# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文的主要作者来自清华大学智能视觉实验室(i-Vision Group)、腾讯公司和南洋理工大学 S-Lab。本文的共同第一作者为清华大学自动化系博士生刘祖炎和南洋理工大学博士生董宇昊,主要研究方向为多模态模型。本文的通讯作者为腾讯高级研究员饶永铭和清华大学自动化系鲁继文教授。
视觉数据的种类极其多样,囊括像素级别的图标到数小时的视频。现有的多模态大语言模型(MLLM)通常将视觉输入进行分辨率的标准化或进行动态切分等操作,以便视觉编码器处理。然而,这些方法对多模态理解并不理想,在处理不同长度的视觉输入时效率较低。
为了解决上述问题,来自清华大学、腾讯、南洋理工大学的研究者们提出一种更灵活的多模态模型 Oryx。Oryx 是一种统一的多模态架构,能够处理图像、视频和多视角 3D 场景,提供了一种能够按照需求处理任意空间大小和时间长度视觉输入的解决方案。
Oryx 的核心创新点包括:一个预训练的 OryxViT 模型,能够将任意原始分辨率的图像编码为视觉 token;一个动态压缩模块,支持按需对视觉 token 进行 1 倍到 16 倍的压缩。上述设计使 Oryx 能够在处理不同需求下的任务时保持更高的效率和精度。此外,Oryx 通过增强的混合数据和针对上下文检索、空间感知数据的训练,在多模态融合上取得了更强的能力。

现有方法简单地将各种视觉输入统一处理,忽略了视觉内容的差异和不同应用的具体需求。例如,早期的 MLLM 将视觉输入转化为固定分辨率;近期的 MLLM 通过动态切分方式生成高分辨率的视觉表示。然而,由于缺乏支持原始分辨率输入的高质量视觉编码器,这些解决方案仍然是一种妥协。我们认为,提供原始分辨率的视觉输入具有以下优势:利用整个图像输入以防止信息丢失;解决边缘情况;提高效率和自然性;具有更高的性能等。
