# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLaMA-Omni能够接收语音指令,同步生成文本和语音响应,响应延迟低至 226ms,低于 GPT-4o 的平均音频响应延迟 320ms。
以 ChatGPT 为代表的大型语言模型(LLM)已成为强大的通用任务解决器,但大多数 LLM 仅支持基于文本的交互,这限制了它们在不适合文本输入输出的场景中的应用。GPT-4o 的出现使得通过语音与 LLM 进行交互成为可能。然而,开源社区对于构建此类基于 LLM 的语音交互模型仍然缺乏探索。
实现与 LLM 进行语音交互最简单的方法是采用基于自动语音识别(ASR)和语音合成(TTS)模型的级联系统,其中 ASR 模型将用户的语音指令转录为文本, TTS 模型将 LLM 的响应合成为语音。
然而,由于级联系统依次输出转录文本、文本响应和语音响应,整个系统往往具有较高的延迟。相比之下,一些多模态语音 - 语言模型将语音离散化为 token 并扩展 LLM 的词表以支持语音输入和输出。这种语音 - 语言模型理论上可以直接从语音指令生成语音响应,无需生成中间文本,从而实现极低的响应延迟。然而,在实践中,由于涉及语音之间复杂的映射,直接语音到语音的生成通常极具挑战性。
为了解决上述问题,来自中国科学院计算技术研究所、中国科学院大学的研究者提出了一种新型模型架构 ——LLaMA-Omni,它可以实现与 LLM 的低延迟、高质量交互。

LLaMA-Omni 由语音编码器、语音适配器、LLM 和流式语音解码器组成。用户的语音指令由语音编码器进行编码,经过语音适配器后输入到 LLM。LLM 直接从语音指令中解码文本响应,无需首先将语音转录为文本。语音解码器是一个非自回归(NAR)流式 Transformer,它将 LLM 的输出表示作为输入,并使用连接时序分类(Connectionist Temporal Classification, CTC)来预测与语音响应相对应的离散单元序列。
在推理过程中,当 LLM 自回归生成文本响应时,语音解码器同步生成相应的离散单元。为了更好地契合语音交互场景的特点,该研究通过重写现有的文本指令数据并进行语音合成,构建了名为 InstructS2S-200K 的数据集。实验结果表明,LLaMA-Omni 可以同步生成高质量的文本和语音响应,延迟低至 226ms。
此外,与 SpeechGPT 等语音 - 语言模型相比,LLaMA-Omni 显著减少了所需的训练数据和计算资源,从而能够基于最新的 LLM 高效开发强大的语音交互模型。
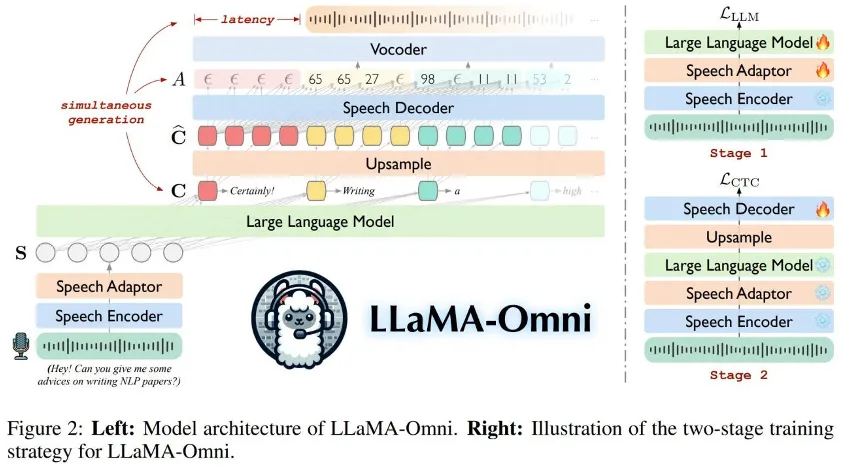
如图 2 所示,LLaMA-Omni 由语音编码器、语音适配器、LLM 和语音解码器组成,其中将用户的语音指令、文本响应和语音响应分别表示为 X^S、Y^T 和 Y^S。
该研究使用 Whisper-large-v3 (Radford et al., 2023)的编码器作为语音编码器 E。Whisper 是一种在大量音频数据上训练的通用语音识别模型,其编码器能够从语音中提取有意义的表征。
具体来说,对于用户的语音指令 X^S,编码后的语音表征由 H = ε(X^S) 给出,其中 H = [h_1, ..., h_N ] 是长度为 N 的语音表征序列,语音编码器的参数在整个训练过程中都被冻结。
为了使 LLM 能够理解输入语音,LLaMA-Omni 结合了一个可训练的语音适配器 A,它将语音表征映射到 LLM 的嵌入空间中。语音适配器首先对语音表征 H 进行下采样以减少序列长度。具体来说,每 k 个连续帧沿特征维度拼接:
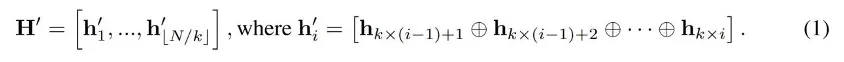
接下来,H′ 通过具有 ReLU 激活的 2 层感知器,得到最终的语音表征 S:

