# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLMs)在形式化定理证明中正面临两个核心挑战:
1. 形式化证明数据的稀缺性:当前数据集有限,难以支持模型在专门的数学和定理证明任务中的高效学习。
2. 多步骤推理的复杂性:形式化定理证明要求模型在多个步骤中保持逻辑严谨性,以生成正确的数学证明。
在这种背景下,研究团队提出了一个全新的框架:SubgoalXL,结合了子目标(subgoal)证明策略与专家学习(expert learning)方法,在 Isabelle 中实现了形式化定理证明的性能突破。

SubgoalXL 如何应对挑战?
SubgoalXL 通过以下两种关键策略来应对形式化定理证明中的挑战:
1. 子目标证明策略:将证明过程分解为多个子目标,这些子目标构成了解决复杂推理任务的关键步骤。通过这种分解,SubgoalXL 在更接近形式化证明的逻辑框架下进行推理,使得生成的证明过程更加清晰有序。子目标证明策略有效地缓解了因非形式化与形式化证明之间的不一致性导致的学习瓶颈,增强了模型在形式化环境中的表现。
2. 专家学习框架:通过一个由形式化陈述生成器、子目标生成器和形式化证明生成器组成的迭代优化框架,SubgoalXL 能够在每个迭代过程中从经验数据中学习,调整各个组件的参数,使得模型在多步骤推理中的准确性和有效性不断提升。该框架利用概率建模和梯度估计技术,确保在每个迭代中从最优分布中采样数据,最大化模型的学习效率和推理能力。
方法概述
SubgoalXL 的方法核心在于子目标证明策略和专家学习框架的结合。
子目标证明策略 (图一左):我们首先手动创建了一组用于上下文学习的演示示例,然后使用这些示例指导模型生成子目标证明训练数据。具体来说,我们从 miniF2F-valid 中选择了部分问题,并手动构建了每个问题的已验证形式化证明,作为初始输入。通过 GPT-4o 生成子目标证明,该过程确保了:1) 子目标证明由自回归模型生成;2) 生成的证明风格一致,降低了模型的学习负担;3) 每个子目标与 Isabelle 中的形式化中间目标相对应。这种方法保证了非形式化证明与形式化证明之间的更高一致性,有效提升了形式化定理证明的质量。
专家学习框架 (图一右):该框架由三个核心模块组成:
在每个迭代过程中,SubgoalXL 根据先前生成的陈述和证明样本进行参数优化。专家学习框架使用概率建模和梯度估计技术,对各模块进行迭代优化,以从最佳分布中采样数据。这种方法确保了模型在处理新的证明任务时能够保持高精度和稳健性。