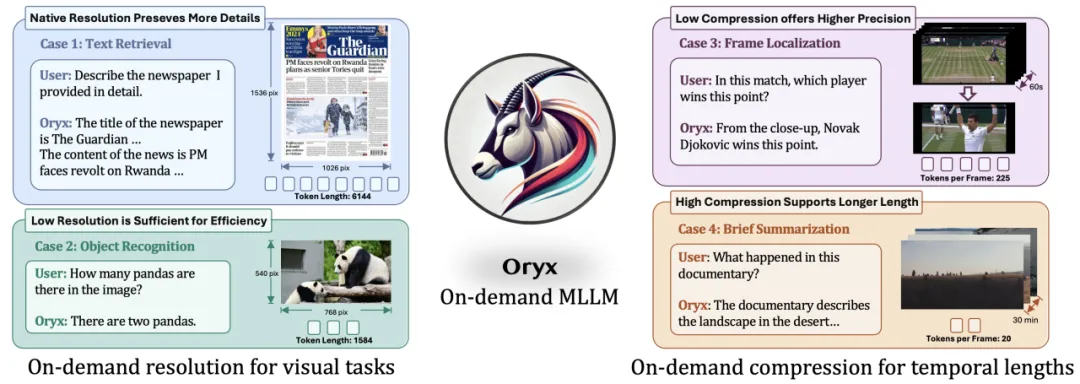
图 1:按需求理解的概念。
如图 1 所示,在分辨率和压缩比上的优化可以提高效率,满足实际需求。例如,高分辨率对于与文本相关的任务更重要,而对象层次的任务只需要简单的图像,部分应用场景需要总结极长的视频,其他应用场景需要对每一帧保持高精度。因此,支持时空上的任意分辨率是一种更通用和高效的方案。
为了解决以上挑战,本文提出了一个统一的时空理解 MLLM 框架 Oryx,能够在按需方式下处理任意视觉分辨率、不同时间长度和多样化的任务。Oryx 的主要贡献包括:
我们提供了 7B/34B 两种尺度的 Oryx 模型,在视频、图像和 3D 理解任务上表现出色,在 7B 规模下取得了综合最好的结果,34B 模型超越了部分 72B 模型的性能,在部分数据集超过 GPT-4o、GPT-4V 等模型,成为开源模型的新标杆。

图 2:Oryx 方法总览图。
此前在图像理解上的工作证明,保持视觉内容的原始形式具有更高的有效性。然而,原始分辨率在 MLLM 上的应用还未得到探索。我们认为,MLLM 实际上是一个应用原始分辨率的最好环境:视觉输入的来源更加多样,具有不同的需求和格式;语言 token 长度本质是动态的,因此视觉的动态表示可以无缝与后续阶段对接。
现有的解决方案证明,传统的视觉编码器无法处理原始分辨率输入。因此,我们基于 SigLIP 模型提出 OryxViT 视觉编码器。OryxViT 通过将位置嵌入矩阵进行缩放插值适应输入内容。我们通过轻量级的语言模型作为接口,训练视觉编码器的参数,从多个多模态任务下获取数据进行训练,得到 OryxViT 模型。
为了解决批处理过程中动态的序列长度问题,我们在通道维度上对不同长度的序列进行拼接,通过可变长自注意力操作,独立计算每个视觉输入的注意力矩阵,因此 OryxViT 可以高效处理不同纵横比的视觉信号,并保持与固定分辨率编码器相同的推理速度。
