热出炉了。
人物还原,眼神灵动,甚至还配有古香古色的背景音。

无论是缓缓抬起的眼神,还是头发在空中飘动的样子,都美得摄人心魄。

转向镜头的瞬间,就被她的样貌惊呆了。

就连中国传统的建筑风格——楼阁式塔,它也能很好地还原出来。
在白雪皑皑的山间,一座雄伟的中国古典建筑巍然屹立,精致的木雕,仿佛置入仙境一般。

再来看看,通义万相生成的古风男子,非常优秀地描绘了温文尔雅的气质。

古风装扮的男子身着月牙白锦袍,站立在雅致的古典园林中,他的一举一动都透露出温文尔雅的气质。镜头从他的侧脸缓缓推近,展现出他眸光温柔,仿佛能洞察人心,给人以温暖和安慰。周围的景致与他的装束相得益彰,共同构建了一幅如诗如画的古典美男图卷。
从某种意义上讲,通义万相是AI视频模型中,更懂国风的那个。
文生视频
在多次试用通义万相的文生视频能力后,不得不感慨:这款AI产品,实在是太有想象力了!而且,每一个视频,AI都会自动配上BGM。
通过提示词,我们就可以用文字控制画面内容和变化的过程。

晨雾,日出,镜头光晕,清冷风,一个五官精致的年轻中国女子,长长的头发被风吹乱,头发丝飘,散在脸上,穿着夏装,背景海边沙滩
蛛网上挂着透明的水滴,形成了美丽的光斑和折射,通义万相在这个视频中,体现出了对物理光学规律的规律,画面的美感也很动人。

更多无厘头想象的画面,现在都可以变成现实了。无论是在南极大陆上工作的企鹅邮差,还是在米山中间行驶的玉米列车。


而切实地使用过之后,通义万相对概念组合的语义理解、画面的视觉动态、风格泛化能力、国风理元素的呈现,无不给人留下了深刻印象。
可以看出,通义万相的指令遵循能力,着实令人深刻。
一句话总结——它就是「最听话」的AI生视频模型。
无论是画面内容、空间构图、运动过程、运镜方式,它均有良好的支持。
而这个模型还是原生支持中文的长文本提示词,因此相比起国外的模型,更能理解中文的复杂语义理解和概念组合生成能力,能将文字创意精准呈现。
何为一个视频模型的想象力?
如果用公式拆解的话,可以理解为:模型的「想象力」=复杂语义理解+概念组合生成。
无论提示词中的元素多么复杂,通义万相都能准确呈现。
而涉及到多个不同元素时,它也能准确、有机地结合在一起,表现出超强的概念组合能力。
任何不可思议的画面,比如「猫变成少年」、「月球上建基地,遭遇洪水」,我们都可以充分放飞自己的想象力,要什么就有什么。
比如下面这只小兔子,穿着溜冰鞋在冰面上灵巧地滑行。

兔子生日宴上,小伙伴们一起为她庆生。

两位正在月球上搭建基地的宇航员,背后是浩瀚无垠的太空。

要说最惊艳的,便是下面这只黑猫幻化成冷峻少年的视频,一眼动漫成真。

在所有AI视频中,对运动的体现无疑都是最考验模型功力的一道题。
而通义万相,恰恰有着强大的运动生成能力。
它不仅支持复杂与大幅度的运动生成,还能非常写实地还原真实世界的物理规律。
比如在这个视频中,猎豹在狭窄的峡谷中奔跑,眼睛紧盯着前方的猎物。
猎豹四肢的动作、起伏的背脊、尾巴的甩动方向,都很符合自然规律。峡谷场景的一步步推进也很自然。

而这个滑雪爱好者从雪山上快速下滑的视频,无论是滑雪者四肢的动作、变换的重心,还是飞扬的雪粒、光影的变换,都十分自然,破绽极少。

通义万相的风格泛化能力极强,可以根据风格提示词生成响应的视频画面,带来影视级的画面质感和细节表现。
比如这段3D动画风格视频中,帅气的侠客兔子在森林中身披斗篷前进,质感细腻,达到了大片画质。

