# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
计算机科学、数学、自然科学、医学、语言学、社会科学……OpenAI o1擅长什么?还有哪些不足?
OpenAI 的 o1-preview 模型已经发布两周了,网上也有了很多零星的测评。不过,大部分测评都侧重于某一个方面,对于 o1-preview 的系统评估目前还比较匮乏。
在一篇长达 280 页的论文中,来自加拿大阿尔伯塔大学等机构的研究者报告了他们对 o1-preview 的系统评估结果,非常具有参考价值。

具体来说,这项综合研究评估了 o1-preview 在各种复杂推理任务中的性能,涵盖多个领域,包括计算机科学、数学、自然科学、医学、语言学和社会科学。通过严格的测试,o1-preview 展示了非凡的能力。
主要结论如下:
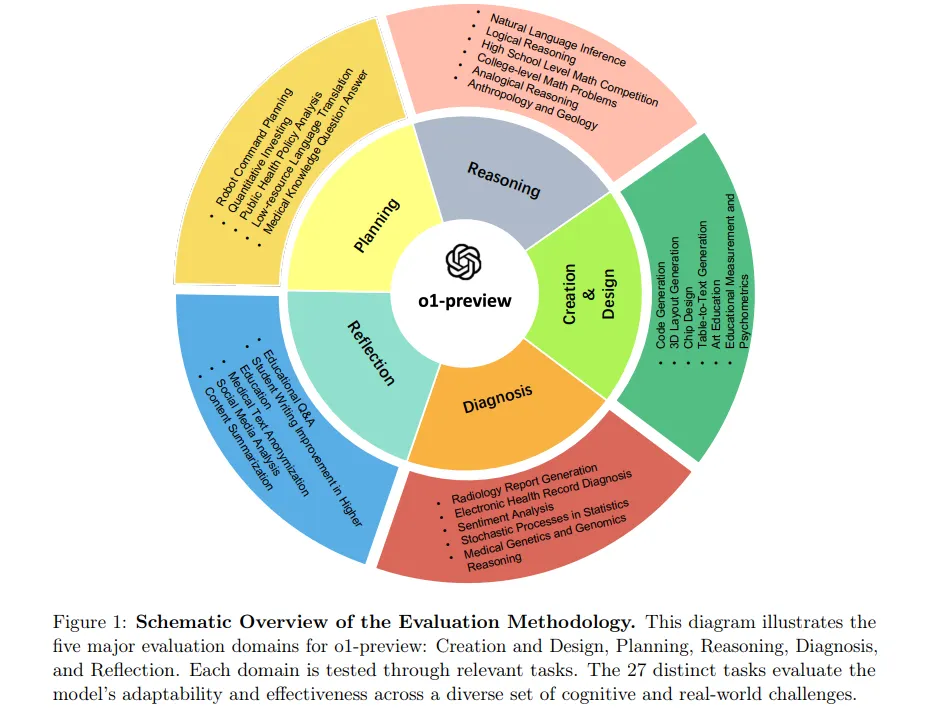
尽管 o1-preview 在一些简单的问题上偶尔会出现错误,并且在某些高度专业的概念面前遇到了挑战,但总体结果表明,该模型在向通用人工智能(AGI)迈进的过程中取得了显著进展。
评估不仅突显了 o1-preview 目前的优势和局限性,还指出了未来发展的关键领域,如多模态集成、特定领域的验证和实际应用中的伦理考虑。这些发现为大型语言模型在众多领域的潜力提供了宝贵的见解,并为 AI 研究和应用的进一步发展铺平了道路。
论文目录如下:


以下是论文中的部分结果展示。
代码生成
为了评估 o1-preview 的编码能力,作者在 Leetcode 竞赛环境中对其性能进行了扩展测试。
如表 2 所示,o1-preview 成功通过了 12 个问题中的 10 个,通过率高达 83.3%。该模型在 Weekly Contest 413 中只答错了一个问题,在 Biweekly Contest 138 中又答错了一个问题。值得注意的是,这两个问题都被归类为「hard」级别。虽然花了几分钟才能生成解决方案,但 o1-preview 无法在三次提交尝试中通过这些挑战。

