# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。
AI大模型开发系统Colossal-AI的混合精度训练再度升级,支持主流的BF16(O2) + FP8(O1)的新一代混合精度训练方案。
仅需一行代码,即可对主流LLM模型能够获得平均30%的加速效果,降低相应大模型开发成本,并保证训练收敛性。
无需引入额外的手写CUDA算子,避免了较长的AOT编译时间和复杂的编译环境配置。
开源地址:https://github.com/hpcaitech/ColossalAI
低精度计算一直是GPU硬件发展趋势。
从最早的FP32,到目前通用的FP16/BF16,再到Hopper系列芯片(H100, H200, H800等)支持的FP8,低精度计算速度越来越快,所需的内存也越来越低,非常符合大模型时代对硬件的需求。
目前FP8混合精度训练影响训练结果的最大因素就是scaling方案,常见的方案有两种:
延迟scaling采用之前一段时间窗口内的scaling值来估计当前scaling,同时将scaling的更新和矩阵乘法(gemm)融合起来。这种计算方法效率较高,但由于是估算的scaling,所以对收敛性影响较大。
实时scaling直接采用当前的张量值来计算scaling,所以计算效率较低,但是对收敛性影响较小。根据英伟达的报告,这两种scaling方案的计算效率差距在10%以内。
Colossal-AI采用了对训练收敛性影响较小的实时scaling方案,同时实现有着不输其他延迟scaling实现的性能。