而这段勾线动画的视频,将法庭上穿着笔挺律师袍的狐狸律师呈现得活灵活现。

国漫3D风格的视频中,古装少女端坐在烛光中,夜色氤氲,巧笑倩兮。

下面这个视频是CG厚涂风格,描绘了女机械师在未来实验室中调试设备的场景。

此外就如上文所言,通义万相还会同时生成声音特效,后者是和视觉内容高度匹配的,这样就实现了音画同步,增强了视听一体的沉浸感。
上传一张在街道上空任意穿梭的飞碟的图片。
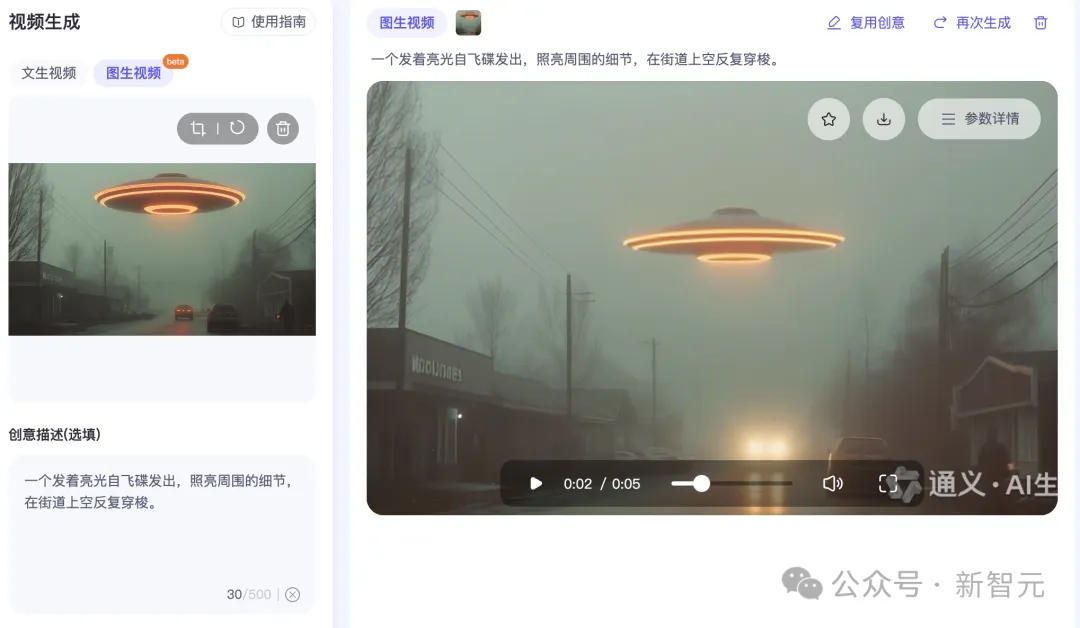
生成的视频中,还为飞碟配上了非常赛博的背景音,而且由近及远,给人一种真实的感觉。

这里,再用「一双似喜非喜含情目,态生两靥之愁,娇袭一身之病」复刻一下林黛玉多愁善感的神情。
视频中的女子很好还原了气郁体质,再加上配乐,又多了一分伤感。

要说通义万相的独特卖点,就是它的灵感扩写能力了。
在文生视频界面上点击「灵感扩写」,就能把简单的提示词扩写成忠于愿意的长提示词,从而大幅提升了生成效果。
比如使用这个prompt「白色狼群在冰川峡谷中穿行,夜晚月圆」,生成的视频是这样的。
仔细听,配音也颇有亮点:悠远、神秘,甚至带着一点凄婉。

点击「灵感扩写」,更长更丰富的prompt就生成了。
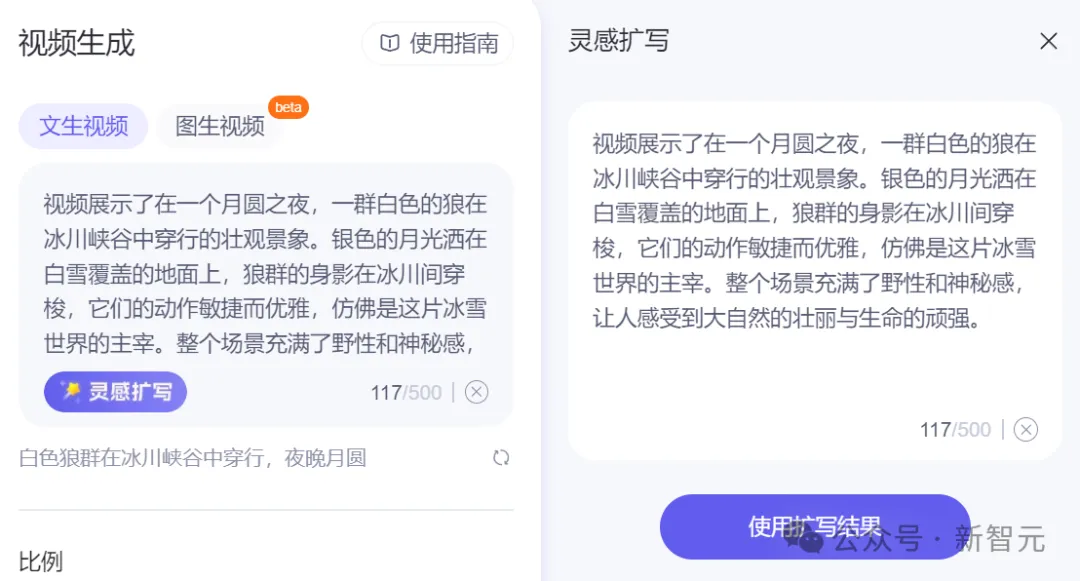
根据扩写后的prompt生成的视频,别具一番风味。

