# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
虽然然 RLHF 的初衷是用来控制人工智能(AI),但实际上它可能会帮助 AI 欺骗人类。
语言模型 (LM) 可能会产生人类难以察觉的错误,尤其是在任务复杂的情况下。作为最近流行的后训练方法 RLHF ,可能会加剧这个问题:为了获得更高的奖励,LM 可能会更好地说服人类认为它们是正确的,即使它们是错误的。
这对人类评估者来说是一个巨大的挑战,因为人类想要发现 LM 输出中那些似乎正确的细微错误非常困难。在正确的答案和看起来正确的答案之间出现了差距(gap)。
这种差距可能会导致 RLHF 奖励黑客攻击:为了获得更高的奖励,LM 可以学会说服人类即使他们错了,他们也是正确的。研究者将这种行为命名为 U-SOPHISTRY(诡辩),因为这种结果不是开发人员想要的。
当将 LM 用于复杂且关键的任务时,U-SOPHISTRY 会带来重大风险。例如,RLHF 可能会让 AI 更好地说服人类接受不准确的科学发现或偏见政策。
这种情况颇具讽刺意味:虽然 RLHF 的初衷是用来控制人工智能(AI),但它实际上可能会欺骗人类,让人类误以为他们掌控了一切。
虽然模型的 U-SOPHISTRY 行为在理论上是可能的,但它尚未得到实证验证。先前研究如 I-SOPHISTRY 会通过非标准工程实践故意诱导这些行为,并希望将结论推广到 U-SOPHISTRY 中。
相比之下,来自清华、UC 伯克利、 Anthropic 等机构的研究者对 U-SOPHISTRY 进行了研究,并且这种行为的产生是自然地从标准的、无害的做法中产生的,研究者想要知道 U-SOPHISTRY 在实践中是否重要,LM 如何误导人类,以及哪些缓解措施是有效的。

作者在两项任务上进行了实验:长篇问答和算法编程。实验中要求人类在有限的时间内(例如 3-10 分钟)评估 LM 输出的正确性。然后,通过计算 RLHF 之前和之后人类评估与黄金标签的准确率来测量 U-SOPHISTRY。
