# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
9月 24 日,字节跳动的豆包大模型发布多款新品——视频生成、音乐生成以及同声传译大模型。
字节的视频生成模型首次亮相,这也意味着,在快手之后,国内的两大短视频巨头都进入了AI视频生成赛道。
发布会上还公布了豆包大模型的最新数据,截至9月,豆包大模型的日均 tokens 使用量已经超过1.3万亿,4个月的时间里 tokens 整体增长超过了10倍。在多模态方面,豆包·文生图模型日均生成图片5,000万张,此外,豆包目前日均处理语音85万小时。
目前,豆包大模型已涵盖大语言模型、视觉大模型、语音大模型三大品类发布了13个大模型。此外,豆包通用模型Pro升级,初始TPM支持800k、上下文窗口达到256k。

豆包视频生成模型有PixelDance和Seaweed两个版本,目前尚不清楚两个版本的具体区别,目前均未开放试用。
PixelDance V1.4是ByteDance Research团队开发的 DiT 结构的视频生成大模型,同时支持文生视频和图生视频,能够一次性生成长达10秒的视频片段。
精准语义理解,多主体交互
豆包视频生成模型可以遵从复杂的用户提示词,精确理解语义关系,解锁时序性多拍动作指令与多个主体间的交互能力。
下方第一条视频展示了一位喝咖啡的男士。他喝了一口咖啡;这时一个女人从画面右侧出现,走到了他的身后。第二支视频中,一名男子和女子在驰马飞奔。

提示词:一名中国男子端起咖啡喝了一口, 一名女子走到了他身后

提示词:一对长头发的外国男子和女子在骑马驰骋
酷炫运镜,告别PPT动画
再来看另一个例子。
运镜是视频语言的关键之一。豆包视频生成模型可以让视频在主体的大动态与镜头中炫酷切换,拥有变焦、环绕、平摇、缩放、目标跟随等多镜头话语言能力,灵活控制视角,带来真实世界的体验。

提示词:一名亚洲男子带着护目镜游泳,身后是另一名穿潜水服的男子

提示词:一位女性喝了一口咖啡,然后端着咖啡,带着伞走了出去
一致性多镜头,10秒讲述完整故事
一致性多镜头生成是豆包视频生成模型的一项特色能力。在一句提示词内,实现多个镜头切换,同时保持主体、风格和氛围的一致性。

提示词:一个女孩儿从汽车上下来,远处是夕阳

提示词:一名外国男子在冲浪,对着镜头竖起大拇指
支持多种风格比例
豆包视频生成模型支持丰富多样的题材类型,以及包括黑白、3D动画、2D动画、国画、水彩、水粉等多种风格。同时,模型涵盖1:1、3:4、4:3、16:9、9:16、21:9 六个比例,充分适配电影、电视、电脑、手机等多种场景。

提示词:梦幻场景,一只白色的绵羊,带着弯弯的角

提示词:水墨风格的鸟,比例16:9
豆包音乐模型实现了音乐生成通用框架,从词曲唱三个方面生成高质量音乐。
用户首先输入Prompt就可以得到一段歌词,然后在10余种不同风格的音乐和情绪表达中选择进一步创作出歌曲,再基于豆包语音能力,生成可以媲美真人演唱效果的声音,可以实现气口、真假音转换技巧的模拟。
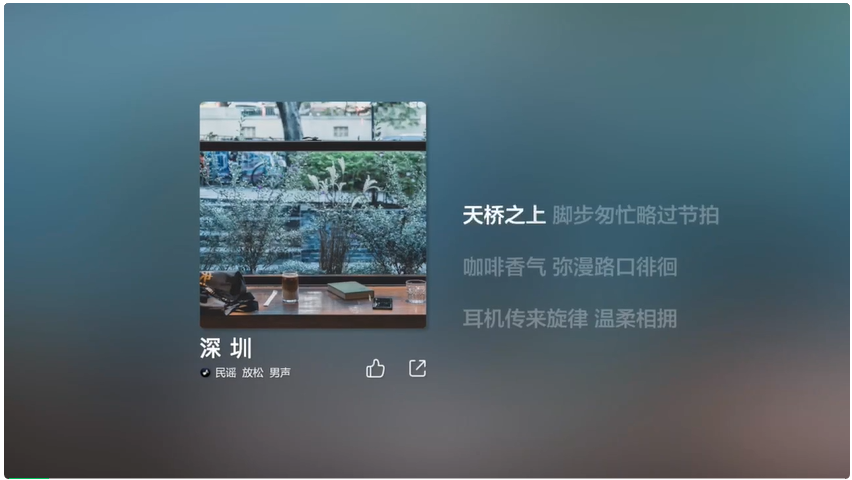
目前,开发者可以通过火山方舟使用豆包音乐模型API,用户也可以直接通过豆包App和海绵音乐App创作音乐。
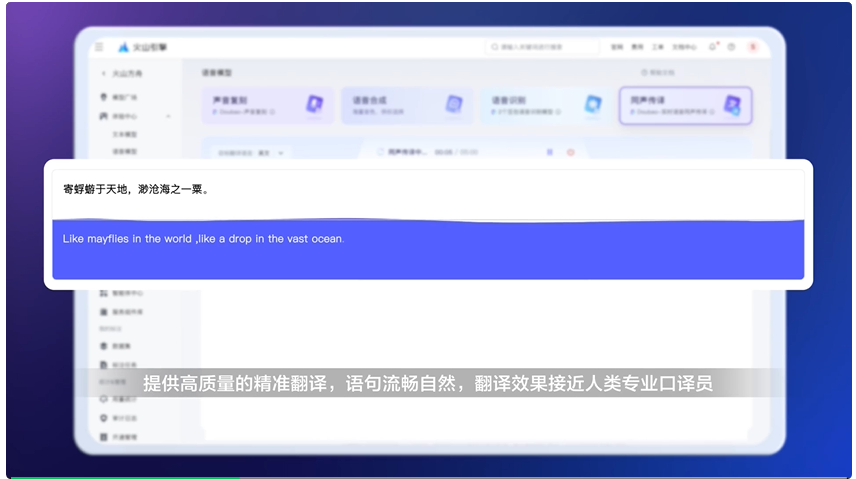
在实时翻译方面,豆包同声传译模型可以做到边说边译,且在办公、法律、教育等场景接近甚至超越人类同传水平,还能支持跨语言同音色翻译。
文章来自于“Founder Park”,作者“Founder Park”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