在单卡H100上对矩阵乘法进行的测试,可以看到矩阵的维度越大,FP8的加速效果越明显,而且Colossal-AI的实现与Transformer Engine的性能几乎一致,如图1所示。但Transformer Engine需要复杂的AOT编译环境配置和较长的编译时间。
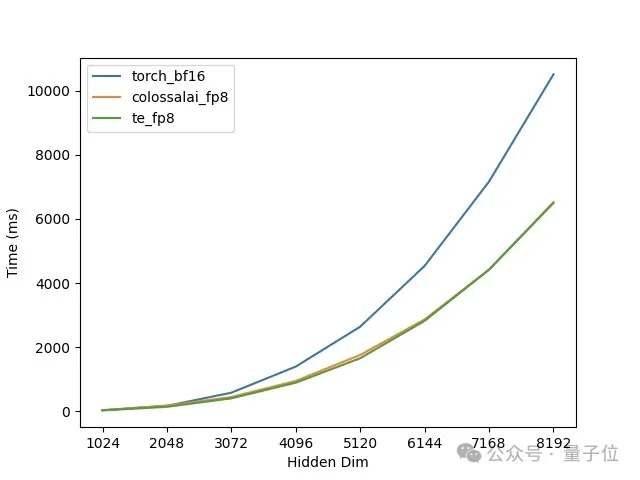
△图1. 单卡GEMM性能测试
为了实验结果更贴近现实,Colossal-AI直接在主流LLM上进行了实际训练的测试。
首先在H100单卡上进行了测试,以下测试中Transformer Engine (TE)采用的其默认的延迟scaling方案。
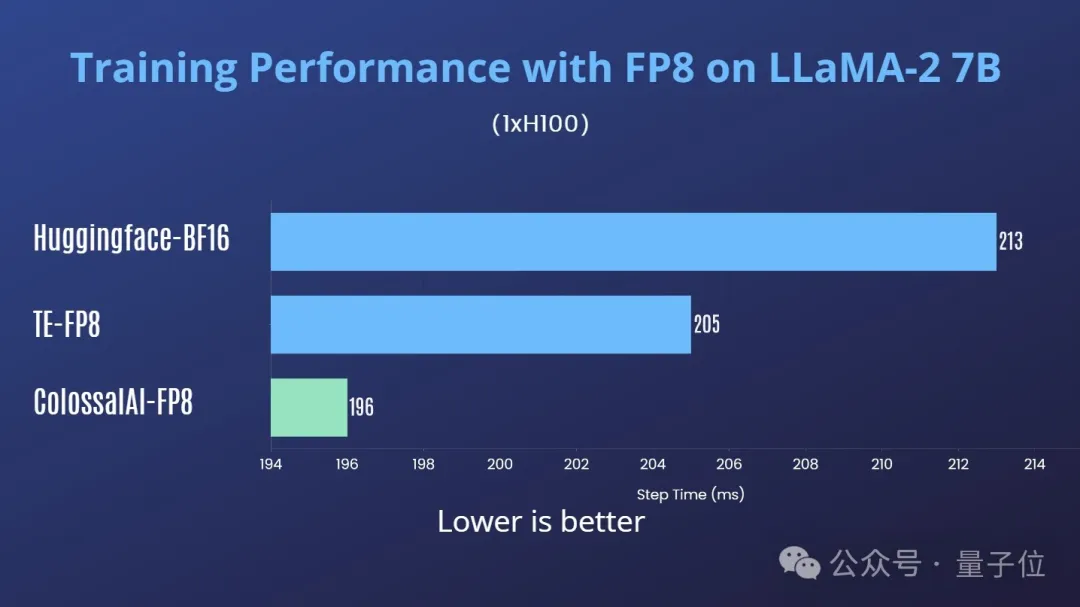
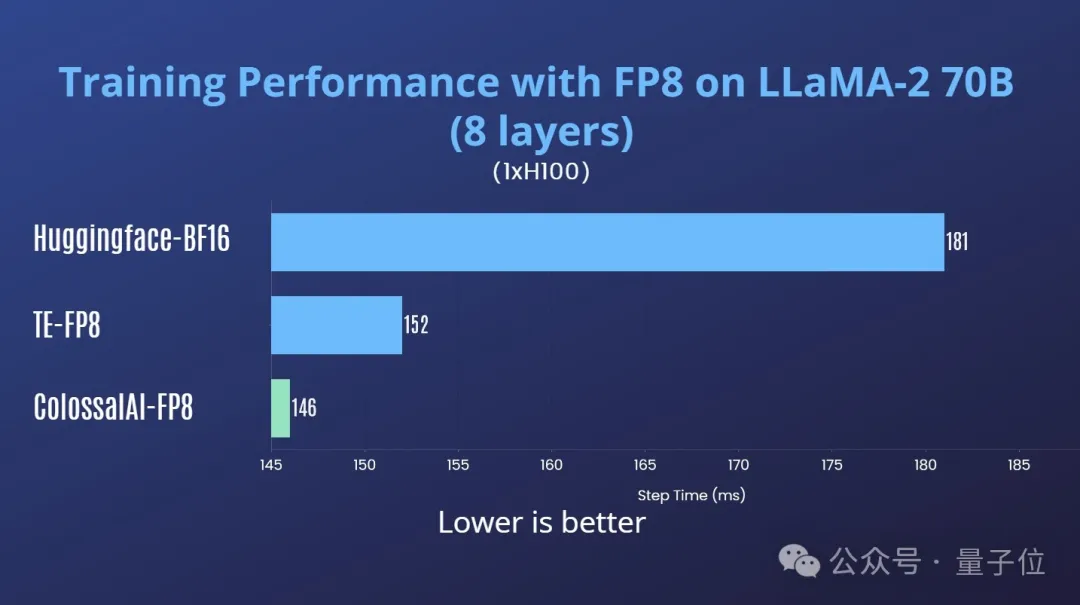
同时进行了收敛性测试,可以看到FP8混合精度训练的loss曲线与bf16的基本一致,如图4所示:

△图4. H100单卡 LLaMA2-7B 混合精度训练loss曲线
Colossal-AI还测试了H800多卡并行训练场景下的性能。在单机8卡H800上训练LLaMA2-7B,Colossal-AI FP8对比Colossal-AI BF16有35%的吞吐提升,对比Torch FSDP BF16有94%的吞吐提升。
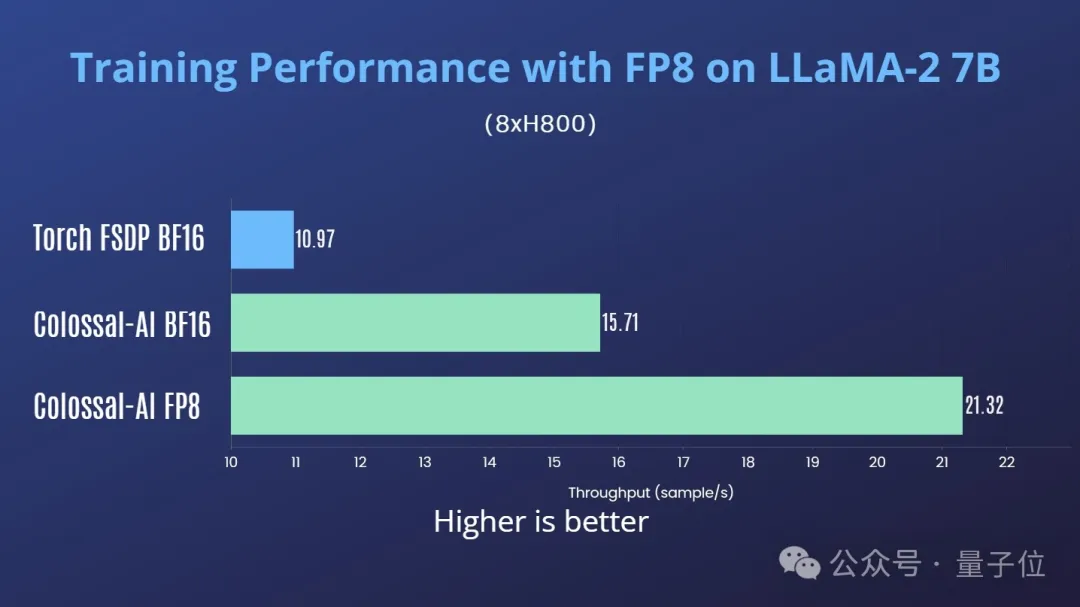