该研究使用 Llama-3.1-8B-Instruct(Dubey et al., 2024)作为 LLM M,它是目前 SOTA 开源 LLM,具有很强的推理能力,并且与人类偏好进行了对齐。prompt 模板 P (・) 如图 3 所示。

将语音表征序列 S 填充到对应位置,然后将整个序列 P (S) 输入到 LLM 中。最后,LLM 直接根据语音指令自回归生成文本响应 Y^T = [y^T_1 , ..., y^T_M],并使用交叉熵损失进行训练:
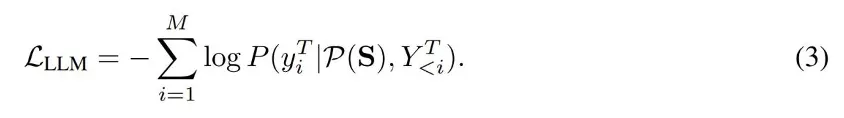
为了与文本响应同步生成语音响应,LLaMA-Omni 在 LLM 之后添加了一个流式语音解码器 D。它由几个标准 Transformer 层组成,其架构与 LLaMA (Dubey et al., 2024) 相同,每个层都包含一个因果自注意力模块和一个前馈网络。
语音解码器以非自回归方式运行,将 LLM 的输出表示经过上采样后作为输入,并生成与语音响应相对应的离散单元序列。
如图 2 所示,LLaMA-Omni 采用两阶段训练策略。第一阶段训练模型直接根据语音指令生成文本响应的能力。具体来说,语音编码器被冻结,语音适配器和 LLM 使用公式 (3) 中的目标 L_LLM 进行训练。语音解码器在此阶段不参与训练。第二阶段训练模型来生成语音响应。在此阶段,语音编码器、语音适配器和 LLM 都被冻结,仅使用公式 (5) 中的目标 L_CTC 来训练语音解码器。
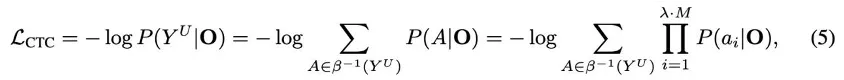
在推理过程中,LLM 根据语音指令自回归生成文本响应。同时,由于语音解码器使用因果注意力,一旦 LLM 生成文本响应前缀![]() ,相应的输出状态
,相应的输出状态![]() 就可以被输入到语音解码器中以生成部分对齐
就可以被输入到语音解码器中以生成部分对齐![]() ,进而产生与生成的文本前缀相对应的离散单元。
,进而产生与生成的文本前缀相对应的离散单元。
为了进一步实现语音波形的流式合成,当生成的离散单元数量达到预定义的块大小 Ω 时,即将该离散单元片段输入到声码器中以合成语音片段,然后立即播放给用户。因此,用户无需等待生成完整的文本响应即可开始收听语音响应,从而确保低响应延迟。算法 1 描述了上述过程。

