# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
曾几何时,LLM还是憨憨的。
脑子里的知识比较混乱,同时上下文窗口长度也有限。
检索增强生成(RAG)的出现在很大程度上提升了模型的性能。
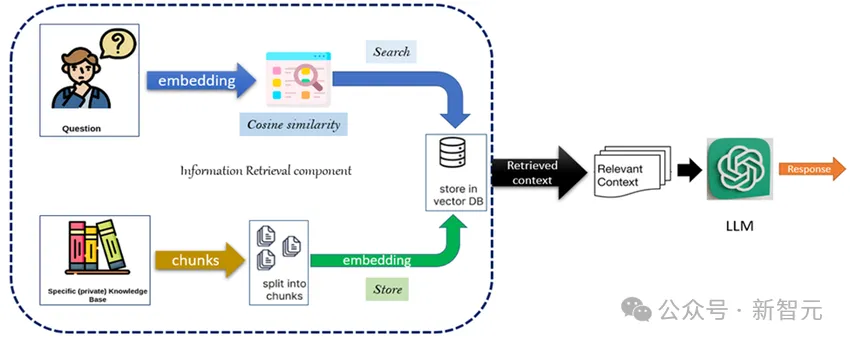
然而,LLM很快变得强大,上下文窗口长度也迅速膨胀。
现役的主流大模型,比如GPT-4o、Claude-3.5、Llama3.1、Phi-3和 Mistral-Large2等,都支持128K长的上下文,Gemini-1.5-pro甚至达到了1M的长度。
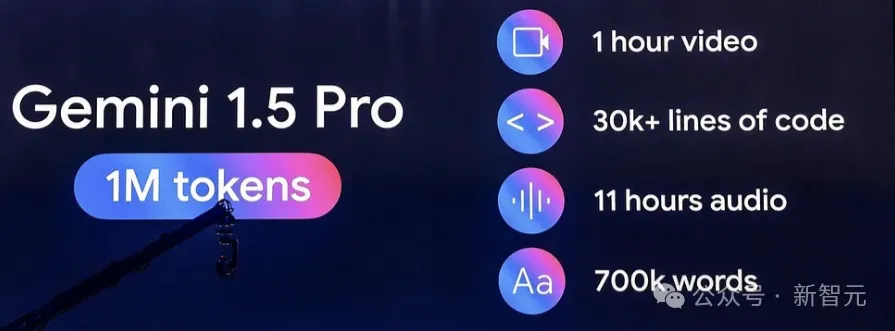
于是人们不禁要问:在长上下文LLM时代,RAG还有存在的必要吗?
这样的疑问是有根据的,之前的一项研究就证明了,长上下文(LC)在答案质量方面始终优于RAG:

论文地址:https://www.arxiv.org/pdf/2407.16833
在这勃勃生机、万物竞发的春天里,RAG当真要失宠了么?
近日,来自英伟达的研究人员重新审视了这个问题,他们发现, LLM上下文中检索块的顺序对于答案质量至关重要。
传统的RAG会将检索到的块按照相关性降序排列,但这篇工作表明,保留原始文本中检索块的顺序,能够显著提高RAG的答案质量。

论文地址:https://arxiv.org/pdf/2409.01666
由此,研究人员提出了保序机制——Order-Preserve RAG(OP-RAG)。
在En.QA数据集上的实验中,OP-RAG方法(Llama3.1-70B)仅使用16K检索到的token,就实现了44.43的F1-score。
