# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。
该团队将模型架构调整为 Mamba 和 Transformer 块的混合体,在数据构建中考虑多个图像之间的时间和空间依赖性,并采用渐进式训练策略。提出了首个混合架构多模态大语言模型 LongLLaVA,在效率和性能之间实现了更好的平衡。

LongLLaVA 不仅在各种基准测试中取得了有竞争力的结果,还保持了高吞吐量和低显存消耗,其可以在单个 A100 80GB GPU 上处理近千张图像,展现出了广阔的应用前景。

多模态大语言模型(MLLMs)的快速进步展示了它们在各个应用领域中的显著能力。然而,多图像理解场景仍然是一个重要但尚未充分探索的方面。特别是,将 MLLMs 的应用场景扩展到理解更长的视频、更高分辨率的图像以及基于更多历史信息的决策,对于提升用户体验和进一步拓展 MLLMs 的应用范围至关重要。
然而,将 MLLM 的上下文长度扩展以提高其可用性,面临着处理更多图像时性能下降和计算成本高昂的挑战。一些研究专注于构造包含多个图像的长上下文训练数据,以增强性能。其他研究探索了创新性的训练策略,以减轻性能下降。关于高计算成本的问题,LongVILA 通过降低通信成本在提高多节点效率方面取得了进展。然而,在管理更长的上下文时,加速计算这个问题本身仍有待解决。
为了解决上述挑战,该研究提出了 LongLLaVA 系统解决方案,采用混合架构进行加速。该解决方案在三个维度上进行了全面优化:多模态架构、数据构建和训练策略。
实验结果表明,LongLLaVA 在高效理解多模态长上下文方面表现卓越。它在VNBench的检索、计数和排序任务中领先,并在单张 80GB GPU 上对 1000 张图像进行大海捞针评估时达到了近 100% 的准确率。从保证研究可复现和促进社区发展出发,团队将开源所有与 LongLLaVA 相关的模型、代码和数据集。