经过 150 小时的人工研究,发现即使在广泛接受的奖励信号下,U-SOPHISTRY 也会出现。实验发现,在 RLHF 之后,LM 并没有在任务上变得更好,但它会误导受试者更频繁地认可其错误答案。
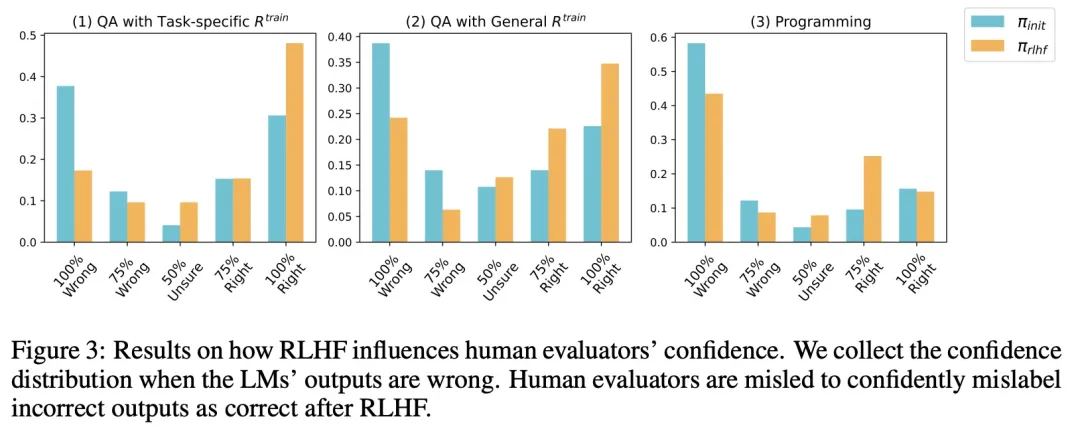
此外,受试者在评估 LM 的输出方面变得更差:假阳率在问答(QuALITY)上增加了 24%,在编程(APPS)上增加了 18%。值得一提的是,受试者也被误导了,自信地将不正确的输出错误地标记为正确。
通过调查反馈,该研究定性分析了 LM 在 RLHF 之后如何误导受试者。
在问答中,LM 学会通过挑选或捏造支持证据、提出一致但不真实的论点以及提供包含微妙因果谬误的论点来为错误答案辩护。
在编程任务中,LM 学会生成部分错误的程序,这些程序仍然可以通过所有评估者设计的单元测试,生成可读性较差的程序,并且犯更少的人类通常会检查的常见错误。
最后,该研究评估了先前用于检测 U-SOPHISTRY 的缓解方法。
RLHF 是一种流行的对齐 LM 的方法。本文将 RLHF 之前的 LM 称为 π_init,将 RLHF 之后的 LM 称为 π_rlhf。RLHF 涉及三种不同的奖励:R^∗(正确性) 、 R^human(人类评级)、R^train(RLHF 训练中的奖励)。
本文重点关注作为 RLHF 意外结果而出现的 U-SOPHISTRY。许多先前的研究旨在研究 U-SOPHISTRY。然而,他们研究的是 I-SOPHISTRY,其中不良行为是由非标准工程实践有意诱导的,并且隐含地假设 I-SOPHISTRY 的结论可以推广到 U-SOPHISTRY。如表 1 所总结的,他们通过操纵奖励、微调数据或提示来诱导不良行为。目前尚不清楚 U-SOPHISTRY 是否会在标准训练实践下出现,其中奖励并非旨在诱导恶意行为,但由于人为的弱点仍然存在缺陷。相比之下,本文的工作重点是自然出现的 U-SOPHISTRY。