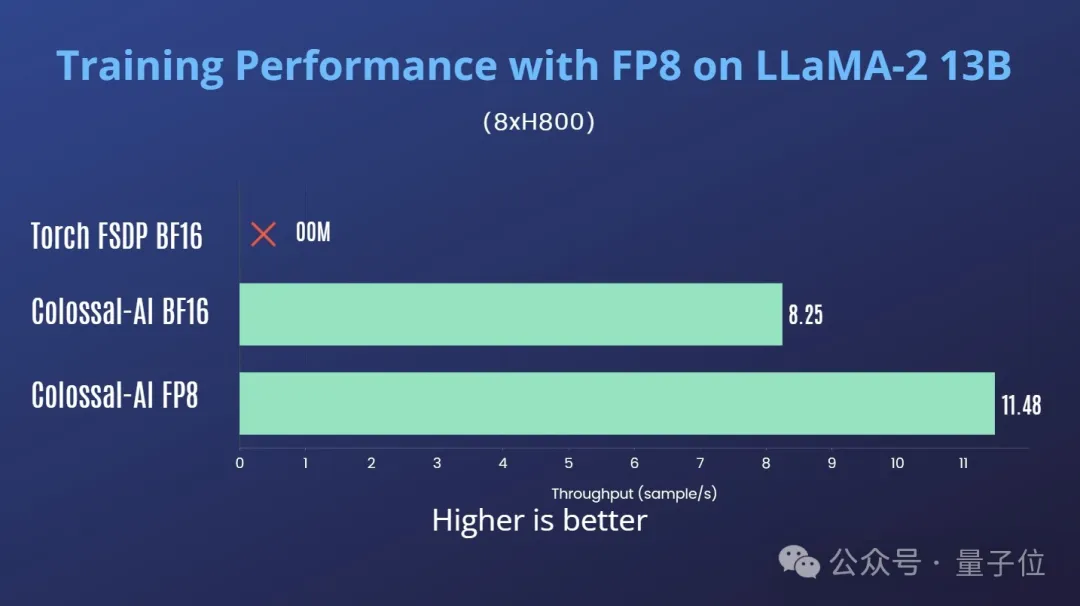
在单机8卡H800上训练LLaMA2-13B,Colossal-AI FP8对比Colossal-AI BF16有39%的吞吐提升。
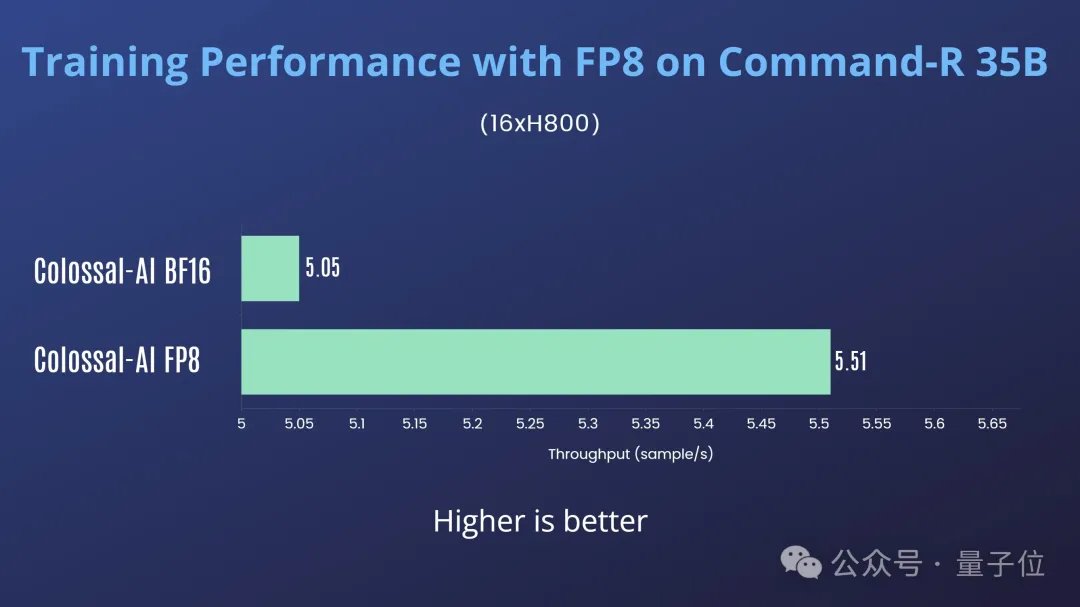
在2机16卡H800上训练Cohere Command-R 35B,Colossal-AI FP8对比Colossal-AI BF16有10%的吞吐提升,如图7所示:
根据英伟达的报告和测试经验,对FP8混合精度训练性能调优有一些初步的认识:
由于上述实验中Command-R 35B采用了张量并行,所以加速效果不太明显。
Colossal-AI对FP8的支持较为广泛,各种并行方式都能和FP8混合精度训练兼容。使用时,仅需在初始化plugin时开启FP8即可:
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
...
plugin = LowLevelZeroPlugin(..., use_fp8=True)
plugin = GeminiPlugin(..., use_fp8=True)
plugin = HybridParallelPlugin(..., use_fp8=True)
除此之外,无需多余的代码和AOT编译。
开源地址:https://github.com/hpcaitech/ColossalAI
文章来自于微信公众号“量子位”,作者“允中”




