# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“不需要再等OpenAI的鸽王Sora了”。
字节版Sora终于来了,这一次还憋了个大的——
一口气推出Seaweed和PixelDance两款豆包视频模型,支持文生/图生视频,时长可达10s。

以PixelDance为例,其最大特色在于多主体交互,一致性多镜头生成。
啥意思??——直接来看几个官方demo。
First kill,现在手上有这样一张原图:

若使用当前大多视频模型,一般只能进行到“摘墨镜”这个环节;而PixelDance能解锁时序性多拍动作指令。(摘完墨镜还能站起来,并走向雕像)

还有类似电视剧的飙戏名场面(多个主体),各自眼神、动作,一整个拿捏。

Double kill,饱受吐槽的PPT动画有新解了。PixelDance拥有变焦、环绕、平摇、缩放、目标跟随等多镜头话语言能力。
提示词:一名亚洲男子带着护目镜游泳,身后是另一名穿潜水服的男子

关键来了,在一致性方面,PixelDance号称能10秒讲述完整故事。
说人话就是,在一句提示词内,实现多个镜头切换,同时保持主体、风格和氛围的一致性。
提示词:一个女孩儿从汽车上下来,远处是夕阳

另外,PixelDance支持多种风格比例。(说你呢Runway)
提示词:水墨风格的鸟,比例16:9

结一下,字节版Sora这次主打多主体交互、酷炫运镜、一致性多镜头以及多风格比例。
发布会一结束,网友们的期待值也是拉满了,嗷嗷待哺内测资格!
与此同时,字节研究团队一篇PixelDance同名论文,也被扒了出来,再次引发热议。
字节团队此前入选CVPR 2024的论文,就提出了名为一种PixelDance的模型。

先划重点,团队采用的方法可以概括为:
基于潜在扩散模型,结合视频片段的首帧和尾帧图像指令与文本指令进行视频生成,并有效利用公开视频数据进行训练。
首先,团队采用广泛使用的2D UNet作为扩散模型,该模型由一系列空间下采样层和一系列空间上采样层构建,并插入了跳跃连接。
具体来说,它由两个基本模块构建,即2D卷积模块和2D注意力模块。
通过插入时间层将2D UNet 扩展为3D变体,其中在2D卷积层之后插入1D时间卷积层,2D注意力层之后插入1D时间注意力层。
模型可以通过图像和视频联合训练,在空间维度上保持高保真生成能力。
不过对于图像输入,1D时间操作被禁用。团队在所有时间注意力层中使用双向自注意力。
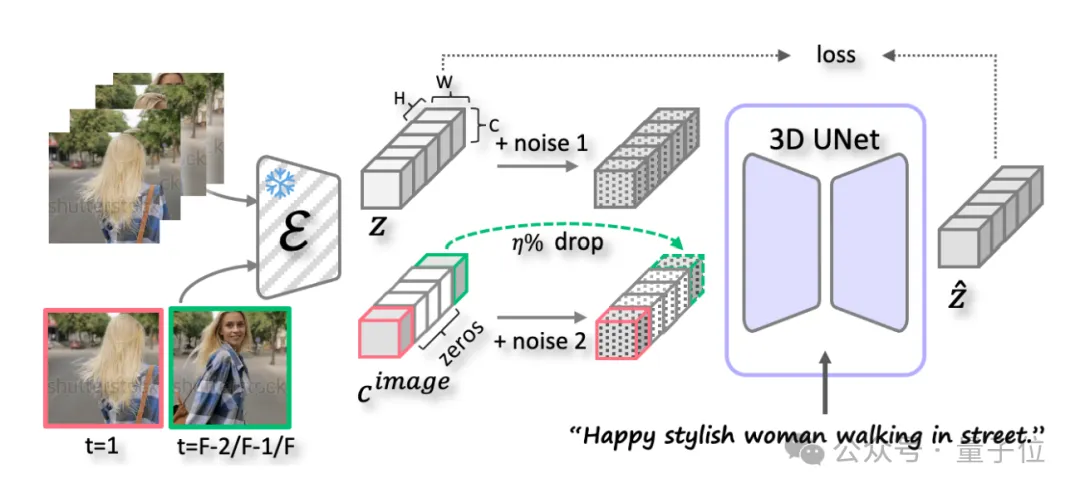
其次是指令注入。具体来说,PixelDance基于<文本,首帧,尾帧>指令。