在处理不同长度的视觉输入时,对所有输入一视同仁会降低总体计算效率。我们通过动态压缩模块实现更高比例的压缩,并将不同压缩比的视觉内容统一成一致的模式,从而能够按需控制视觉序列的长度。我们对图像、视频和长视频应用不同压缩比的下采样层,并设置下采样倍率为 1 倍、4 倍、16 倍,从而实现可变和极高的压缩比。
为了减轻下采样的影响,我们采用区域注意力操作对高分辨率、低分辨率特征图进行交互。低分辨率的图像块作为查询向量,通过交叉注意力操作与高分辨率邻近小块进行交互
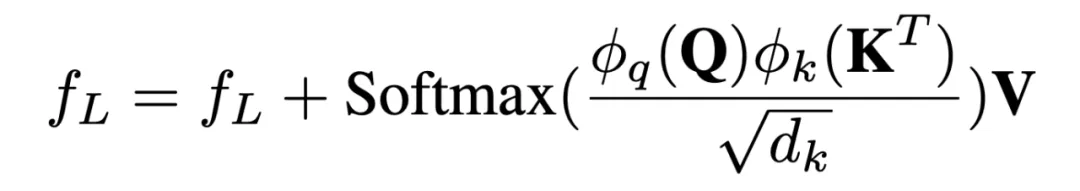
其中,我们通过投影层将 Q、K 向量投影到更低的维度,并省略了 V 向量和输出层的投影以保持原始视觉特征。我们通过共享的 MLP 处理不同压缩比的视觉输入,以保持不同视觉输入的一致性。最终的视觉表示被展平后输入到语言模型进行上下文预测。
我们进一步扩展了此前多任务 MLLM 的能力,处理更多样化的情境、不同长度的内容和更广泛的任务。
视频大海捞针训练。我们认为,处理长视频的关键在于从广泛的上下文中找到特定信息。因此,我们从 MovieNet 数据集中获取视频样本,并通过单帧标题生成和两帧差异识别两个任务对模型进行强化训练。
通过粗略空间关系学习 3D 知识。3D 环境相关的多视图图像缺乏时间或轨迹线索,因此以往的方法在 3D 任务中难以实现正确的空间理解。我们通过粗略空间关系对应的方法,使得模型在多视角中能够跟随和捕捉空间关联。
Oryx 的训练策略轻量且直接。模型初始化包括视觉编码器 OryxViT 和大语言模型。第一阶段训练仅涉及图像数据,首先在 LLaVA-1.5-558k 图文对中进行简单的对齐预训练,训练动态压缩模块。此后在 4M 高质量图文对中进行有监督微调,这些数据从各种开源学术数据集中获取。需要注意的是,我们没有进行大规模的预训练,也没有使用私有的有监督微调数据以获取更好的性能,我们的主要目标是验证架构的有效性。