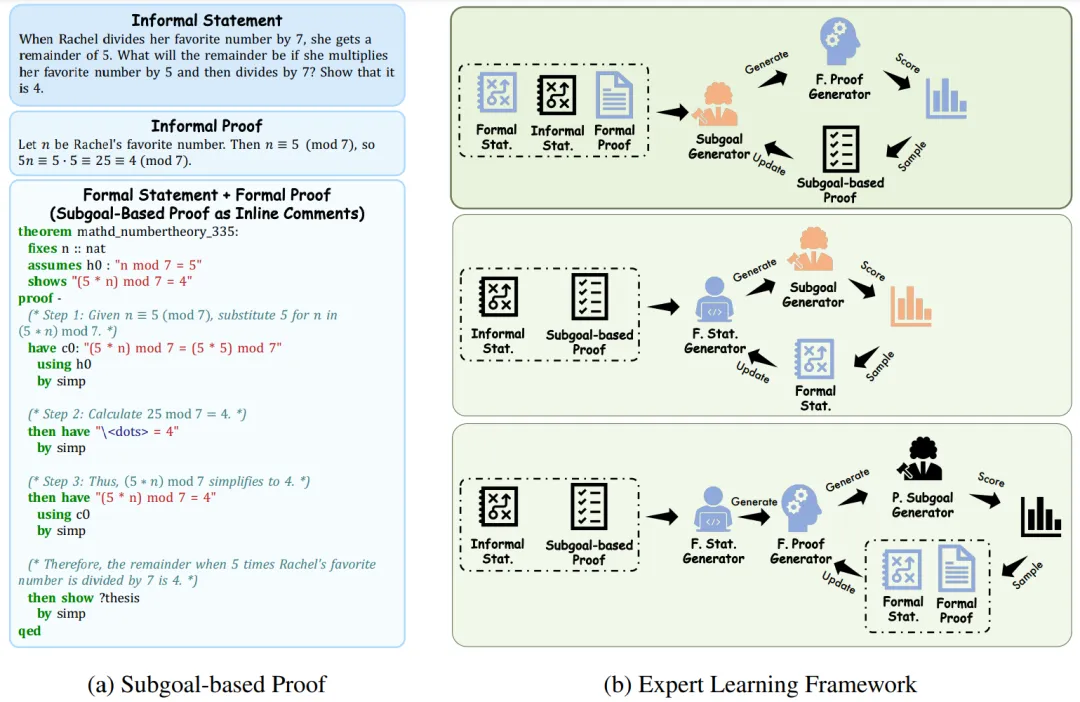
图 1:左:非形式化陈述、非形式化证明、形式化陈述、形式化证明和子目标证明的示例。右:基于子目标的专家学习框架概览。缩写:“Stat.” 表示 “陈述”,“F.” 表示 “形式化”,“P.” 表示 “后验”。每次迭代从最优分布中采样子目标证明、形式化陈述和形式化证明。
实验结果
我们在标准 miniF2F 数据集上对 SubgoalXL 进行了全面的评估,结果表明其在 Isabelle 环境下达到了新的最优性能:
主实验结果:SubgoalXL 在 miniF2F-valid 数据集上的通过率达到了 61.9%,在 miniF2F-test 数据集上达到了 56.1%。这一表现超过了多种现有的基线方法,包括 Thor、DSP、Subgoal-Prover、LEGO-Prover 以及 Lyra 等,展示了显著的性能提升(见表 1)。
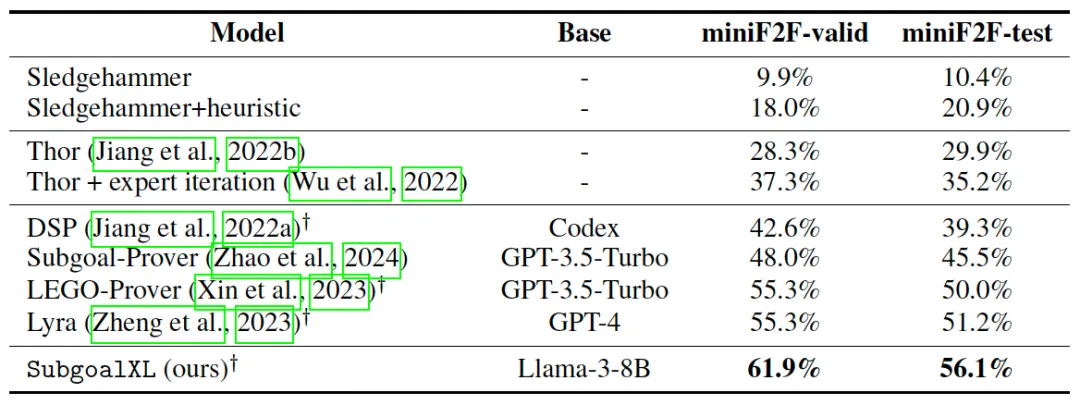
表 1:miniF2F 数据集上的性能。标记为†的方法在证明搜索过程中部分或全部使用了人工编写的非形式化证明。加粗数字表示获得的最高性能。
迭代提升分析:在逐步迭代的过程中,SubgoalXL 表现出明显的性能增长。模型在 miniF2F-valid 数据集上的通过率从初始的 58.2% 逐步提升至 61.9%,在 miniF2F-test 数据集上从 51.2% 提升至 56.1%。这些结果表明,通过逐步优化和专家学习框架的迭代,模型在每次迭代中都能实现稳定的性能提升。
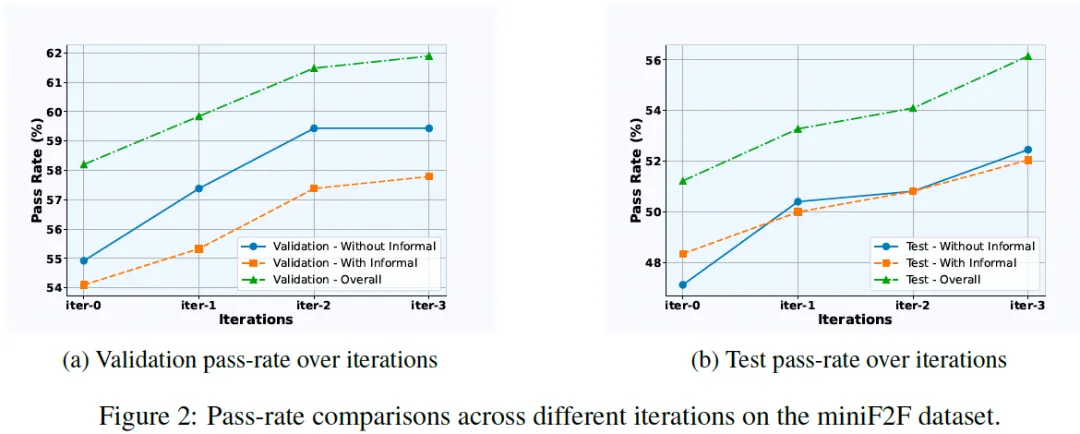
图 2:miniF2F 数据集中不同迭代次数下的通过率比较。
子目标证明对比分析:实验显示,SubgoalXL 使用的子目标证明方法在处理复杂证明任务时表现优于人类编写的非形式化证明。尤其在复杂问题上,子目标证明策略显著提高了证明的精确性和可靠性(见图 3)。

图 3:子目标证明与非形式化证明的案例对比。左侧示例为子目标证明的成功尝试,右侧两个示例为非形式化证明的失败尝试。
结论与未来展望
SubgoalXL 的成功展示了大语言模型在形式化定理证明任务中的巨大潜力,并为未来研究指明了方向。我们相信,通过进一步优化框架、拓展数据集和应用场景,大语言模型将在数学和科学领域带来更深远的影响。
文章来自于“机器之心”,作者“赵学亮”。




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