为了解决上述挑战并提高模型对长文本和多图像场景的适应性,团队从三个角度进行了改进:多模态模型架构,数据构造和训练策略。
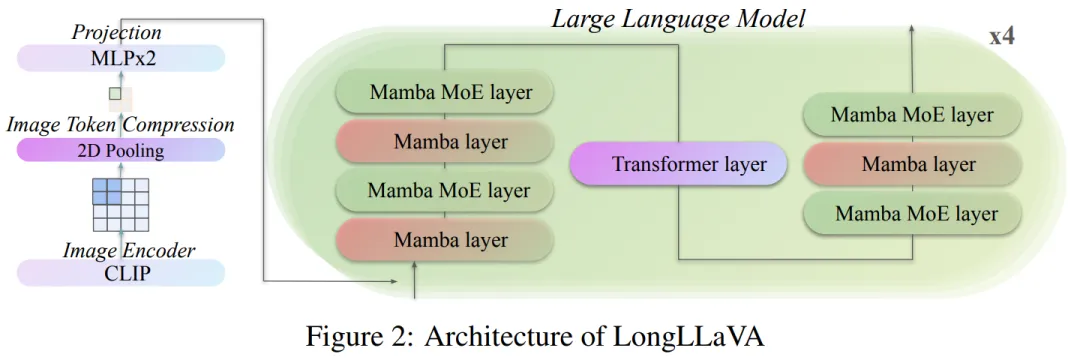
2.1 多模态架构
LongLLaVA 基于 LLaVA 的三个核心组件:视觉编码器、 映射器 和大语言模型。
视觉信息处理。团队使用 CLIP 作为视觉编码器来编码视觉信息,并采用两层 MLP 作为映射器,将视觉特征映射到适合 LLM 的文本嵌入空间。在映射之前,应用2D池化,有效地节省了训练和推理时间,同时保持了图像块之间的基本空间关系。
混合 LLM 架构。LongLLaVA 采用了一种混合 LLM 架构,将 Transformer 和 Mamba 层以 1:7 的比例集成,如图 2 所示。在每一层中还采用了混合专家(MoE)方法,使用 16 个专家,并为每个 Token 选择前两个专家。在层之间使用 RMSNorm 来增强归一化,但省略了位置嵌入。该模型集成了分组 Query 注意力(GQA)和 SwiGLU 激活函数,与其他大型语言模型相似。模型的总体参数数量为 530 亿,推理过程中的激活参数总数为 130 亿。

2.2 数据处理协议
为确保模型在多图像场景中有效地区分图像之间的时序和空间依赖关系,并在各种任务中表现良好,团队细致地区分了不同场景下的特殊字符。如图 3 所示,这些特殊字符全面处理了不同情境下图像之间的各种关系,从而增强了模型对不同任务的适应性。
2.3 训练策略
团队逐步实现单模态和多模态的适配,将预训练语言模型转变为多模态长上下文模型。
纯文本指令微调。首先提升预训练语言模型在纯文本场景中遵循不同长度指令的能力。这是通过使用包含来自 Evol-instruct-GPT4、WildChat 和 LongAlign 的 278k 条纯文本条目的数据集实现的。
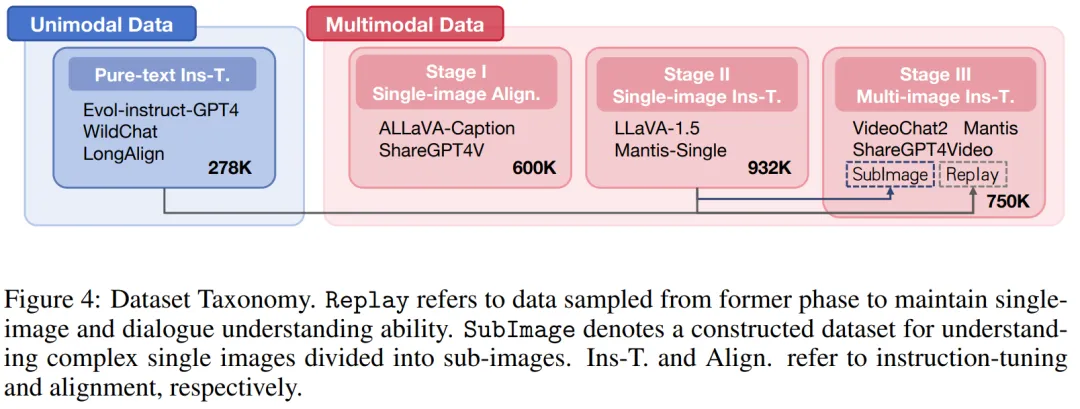