在第二阶段,我们通过图像、视频和 3D 理解的多种视觉输入联合训练 Oryx 模型,微调策略与第一阶段类似。我们从第一阶段中抽样 600k 图像数据,并从开源视频数据集中选取多个视频数据集进行混合。此外,我们包含了所提出的视频大海捞针样本、具有粗略空间关系的 3D 样本。这部分引入的视频和多视角数据共 650k。
我们的训练数据均来源于开源数据集,因此确保了 Oryx 的可复现性,并提供了较大的进一步改进空间。
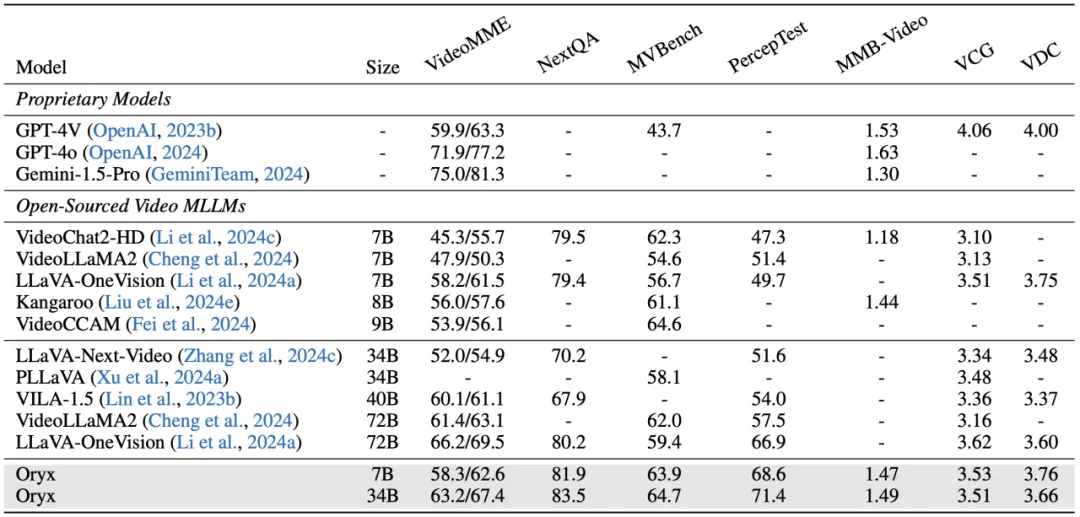
我们选取 4 个选择题评测标准和 3 个回答生成评测标准进行通用视频理解能力的测试。Oryx 在不同尺度的模型下均取得了有竞争力的表现。在带字幕的 VideoMME 数据集中,Oryx 取得 62.6% 和 67.4% 的平均准确率。在 NextQA 和 Perception Test 数据集分别超越此前的 SOTA 结果 3.3% 和 5.4%。在 GPT 评测的标准下,Oryx 表现出色,取得了 1.49、3.53 和 3.76 的平均得分。
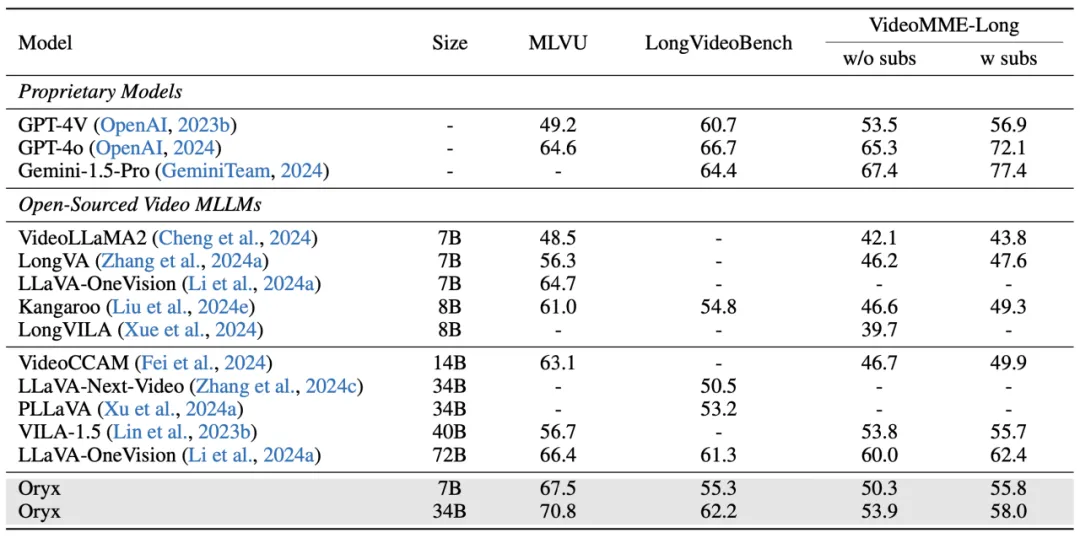
为了专门测试在长视频输入下的能力,我们选取了 3 个主流且具代表性的长视频理解基准,包括 MLVU、LongVideoBench 和 VideoMME 长视频子集。Oryx 在理解长视频内容表现出显著的能力,超越了所有现有的 7B 模型系列,34B 模型在 MLVU 和 LongVideoBench 上相比之前最先进的 72B 模型提升了 4.4% 和 0.9% 平均准确率。在 MLVU 测试集下,Oryx-34B 相比 GPT-4o 高出 6.2%。
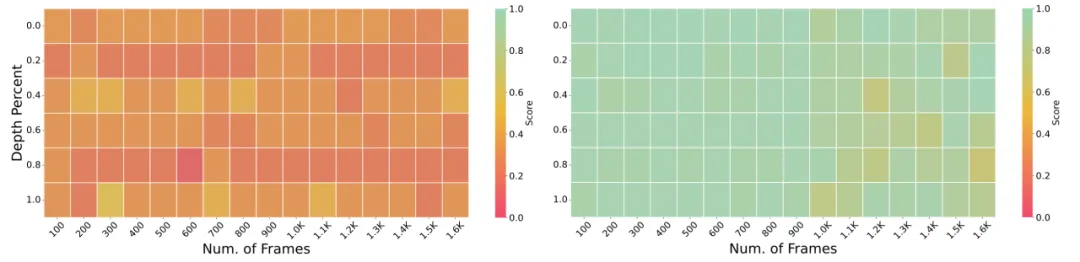
为了测试模型的长视频检索能力,我们进行了视频大海捞针实验。基线模型显示出严重的信息丢失,相比之下,我们的方法在 1.6k 帧输入的情况下仍然能够准确回答问题。