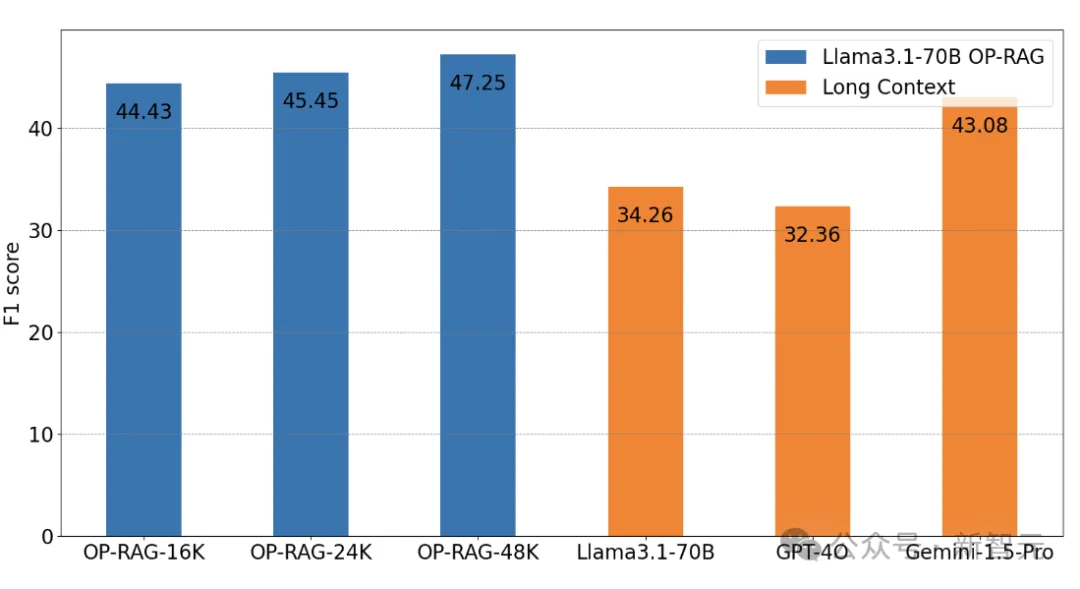
相比之下,没有RAG的Llama3.1-70B,在充分利用128K上下文的情况下,只达到了34.32的F1-score。
而GPT-4o和Gemini-1.5-Pro则分别为32.36分和43.08分。
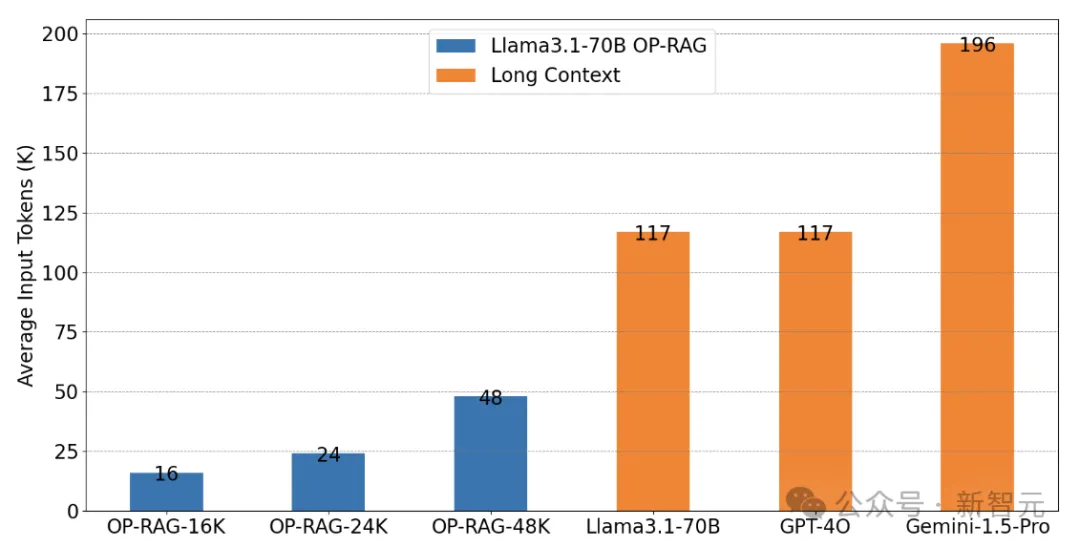
上图显示了每组实验平均输入的token数量,可以认为OP-RAG以很少的资源量达到了超越长上下文的效果。
——这也再次证明了RAG的独特价值。
RAG曾帮助早期的LLM克服了有限上下文的限制,通过访问最新的信息,显著减少LLM的幻觉,提高了事实准确性。
尽管目前长上下文的研究逐渐获得偏爱,但作者认为超长的语境会导致LLM对相关信息的关注度降低,最终使答案质量下降,而本文提出的OP-RAG则能够用更少的token换来更高的答案质量。
首先通过以下方式表示长上下文:将长文本d切成N个连续且均匀的块c,ci表示第i块 。给定一个查询q,可以得到ci块的相关性得分(通过计算嵌入之间的余弦相似度):
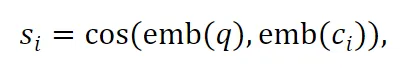
检索出相似度得分最高的前k个块,但保留这些块在原始长上下文d中的顺序。
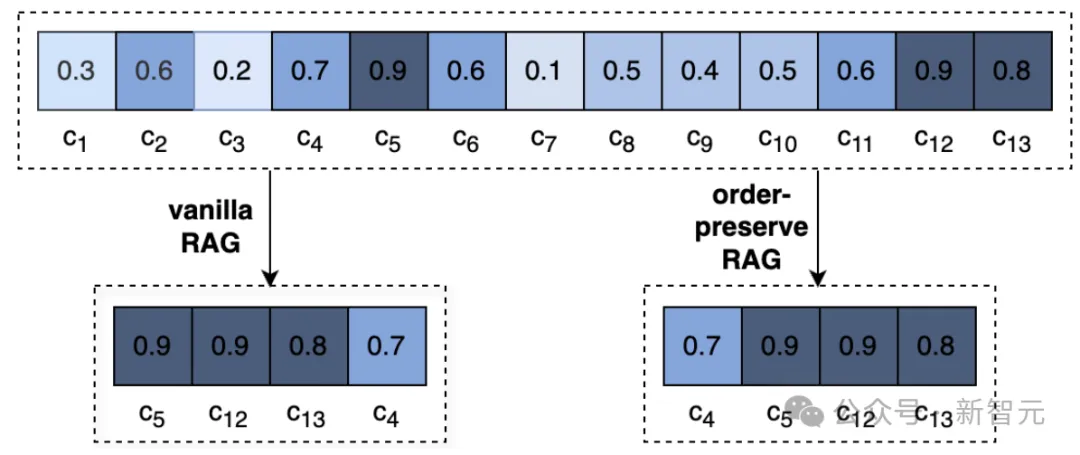
上图直观展示了普通RAG与OP-RAG之间的差异:一个长文档被切分为13块并计算了相似度分数。
同样是检索相似度得分最高的前4个块,Vanilla RAG按分数降序重排了,而OP-RAG保留了块之间的相对顺序。