这里要插一句,与文本指令相比,图像指令更加直接且易于获取——使用真实视频帧作为训练中的图像指令。
据了解,文本指令由预训练的文本编码器编码,并通过交叉注意力融入扩散模型。
图像指令由预训练的VAE编码器编码,并与受扰的视频潜变量或高斯噪声一起作为扩散模型的输入。
在训练过程中,团队使用(真实的)首帧指令来强制模型严格遵循该指令,从而保持连续视频片段之间的一致性。
当然了,PixelDance独特之处在于使用尾帧指令的方式。
简单说,团队有意避免让模型完全复制尾帧指令,因为在推理过程中提供一个完美的尾帧是很困难的,模型应该能够处理用户提供的粗略草稿,并作为指导。

为了实现这一点,团队开发了三项技术:
1、在训练过程中,尾帧指令是从视频片段的最后三帧(真实的)中随机选择的。
2、向指令中引入了噪声,以减少对指令的依赖性并提高模型的鲁棒性。
3、在训练中以一定概率(例如 25%)随机丢弃尾帧指令。
相应地,团队提出了一种简单但有效的推理策略。
概括起来就是,在前τ次去噪步骤中,利用尾帧指令引导视频生成朝向期望的结束状态。
在剩余的步骤中,指令被丢弃,允许模型生成时间上更连贯的视频。
通过调整τ,可以控制尾帧指令对生成结果的影响。
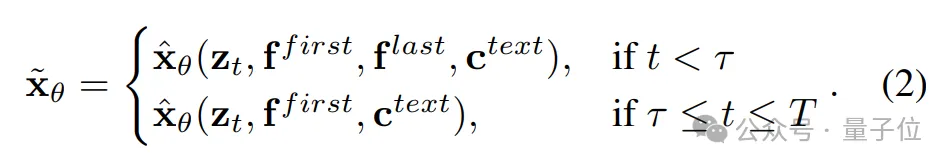
接下来,团队在WebVid-10M数据集上训练了视频扩散模型,该数据集包含大约1000万个短视频片段——
平均时长为18秒,分辨率通常为336 × 596,且每个视频都附有与视频内容松散相关的文本描述。
不过WebVid-10M存在一个问题,即所有视频上都带有水印,这导致生成的视频中也会包含水印。
因此,团队将训练数据扩展为另外自收集的50万个无水印视频片段,它们包含真实世界的实体,如人类、动物、物体和风景,并附有粗粒度的文本描述。
尽管这一额外数据集只占了很小比例,但团队惊讶地发现:
将该数据集与WebVid-10M结合训练后,如果图像指令没有水印,PixelDance就能够生成无水印的视频。
最终,PixelDance在视频-文本数据集和图像-文本数据集上进行联合训练。
对于视频数据,从每个视频中随机采样16个连续帧,每秒4帧。
此外,按照之前的工作,采用LAION-400M作为图像-文本数据集;每8次训练迭代使用一次图像-文本数据。

自论文发布之后,到产品上线这段时间具体又做了哪些改进,目前还不得而知。
由于刚发布,目前只能简单看到官方提及:

感兴趣的话可以亲自上手试一试来感受一下,目前豆包视频模型已在火山引擎开启企业用户的邀请测试;个人用户可在字节旗下的即梦AI申请内测。
官方声称,未来将逐步开放给所有用户。
那么,你期待这次的字节版sora吗?
想知道字节版sora和快手可灵、Runway这些国内外视频模型对比如何吗?
感兴趣的话欢迎评论区留言,没准一手横评就来了呢。
(企业版)火山引擎官网申请测试:
https://console.volcengine.com/
(个人版)即梦AI申请内测传送门:
https://bytedance.larkoffice.com/share/base/form/shrcnTPmPPxn9j6bw2AH3kdP6Fd
文章来自于“量子位”,作者“一水”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