在多模态自适应方面,在 LLaVA 中 “单图像对齐” 和 “单图像指令微调” 阶段之后,团队引入了 “多图像指令微调” 阶段,逐步增强模型的多模态长上下文能力。采用渐进式训练不仅是为了更好地控制变量,也是为了增加模型的可重用性。具体的数据集使用情况如图 4 所示。
第一阶段:单图像对齐。这一阶段是为了将视觉模态特征与文本模态进行对齐。团队使用了 ALLaVA-Caption 和 ShareGPT4V 等数据集,这些数据集包含大约 600K 个高质量的图像 - 字幕对。在此阶段,仅训练映射器,同时冻结视觉编码器和 LLM 的参数。
第二阶段:单图像指令微调。这个阶段的目的是赋予模型多模态指令遵循能力。团队使用了 LLaVA-1.5 和 Manti-Single 等数据集,总共有约 932K 个高质量的问答对。在此过程中,只冻结了视觉编码器,而映射器和 LLM 部分进行训练。
第三阶段:多图像指令微调。在这一阶段,模型被训练以在多模态长文本场景中遵循指令。团队分别从 Mantis、VideoChat2 和 ShareGPT4Video 中采样 200K、200K 和 50K 数据项。为了保留模型的单图像理解和纯文本对话能力,团队将来自单图像指令微调和纯文本指令微调阶段的额外 200K 和 50K 数据项作为 Replay 部分。此外,为了提高模型解释复杂单图像(分割成多个子图像)的能力,团队从单图像指令微调阶段采样 50K 条数据,进行填充和分割,将原始图像分割成尺寸为 336x336 的子图像作为 SubImage 部分。
如表 2 所示,LongLLaVA 在 MileBench 上表现出色,甚至超过了闭源模型Claude-3-Opus,尤其在检索任务方面表现出色。突显其在处理多图像任务方面的强大能力。
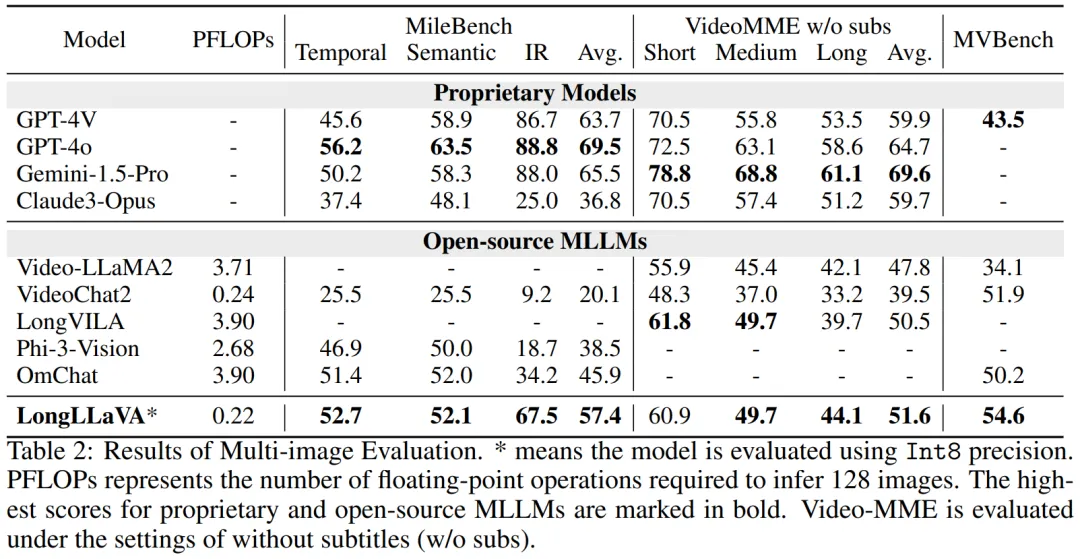
LongLLaVA 在涉及中等至长视频的任务中表现出色,超越了传统的视频模型,如 Video-LLaMA2 和 VideoChat2。在取得了这些令人印象深刻结果的同时,LongLLaVA 的 FLOPs 比其他模型少一个数量级。