为了训练 LLaMA-Omni,需要构建三元组数据:语音指令,文本响应,语音响应。
对于语音指令数据而言,包含三步:指令重写、响应生成、语音合成。
对于基础文本指令,作者从 Alpaca 数据集中收集了大约 50K 条指令,该数据集涵盖了广泛的主题。此外,作者从 UltraChat 数据集中收集了大约 150K 条指令,该数据集主要由有关世界的问题组成。值得注意的是,UltraChat 是一个大规模多轮对话数据集,但作者仅选择了前 150K 条条目并仅使用第一轮指令。最终获得 200K 语音指令数据,称为 InstructS2S-200K。
训练数据。作者采用 InstructS2S-200K 数据集,其包括 200K 语音指令数据。
模型配置。作者使用 Whisper-large-v3 编码器作为语音编码器,使用 Llama-3.1-8B-Instruct 作为 LLM。
训练。LLaMA-Omni 遵循两阶段训练过程:在第一阶段,作者训练语音适配器和 LLM,批处理大小为 32,共 3 个 epoch;在第二阶段,作者训练语音解码器,使用与第一阶段相同的批处理大小、step 数等。整个训练过程在 4 个 NVIDIA L40 GPU 上大约需要 65 小时。
在评估方面,作者从以下方面对模型进行了评估:
除此以外,语音 - 语言模型的基线系统包含 SpeechGPT 、 SALMONN (+TTS) 、 Qwen2-Audio (+TTS) 。
表 1 给出了 InstructS2S-Eval 基准测试主要结果。
首先,在 S2TIF 任务中,从内容(content)角度来看,LLaMA-Omni 相比之前的模型有了显著提升,这主要是因为 LLaMA-Omni 是基于最新的 Llama-3.1-8B Instruct 模型开发的,充分利用了其强大的文本指令跟随能力。
从风格(style)角度来看,SALMONN 和 Qwen2-Audio 得分较低,因为它们是语音 - 文本模型,输出风格与语音交互场景不太对齐,经常产生格式化的内容,包含大量冗余解释。相比之下,SpeechGPT 作为语音 - 语音模型,获得了更高的风格得分。
LLaMA-Omni 获得了最高的风格得分,这说明在 InstructS2S-200K 数据集上训练后,模型输出风格已经与语音交互场景很好地对齐。
对于 S2SIF 任务,LLaMA-Omni 在内容和风格得分上也都优于之前的模型。这进一步证实了 LLaMA-Omni 能够以简洁、高效的方式通过语音有效地处理用户指令。
此外,在语音和文本响应的对齐方面,LLaMA-Omni 的 ASR-WER 和 ASR-CER 得分最低。相比之下,SpeechGPT 在对齐语音和文本响应方面表现不佳,这可能是因为它是串行生成文本和语音的。
级联系统(如 SALMONN+TTS 和 Qwen2-Audio+TTS)的语音 - 文本对齐也不是最理想的,主要是因为生成的文本响应可能包含无法合成语音的字符。这个问题在 Qwen2-Audio 中尤为明显,它偶尔会输出中文字符,从而导致语音响应错误。
相比之下,LLaMA-Omni 的 ASR-WER 和 ASR-CER 得分最低,表明生成的语音和文本响应之间的对齐程度更高,进一步验证了 LLaMA-Omni 在同时生成文本和语音响应方面的优势。
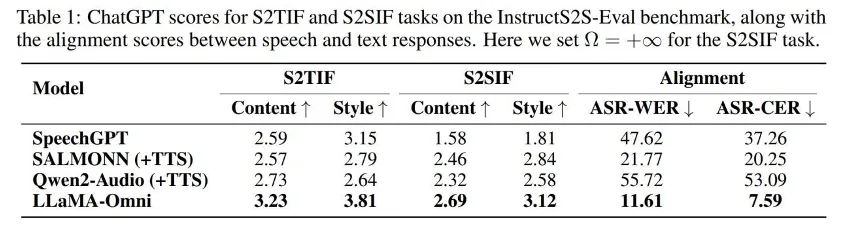
为了更好地理解 Ω 的影响,作者对系统延迟、语音和文本响应之间的对齐以及不同 Ω 设置下生成的语音质量进行了探索。
如表 2 所示,当 Ω 设置为 10 时,系统的响应延迟低至 226ms,甚至低于 GPT-4o 的平均音频延迟 320ms。
综合来看,可以根据不同的场景调整 Ω 的值,以实现响应延迟和语音质量之间的权衡。
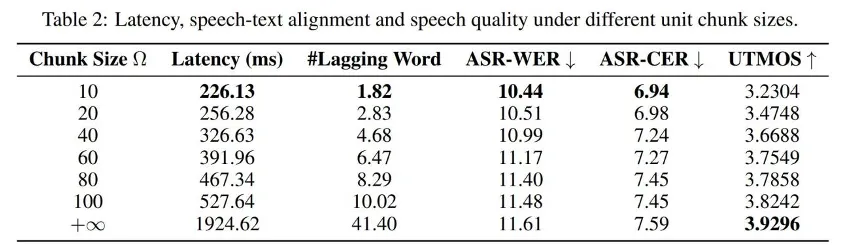
表 3 列出了不同模型在 S2TIF 和 S2SIF 任务上的平均解码时间。
LLaMA-Omni 直接提供简洁的答案,从而显著缩短解码时间,平均每条指令仅为 1.49 秒。
LLaMA-Omni 同时输出文本和语音响应,并采用非自回归架构生成离散单元,总生成时间仅增加 1.28 倍,体现出 LLaMA-Omni 在解码速度上的优势。
为了直观的了解不同模型的响应差异,作者在表 4 中提供了一个示例。
可以观察到 Qwen2-Audio 的响应相当冗长,并且包含换行符和括号等无法合成语音的元素。
SALMONN 的响应也有点长。
SpeechGPT 的响应风格更适合语音交互场景,但其响应所包含的信息量较少。
相比之下,LLaMA-Omni 给出的响应在保持简洁风格的同时更加详细和有帮助,在语音交互场景中的表现优于之前的模型。

文章来自于微信公众号“机器之心”



【开源免费】Whisper是由openai出品的语音转录大模型,它可以应用在会议记录,视频字幕生成,采访内容整理,语音笔记转文字等各种需要将声音转出文字等场景中。
项目地址:https://github.com/openai/whisper
在线使用:https://huggingface.co/spaces/sanchit-gandhi/whisper-jax
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
