# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
与此同时,可灵AI还引入了全新的“运动笔刷”功能。
9月19日,可灵AI迎来重磅升级,视频生成新增可灵1.5模型,在画质质量、动态质量、美学表现、运动合理性以及语义理解等方面均有显著提升。与此同时,可灵AI还引入了全新的“运动笔刷”功能,进一步提升视频生成的精准控制能力。
首先是基座模型再次升级,新增可灵1.5模型,支持在高品质模式下,直出1080p高清视频,挑战大屏清晰度与质感。与可灵 1.0 模型相比,1.5模型在画面质量、动态质量、文本响应度等方面有显著效果提升,其内部评测整体效果提升95%。
此前,可灵1.0模型在高品质模式可生成720p视频,本次升级后,1.5模型高品质模式可直接生成1080p高清视频。通过输入提示词“女孩看着车窗”,对比左右两个版本视频生成的效果,可以发现,可灵1.5新模型的画面质量提升显著:画面清晰度有直观可感,画面右侧的女孩面部细节更清晰丰富,车窗的水雾、整体光影表现等也都更加出色。同时,新模型下画面整体构图也进一步优化,画面更具美感。

在动态质量方面,新模型也有显著提升。例如,对比可灵AI此前火爆出圈的吃面案例,输入提示词“小男孩吃面”,右侧1.5模型生成的视频中,面条从被夹起到入口这一过程中,在弹性、垂坠感等方面有非常真实的物理表现,同时小男孩右手握住筷子和吃面时的咀嚼动作,也都较左侧1.0模型更加自然流畅,整体运动合理性大大增强。

在图生视频方面,可灵全新的1.5模型可以响应更复杂的文本描述要求。例如通过一张没有人物的食物照片和提示词“镜头拉远,一个小男孩走到桌前拿起勺子开始吃饭”。在生成的视频中,随着镜头的微微晃动,一个勺子“入场”,然后画面聚焦到握着勺子的小男孩,看他将一勺饭菜送到嘴里,勺子在碗里拨开饭粒的细节也都被细致地呈现了出来,显示出强大的图生视频理解能力。

本次升级,可灵AI还带来了强大的“运动笔刷”功能,大幅提升了图生视频时创作者对运动效果的控制能力。“运动笔刷”功能支持为图片中的元素(人或物体等)指定运动轨迹,用户只需将图片中需要控制运动方向的部分勾勒出来,然后画一个示意运动方向箭头,就可实现精准运动控制。该功能支持上传图片后最多为图中的 6 个元素(人或物体等)指定运动轨迹。此外,还可以为某些元素额外指定静止区域,让视频内容有更好的运动控制及运动表现。
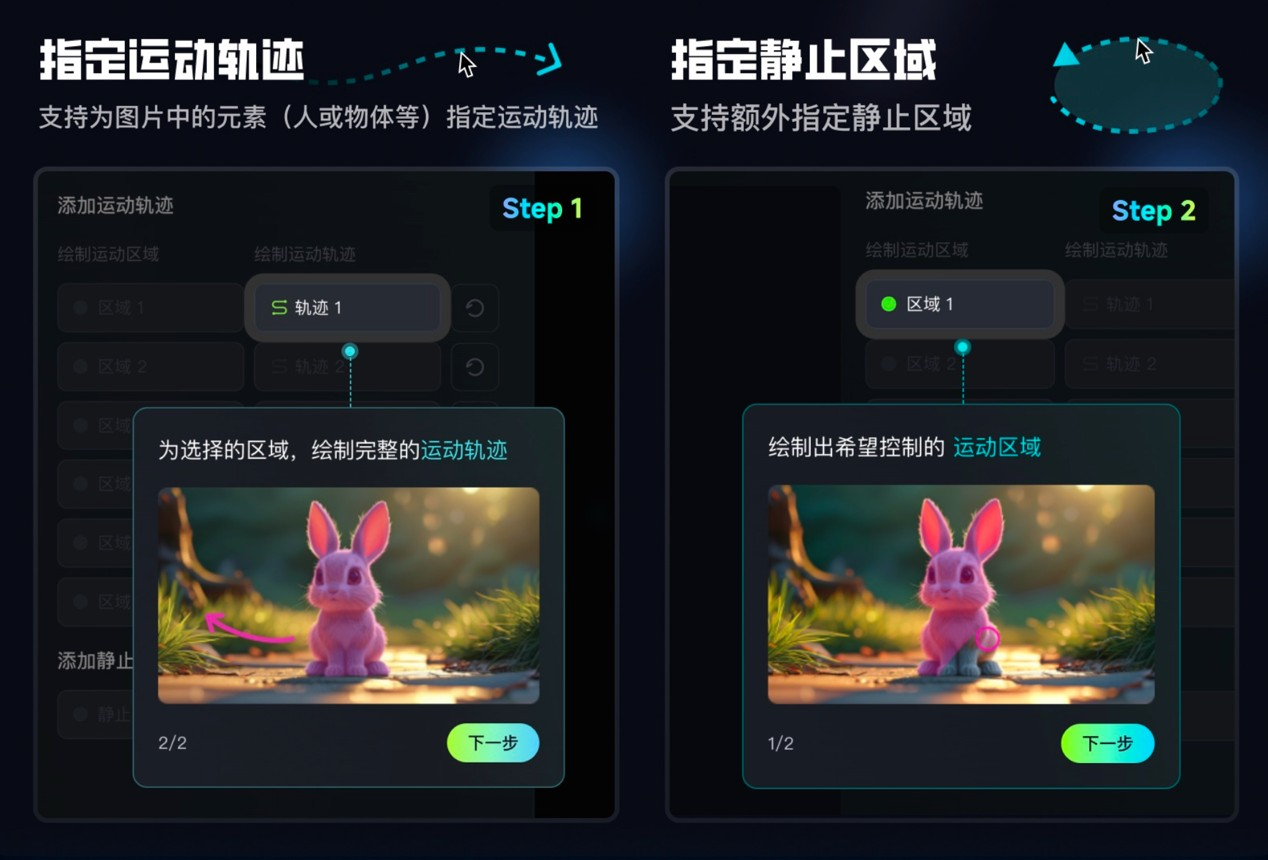
目前,横屏(16:9、4:3)、竖屏(9:16、3:4)、方屏(1:1)等多种尺寸格式的图片,都支持使用「运动笔刷」生成视频,生成视频时长为5秒。大量用户和媒体的评测显示,可灵AI的运动笔刷功能,在易用性、效果表现等方面均为业内领先。
实际上,可灵AI近期还进行了一系列其他功能升级,诸如支持一次性生成最多 4 条视频,方便创作者快速选取到最优生成结果;“图生视频”功能新增支持 10 秒时长并在标准模式下支持增加尾帧;“AI图片”功能支持“画质增强”。此外,官方还上线了使用指南,帮助用户更好地掌控可灵AI。
自今年6月发布以来,这已经是可灵AI累计第9次迭代升级。本次升级也将同步面向全球展开,今年7月,可灵AI宣布国际版1.0正式上线,正式面向全球用户开放,随后又推出了全球会员体系。目前,可灵AI目前已经累积了大量的国内外用户,快手高级副总裁、主站业务与社区科学线负责人盖坤此前在快手投资者日上披露,已有累计超260万人使用过可灵AI,并累计生成超2700万个视频、5300万张图片。
文章来自于“时氪分享”,作者“时氪分享”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