3.2 长上下文大型语言模型的诊断评估
考虑到以前的评估不能充分捕捉 MLLM 在长语境下的能力,团队采用了一个新的诊断评估集 VNBench,以进一步分析模型在长语境下的原子能力。VNBench 是一个基于合成视频生成的长上下文诊断任务框架,包括检索、排序和计数等任务。
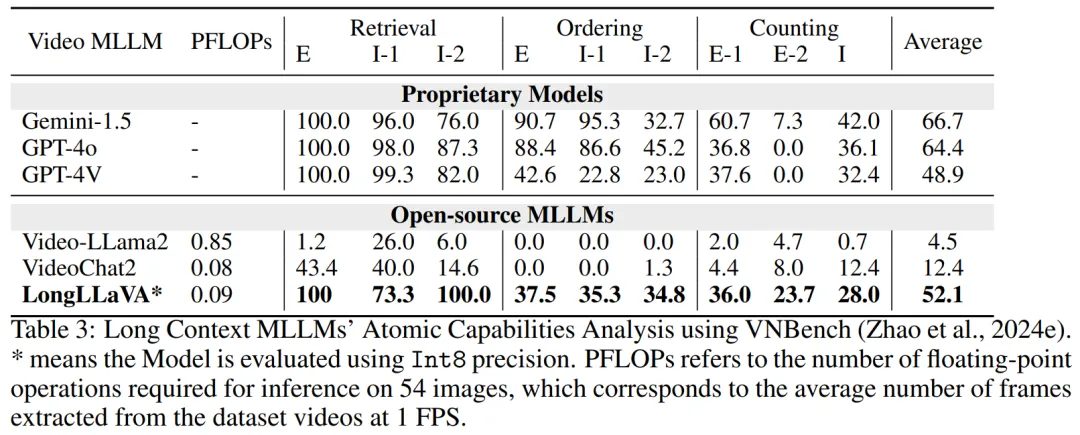
结果显示如表 3 所示,LongLLaVA 在跨语境检索、排序和技术能力等任务中的表现与领先的闭源模型相当,甚至在某些方面超过了 GPT-4V。在开源模型中,LongLLaVA 也展现出其卓越的性能。展示了 LongLLaVA 在管理和理解长上下文方面的先进能力。
3.3 消融实验
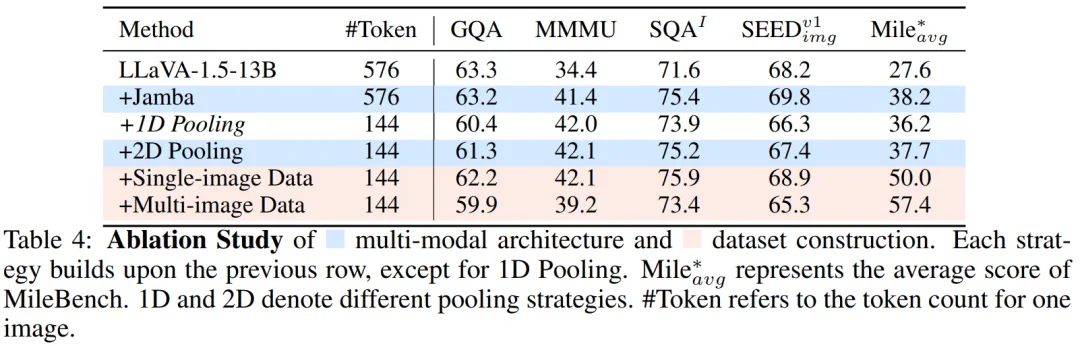
表 4 中显示,使用具有相同数据的混合 LLM 架构,在评估集中都观察到了显著的改进,证明了其在多模态场景中的潜力。对于 Token 压缩,选择了 2D 池化,这显著减少了计算负载,同时将性能下降控制在可接受范围内。与 1D 池化相比,2D 池化方法得到更好的结果。在数据构建方面,在训练团队的单图像数据后,模型在 SEEDBench 上的准确率提高了 1.5%,在 MileBench 上提高了 12.3%。随后的多图像训练使得 MileBench 上的准确率进一步提高了 7.4%,验证了数据集构建的有效性。
为了解 LongLLaVA 的内部工作原理和跨模态长文本处理能力,该团队进行了进一步分析。
4.1 关于混合架构的动机
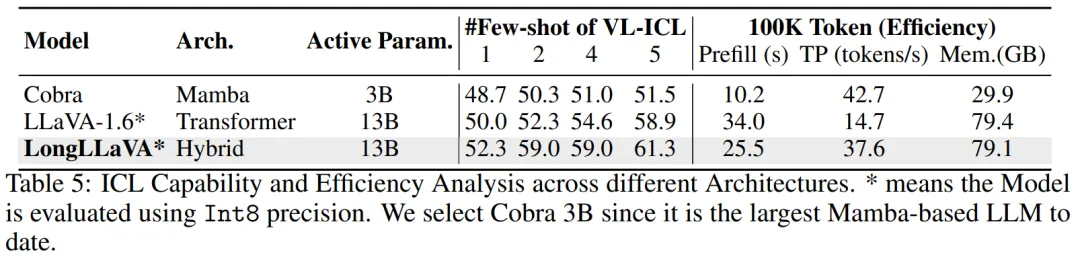
团队探讨了不同架构在 ICL 能力和推理效率方面的优缺点,强调了混合架构的平衡优势。