研究人员选择了专为长上下文QA评估而设计的EN.QA和EN.MC数据集进行实验。
En.QA由351个人工注释的问答对组成,数据集中的长上下文平均包含150,374个单词,这里使用F1-score作为En.QA的评估指标。
EN.MC由224个问答对组成,其注释与En.QA类似,但每个问题提供四个答案供选择。
En.MC中的长上下文平均包含142,622个单词,这里使用准确性作为En.QA评估的指标。
所有数据集上的块大小都设置为128个token,块之间不重叠,使用BGE-large-en-v1.5的默认设置来获得查询和块的嵌入。
作者评估了上下文长度对OP-RAG性能的影响。实验中每个块包含128个token,生成答案时检索块数为128。
如下图所示,随着上下文长度的增加,性能最初会提高。这是因为更多的上下文可能有更大的机会覆盖相关的块。
然而,随着上下文长度进一步增加,答案质量会下降,因为更多不相关的块产生了干扰。
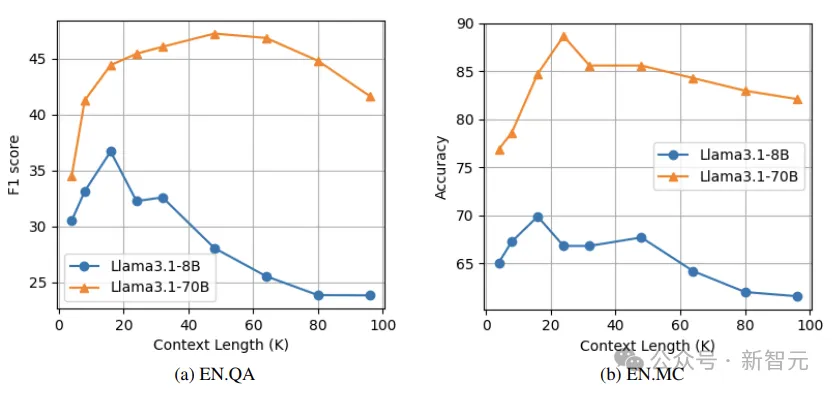
实验中的Llama3.1-8B模型,在EN.QA数据集和EN.MC数据集上,上下文长度为16K时达到性能峰值,而Llama3.1-70B模型在EN.QA上的最佳性能点为16K,在EN.MC上为32K。
Llama3.1-70B的峰值点晚于Llama3.1-8B,可能是因为较大规模的模型具有更强的区分相关块和不相关干扰的能力。
这里有两方面的启示,首先是需要在检索更多上下文来提高召回率,和限制干扰来保持准确性之间进行权衡;
其次,引入过多的不相关信息会降低模型的性能,这也是当前长上下文LLM所面临的问题。
