# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
万众期待之下,可灵全新的1.5版本终于正式上线!
不仅接入了新一代模型,画质和动态质量都大幅提升,会员还能不加价升级1080P。
原有的模型也加入了新功能——运动笔刷,生成效果可控性又增强了。

作为视频生成模型界的当红炸子鸡,可灵的通告刚一发布,网友就开始晒作品了。
画面中,沙漏里的沙子自顾自地流淌,远处虚晃的男子轮廓逐渐清晰,凝望着沙漏,塑造出了提示词中的寂静感。

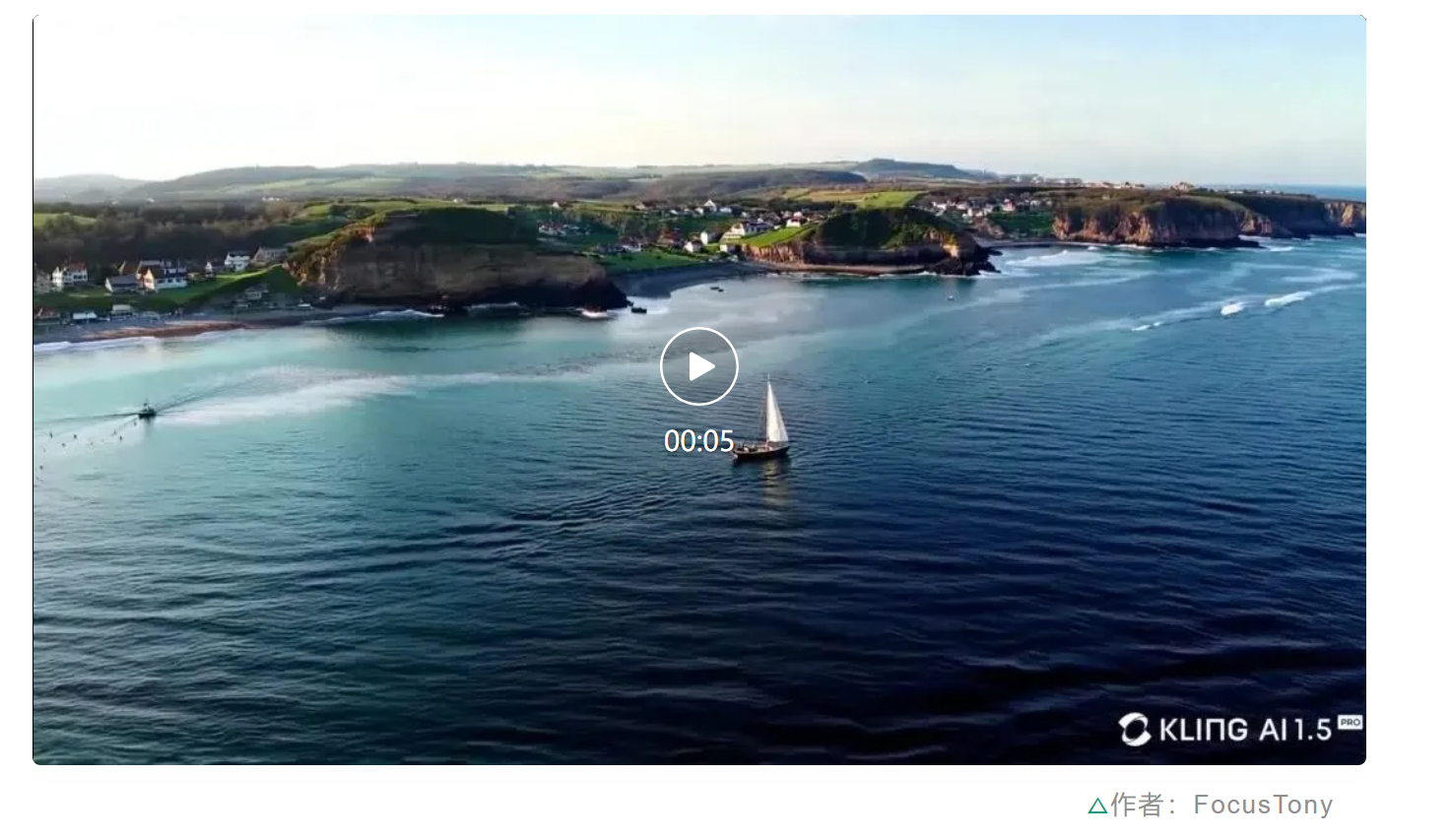
还有高空俯视下平静的海面,一艘渔船静静地浮在水面,视角也随着镜头自然转动。
有人打趣说,自己玩视频已经上瘾了,一天不玩就浑身难受。
而且网友们实在是太热情,很快就把服务器挤爆了,来晚的网友直接登不上去。
这样爆火的局面之下,官方也出来道歉,表示已经在扩容了。
对于可灵的这波致歉网友们还是比较宽容的,官方的及时声明也减轻了网友的忧虑。
此次更新上线了可灵大模型的1.5版本,最高分辨率从720P提升到了1080P。
会员用户可通过1.5版模型的高品质模式直接体验,而且价格(所需灵感值)和1.0的720P版本一致,提质不加价。
而在快手的内部评测中,1.5版本相比于1.0,整体效果提升了95%。
首先是画面质量,不仅清晰度有增加,构图也更加美观。来看官方给出的Demo:
一个中国女孩缓慢看向镜头,背景是模糊的城市夜景,主角被正前方的人工光源照亮,强调出面部轮廓,镜头缓慢地移动到主角的面部上。
先看1.0的生成效果,单看的话其实也说得过去:

但如果和1.5对比,差异也十分明显。

首先是光线,1.0模型生成的视频中人物面部比较暗淡;
1.5版本则把光聚焦在了人物的脸上,不仅突出主题,也符合了提示词中“主角被正前方的人工光源照亮”的要求。

还有在1.0版生成的视频中,镜头拉近时只有人物有相应的大小变化,背景却一动不动,不符合现实的空间规律;
而1.5版本中,背景也随着镜头的变化移动,使得整段视频更加自然。
不仅是清晰度,画面的动态质量也有提升,部分动作变得更加合理。
还是通过对比来感受,下面依次是1.0和1.5两个版本生成的吃面场景。
一个男人在大街上吃泡面。
仔细看1.0版生成的视频,这根面条吞到一半的时候就自己凭空消失了,而1.5版则没有这样的问题。

除了文生视频,在图生视频当中,1.5版本对附加的文本指令响应能力也更强了。
镜头拉远,一个小男孩走到桌前拿起勺子开始吃饭。

而且此处的对比更加显著,因为1.0版本的视频,可以说对文本根本就没响应。

相比之下,1.5版进步相当明显。

在1.5模型上线的同时,原来的1.0版不仅没停止服务,还加入了新的运动笔刷功能。
这个运动笔刷可以一次性控制图片中6个物体的轨迹,还能动静结合,指定固定不变的区域。
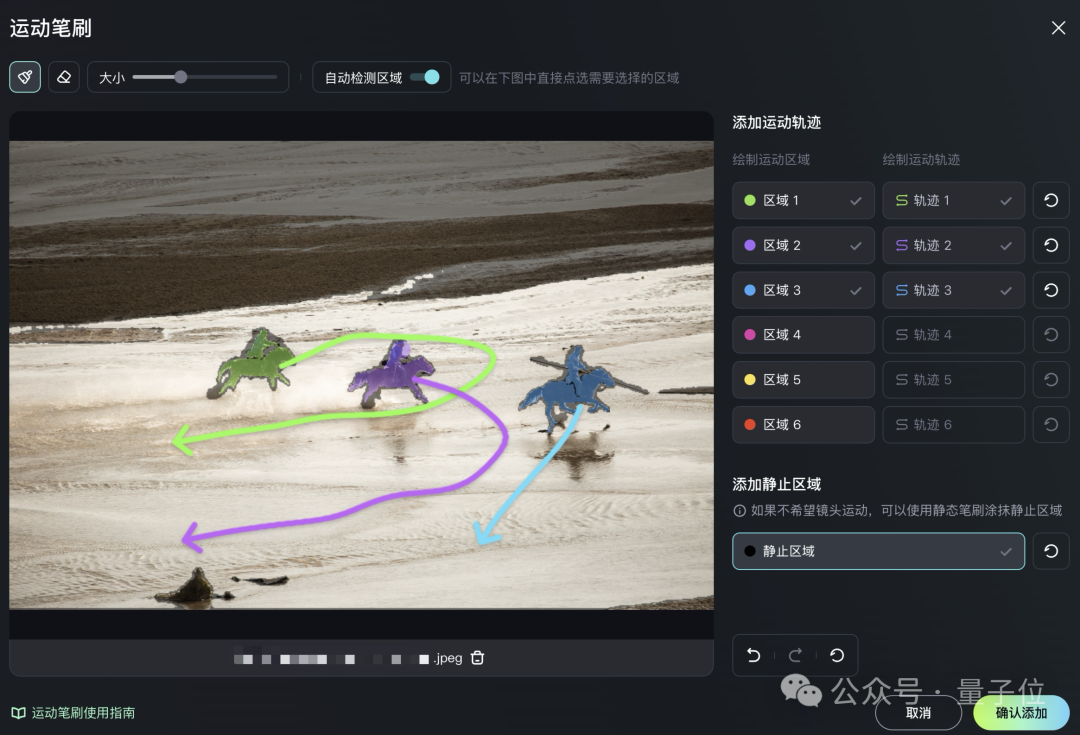
在可灵的作品当中,三匹马遵循了我们绘制的这三条轨迹,该有的转身动作也都体现了。
另外背景与物体的交互体现得比较合理,上方划定的精致区域也被遵守。
当然由于动作幅度较大的原因,对于马和人的细节刻画还有不小的进步空间。

再来看看网友的作品。
相比我们的测试,这里的动作幅度小了许多,因此只要一点一画,画面中的人物就能按照指定的轨迹运动,当然相应的腿脚动作也会自动适应。
还有一些细节上的更新,例如可以一次性生成最多4个视频,也算是减少了“抽卡”时的重复工作(手动狗头)。
另外,原先只能生成5秒的图生视频,现在可以支持10秒了;标准模式专属的尾帧控制,也扩展到了高性能模式。
以上就是可灵这次更新的全部内容,感兴趣的话就去体验一下吧~
文章来源于“量子位”,作者“克雷西”




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