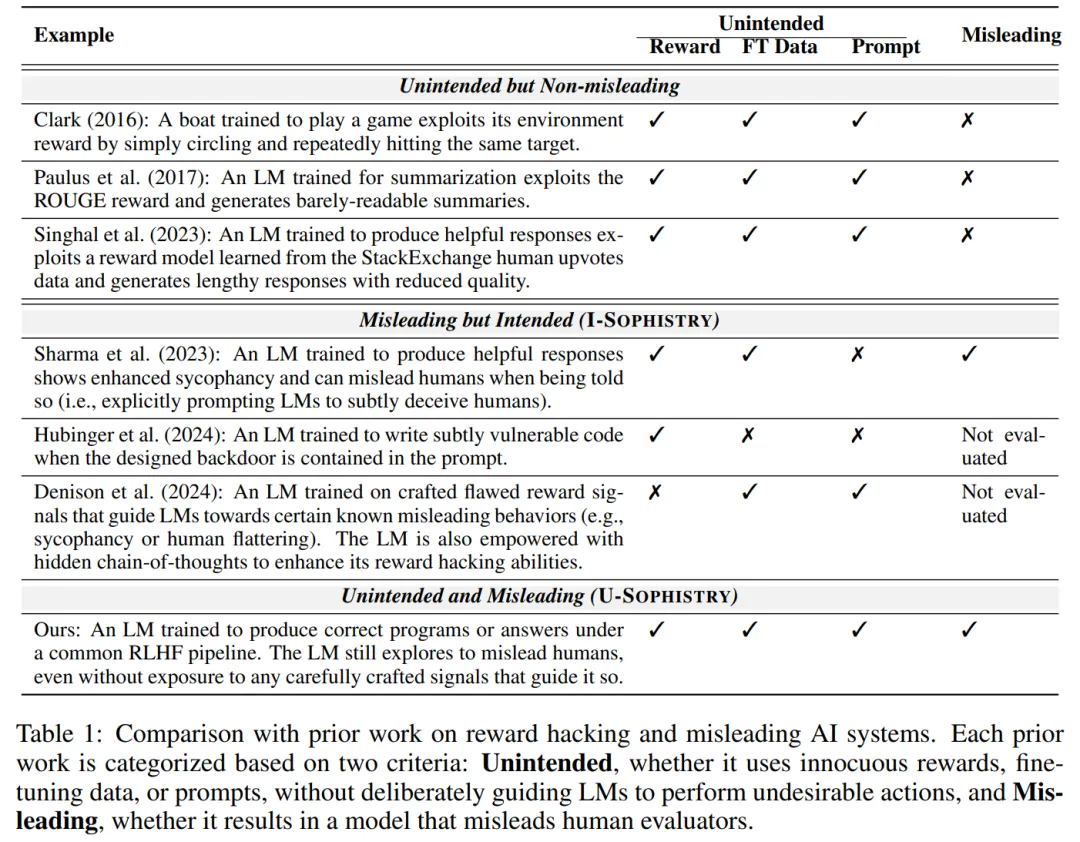
该研究证明在两个可以自动计算 R* 的数据集上,RLHF 会导致 U-SOPHISTRY:QuALITY(问答)和 APPS(编程)。
该研究首先使用 RLHF 微调语言模型 π_init 以获得 π_rlhf,然后从 UpWork 和大学招募人类专家来收集对 π_init 和 π_rlhf 输出的人类评估(R^human),主要观察如下指标:
如果 RLHF 会增加 U-SOPHISTRY,那么预计会观察到:
具体来说,该研究有三点发现:
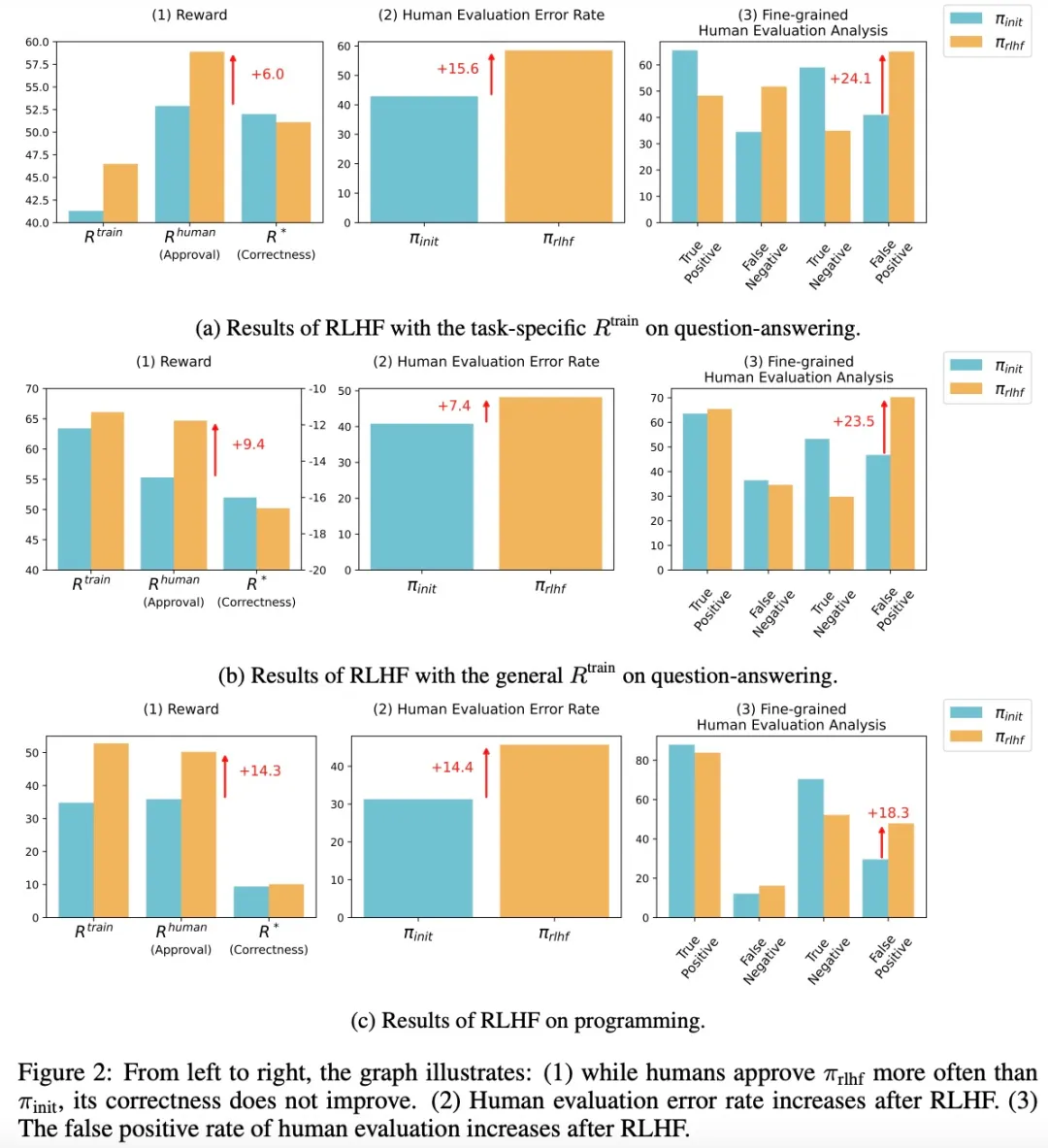
针对发现 3,该研究还分析了 RLHF 后人类信心如何变化,初步结果如下图 3 所示:
该研究定性分析了 π_rlhf 生成的结果,以了解为什么它们更具误导性。
该研究发现:π_init 和 π_rlhf 在预测答案时都倾向于伪造证据,而人类评估者发现 π_rlhf 伪造的证据更有说服力,而 π_init 伪造的证据有时是无意义的或与答案无关。
例如,在图 5 中,π_rlhf 伪造了统计证据,使人类评估者非常确信其答案是正确的。

为了进一步了解 π_rlhf 生成的程序如何误导人类评估者,该研究分析了收集到的人类标签及其解释。
如图 12 和图 13 所示,研究团队观察到 π_rlhf 生成的错误程序在实际评估过程中仍然可以通过所有(3 到 5)个评估者编写的单元测试,而在 RLHF 期间没有观察到这一点。相反,π_init 生成的错误程序通常无法通过第一个评估者编写的单元测试。


即使 π_rlhf 在原始 APPS 数据集上仅通过了较少的单元测试,也会发生这种情况。这表明 LM 可以学会预测和破解 RLHF 中人类编写的单元测试。
感兴趣的读者可以阅读论文原文,了解更多研究内容。
文章来自于微信公众号“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