如下图所示,当检索到的块的数量较小(比如8)时,本文提出的保留顺序RAG相对于普通RAG的优势并不明显。
而当检索到的块数量很大时,OP-RAG的性能显著优于普通RAG。
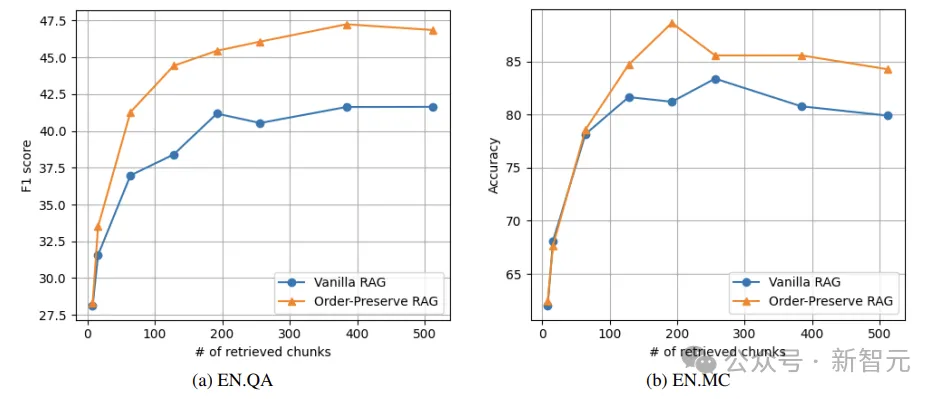
在EN.QA数据集上,当检索到的块数为128时, 普通RAG只能实现38.40的F1-score,而OP-RAG获得了44.43分。
在EN.MC数据集上,检索块数为192时,普通RAG的Accuracy为81.22,而OP-RAG达到了88.65。
研究人员将OP-RAG与两种类型的基线进行比较。
第一类方法使用没有RAG的长上下文LLM。如下表所示,在没有RAG的情况下,LLM需要大量token作为输入,效率低且成本高。
相比之下,本文的保序RAG不仅显著减少了所需token数量,而且提高了答案质量。
对于Llama3.1-70B模型,没有RAG的方法在EN.QA数据集上,只能实现34.26的F1-score,且平均需要117K个token作为输入。相比之下,OP-RAG以48K个token的输入获得了47.25的分数。
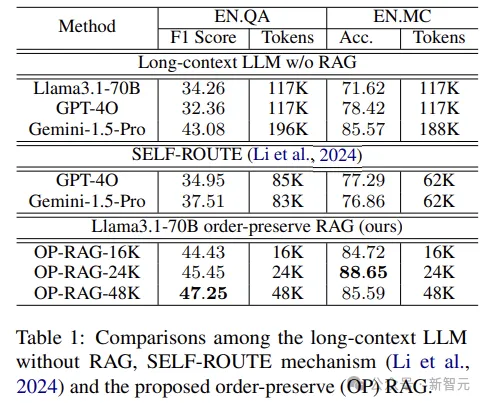
第二类基线采用SELF-ROUTE机制 ,它根据模型自我反思将查询路由到RAG或长上下文LLM 。如上表所示,OP-RAG方法明显优于在LLM的输入中使用更少token的方法。
参考资料:
https://arxiv.org/pdf/2409.01666
文章来自于微信公众号“新智元”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