图生视频
通义万相的图生视频功能,也令人惊喜。
要知道,虽然图生视频没有文生视频那么难,但对一致性、想象力,要求也是很高的。
我们都会有这样的冲动:看到一张美图之后,忍不住会去想象,它动起来是什么样子?现在,通义万相的图生视频功能,完全能满足我们的愿望了。
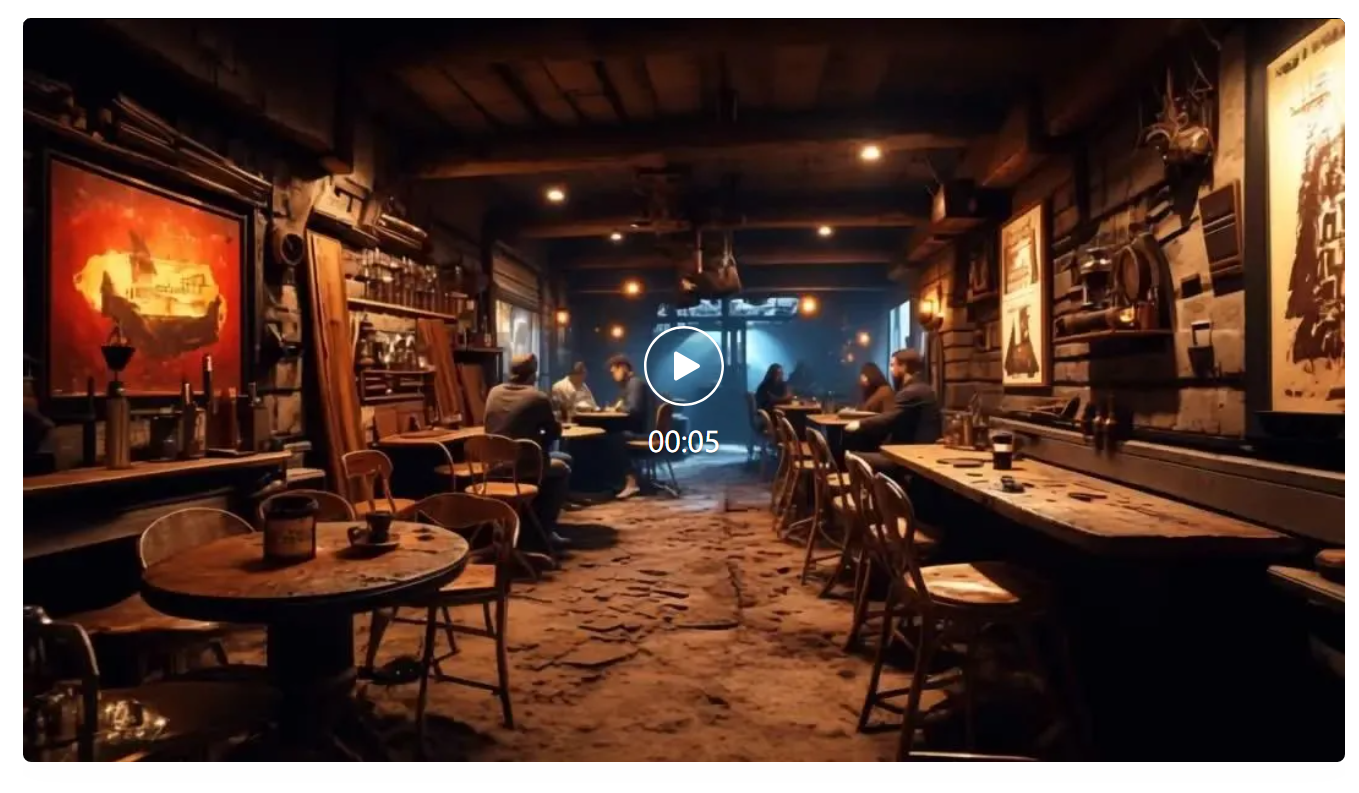
先由通义万相生成一张在有年代感的欧美餐厅中,几位顾客就餐的图片。