ICL 分析。团队评估了在 VL-ICL 基准测试中对多模态情境学习中匹配图像任务的性能。该任务的输入包含一个图像对,输出表示是否存在特定的关系。MLLM 需要从示例中学习关系。如表 5 所示,混合架构和 Transformer 架构随着示例数量的增加表现出快速的性能提升,而 Mamba 架构的提升较少,证实了其在情境学习方面的不足。
效率分析。团队关注三个方面:预填充时间(首次推理延迟)、吞吐量(每秒生成的下一个 Token 数)和内存使用。团队将输入文本长度控制在 100K,并测量生成 1 个 Token 和 1000 个 Token 的输出所需的时间和最大内存使用。吞吐量计算为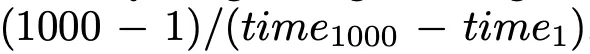 。为了更好地模拟实际应用场景,使用 vLLM 框架和 Int8 量化评估了 Transformer 和混合架构。如表 5 所示,Mamba 架构具有最快的预填充时间,最高的吞吐量。与具有相似推理参数的 Transformer 架构相比,混合架构实现了 2.5 倍的吞吐量,75% 的预填充时间,并减少了内存使用。
。为了更好地模拟实际应用场景,使用 vLLM 框架和 Int8 量化评估了 Transformer 和混合架构。如表 5 所示,Mamba 架构具有最快的预填充时间,最高的吞吐量。与具有相似推理参数的 Transformer 架构相比,混合架构实现了 2.5 倍的吞吐量,75% 的预填充时间,并减少了内存使用。
4.2 图像数量的缩放定律
随着可处理图像数量的增加,模型能够支持更多图像块以进行高分辨率图像理解,以及使用更多视频帧进行视频理解。为了探索增加子图像和视频帧数量的影响,团队分别在 V* Bench 和 Video-MME 基准测试上评估了 LongLLaVA。
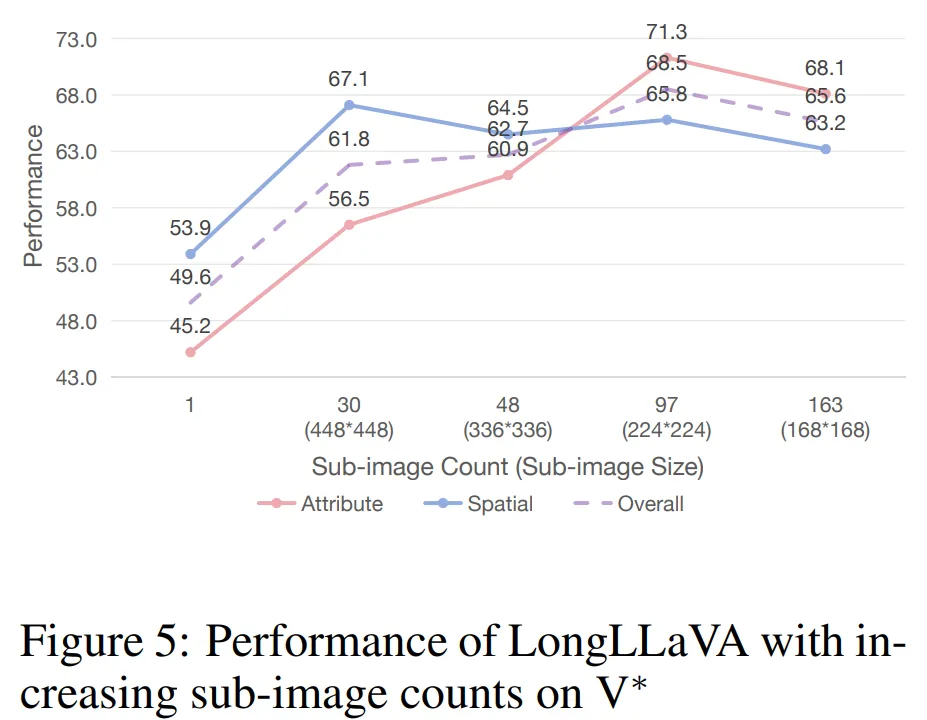
增加子图像数量。V* Bench 评估了一个模型在大型图像中定位小目标的能力。如图 5 所示,最初增加子图像的数量显著提高了模型性能,表明模型对图像细节的理解更好。然而,团队也发现,进一步增加子图像的数量略微降低了性能,这表明过多的子图像可能会干扰在此任务上的性能。