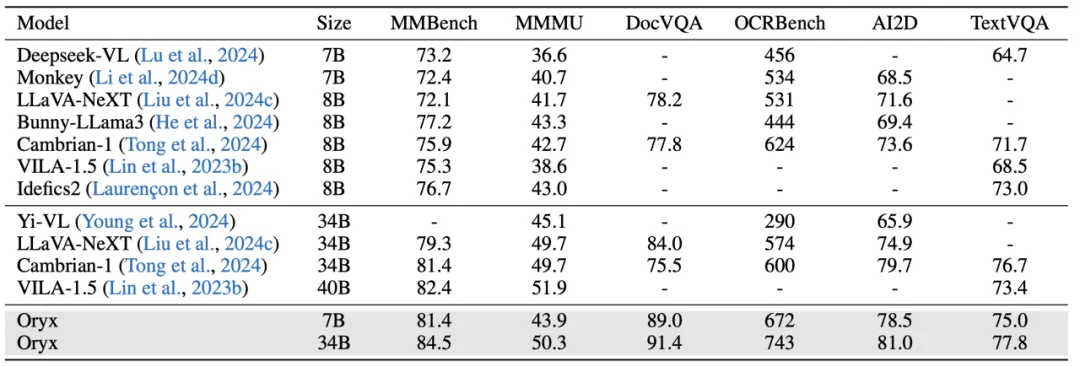
Oryx 模型在多种有代表性的图像评测基准下保持了开源模型中第一梯队的水平。
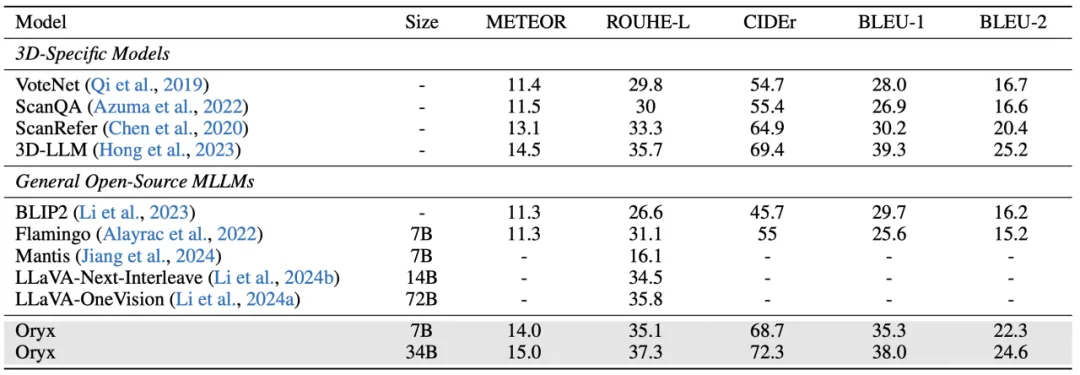
Oryx 在性能上超越此前为 3D 理解设计的专有模型,也超过最近更新的基于大语言模型的 3D 模型。
分辨率和缩放策略的影响。原始分辨率输入明显好于固定尺寸(保持长宽比不变)图像输入,尤其在特定任务下的数据集。在不同视觉输入分辨率下,MMBench 和 OCRBench 性能均有提升,但原始分辨率是相较而言更简单且有效的策略。

Oryx 结构的消融实验。在视觉编码器维度,OryxViT 相比 SigLIP 具有更优异的图像 - 语言对齐性能。通过对原始分辨率和动态切分方法的公平比较,此前的视觉编码器无法处理原始分辨率输入,而基于 OryxViT,原始分辨率方法明显优于动态切分方法。在我们的训练和测试过程中,我们始终保持原始分辨率输入。
对于连接模块,动态压缩模块在视频测试集中表现出更优越的性能,且平均池化具有更好的结果,这可能是由于无参数降采样能够更好地保留视觉特征分布,并减轻训练的优化压力。

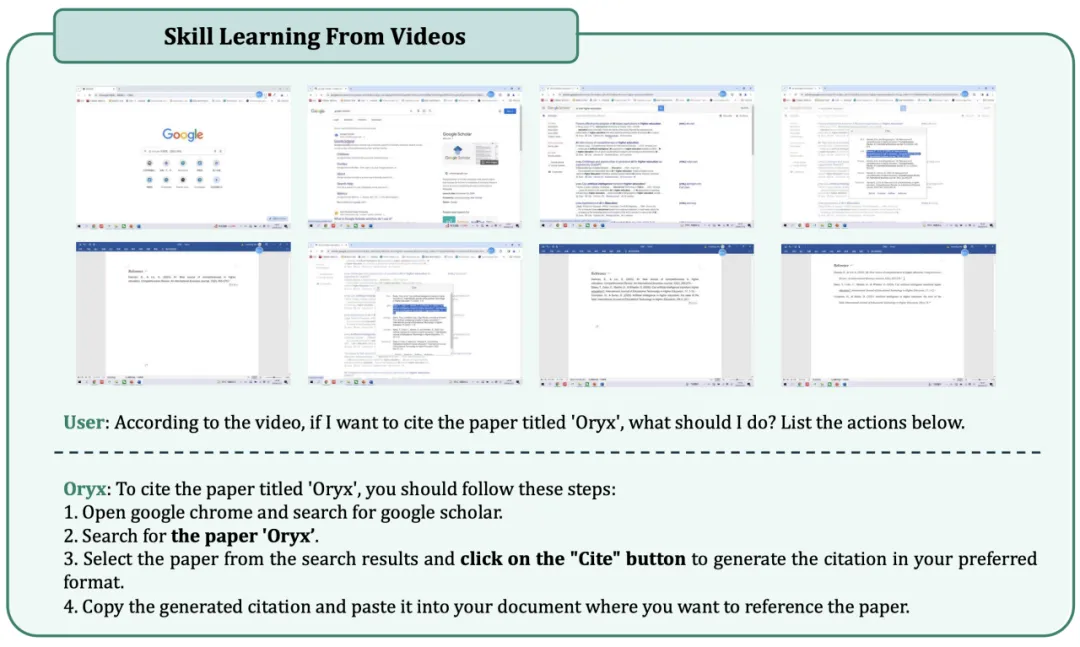
视频描述和总结任务

基于视频内容的推理和学习
我们提出了 Oryx 系列,一种能够按需处理不同任务、时间长度、视觉分辨率输入的新架构。Oryx 在时空理解上有突出表现,利用 OryxViT 创新地处理原始分辨率,采用动态压缩模块进行高效的数据压缩,并应用了更好的训练策略。Oryx 在各种主流图像、视频和 3D 测试基准中均表现出色。我们希望本工作能够为多模态学习提供一个新视角。
文章来自于微信公众号“机器之心”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