然后,将其上传,还可以补充一些创意描述。
通义万相生成的视频中,整个画面与原图高度一致,而且想象出一位男子迎面走向女子,和她交谈。
再上传一张梵高大师经典之作「星夜」,并输入创意性描述。

接下来,就能看到这幅画作活灵活现起来了。

小白兔坐在月饼上,周围的花瓣轻轻飘落。

图生视频一下,如梦似幻的场景立刻动了起来。

鲸鱼在空中漂浮的科幻场景,超现实主义的渔夫岛屿,荷塘锦鲤的水墨画,这些场景变成视频后,又达到另一番意境。


全自研视频生成LLM
通义万相AI视频能有如此惊奇的表现,深扒技术背后,竟是阿里团队全自研视觉生成大模型立功。
它在模型框架、训练数据、标注方式和产品设计上,具备了业界领先的生产能力。
值得一提的是,这款全新模型采用了Diffusion+Transformer架构。
Diffusion能够在图像、视频生成任务中,通过逐步图像降噪,让画面显现出来。
另外,Transformer的优势就在于,出色地处理序列数据,并有效地捕捉文本中上下文信息。
与其他模型不同的是,通义万相视觉模型采用了中英文双语标注,能够强化中文长文本理解,而且对中文内容和元素原生支持更好。
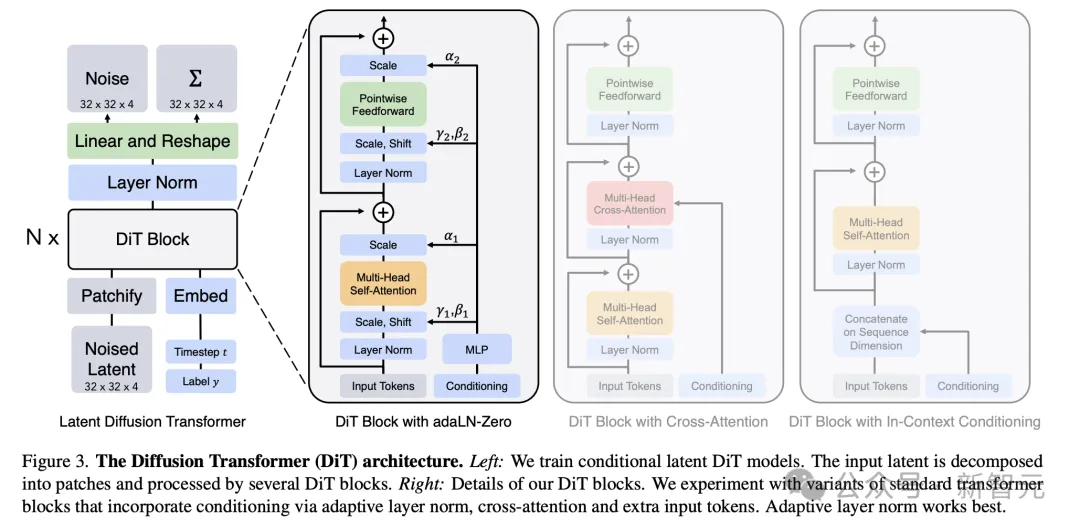
也就是说,DiT架构不仅能够处理静态图像,还能处理动态视频,为视觉内容创作带来革命性变革。
这种独特的生成方式,在计算效率上具有很强的优势。
通过逐步降噪来生成最终动画,不仅减少计算量,还提高了生成速度,使得通义万相在短时间内生成高质量视频。
而且,它能够精准构图和布局,从抽象艺术,到精细现实主义的各种风格,完全可以拿捏。
也正是这一架构的灵活性,能够让通义万相应用于多种场景。
不论是电商、广告创意,还是自媒体、影视/动画制作等领域,通义万相能够为创作者提供更多灵感来源。
比如,一辆跑车的宣传视频,在AI笔下,能够瞬间炫酷起来。

影视动画制作中的一些创意场景,AI的想象力更是无限的。

还等什么,无限次数免费续的通义万相,赶快去试用吧。
文章来源于“新智元”,作者“新智元”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