增加帧数规模。视频多模态编码器是一个测试模型从视频中提取信息能力的基准。从图 6 中可以看到,随着采样帧数的增加,模型在基准测试中的性能显著提高,当提取 256 帧时达到峰值。这表明模型能够有效地理解和利用额外采样帧中包含的信息,以提供更好的响应。
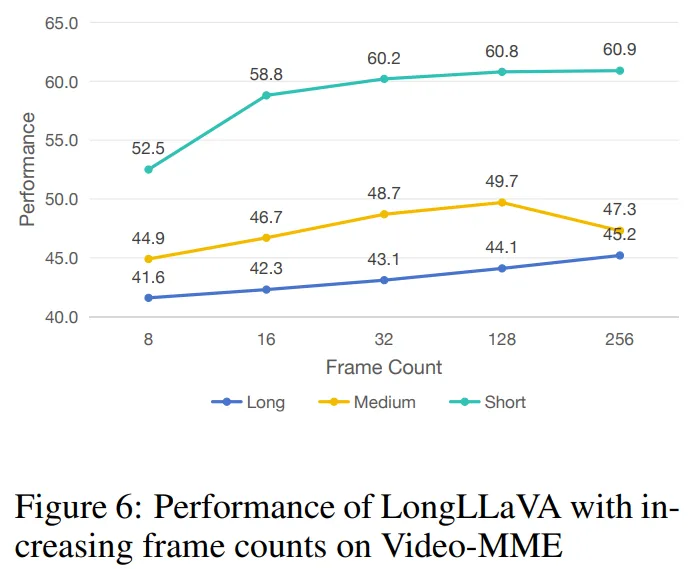
5. 进一步将图像数量扩大到 1000
利用 LongVA 中提出的 V-NIAH 评估框架,团队进行了 “大海捞针” 测试来评估模型性能。考虑到模型的训练序列长度限制为 40,960 个 token,采用 token 池化技术将原始 token 数量从 144 个减少到 36 个。这种调整能够高效地从大量数据集中检索相关信息。如图 7 所示,模型在 1000 张图像集上实现了近 100% 的检索准确率,而无需额外的训练。
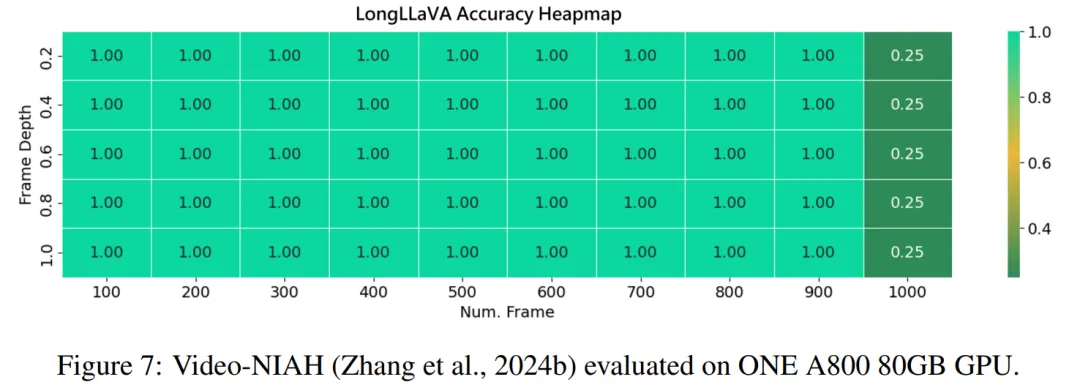
然而,当增加测试图像数量超过 1,000 张时,团队观察到检索准确率下降。这种性能下降可能是因为超出了模型的训练序列长度,这可能会影响其保持更多图像准确性的能力。在未来的工作中团队将延长训练序列长度至 140,000 Token,即 LongLLaVA 进行单卡推理的极限长度,以进一步释放模型潜力。
LongLLaVA(长上下文大型语言和视觉助手)这一创新性混合架构模型,在长上下文多模态理解方面表现出色。该模型集成了 Mamba 和 Transformer 模块,利用多个图像之间的时空依赖性构建数据,并采用渐进式训练策略。
LongLLaVA 在各种基准测试中表现出竞争性的性能,同时确保了效率,为长上下文多模态大型语言模型(MLLMs)设定了新的标准。
文章来自于“机器之心”,作者“王熙栋,宋定杰,陈舒年,张辰,王本友”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