尽管存在这些挑战,但与顶级人类竞争者相比,01 -preview 展示了相当或更快的代码生成速度。这说明 01 -preview 具有较强的推理能力,可以有效处理大部分的编码任务。然而,在特别复杂或计算密集的情况下,模型的性能仍然有限,正如在这些困难的问题中观察到的那样。
图 3 和图 4 演示了编码评估中的两个示例。在图 3 中,01 -preview 展示了它有效解决简单问题的能力,用最少的计算时间完成任务并成功通过所有测试用例。然而,如图 4 所示,该模型遇到了一个难题。在这个失败案例中,01 -preview 最初生成了一个正确的解决方案,但是解决方案超出了时间限制。在第一次提交之后,模型陷入了试图优化代码时间复杂度的循环中,这在随后的尝试中导致了不正确的解决方案。这个例子突出了该模型在处理需要显著优化的复杂问题时的挣扎,它为提高效率所做的努力导致了重复的错误。


放射学报告生成
为了评估 o1-preview 的医学报告生成能力,作者使用了来自中南大学湘雅二医院的中文放射学报告数据集 SXY。它包含 317,339 份放射学报告,分为五个类别:胸部报告、腹部报告、肌肉骨骼报告、头部报告和头颈面部报告。
作者通过比较 o1-preview 与基线模型(如 gpt-4-turbo、gpt-4o 等)的 ROUGE 指标,评估了 o1-preview 生成医学报告的能力。表 3 提供了 o1-preview 与另外五种模型的详细性能对比。
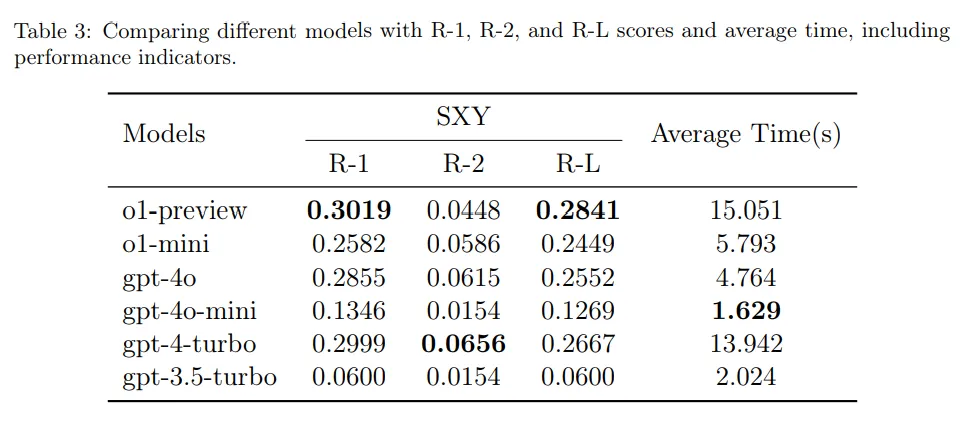
如表 3 所示,与医生撰写的报告相比,o1-preview 生成的报告的 ROUGE 评分为:R-1: 0.3019, R-2: 0.0448, R-L: 0.2841,在 6 种模型中排名最高。值得注意的是,o1-preview 的平均报告生成时间也最长,为 15.051 秒。
图 5 和图 6 展示了两个例子,说明了作者对放射学报告生成的评估结果。在评估过程中,o1-preview 展示了在零样本情况下快速生成可靠放射学报告的能力,突显了其强大的推理和知识迁移能力,以及在医疗领域的潜力。作者观察到,o1-preview 的报告与人类写作模式高度一致,结构清晰,语言简洁。尽管其他模型未能达到最高的相似度分数,但大多数模型能够遵循指令并完成任务。


自然语言推理
在本节中,作者评估 o1-preview 在自然语言推理(NLI)任务上的表现。NLI 任务涉及确定两个句子之间的逻辑关系,结构化为一个分类任务,其中第二个句子要么从第一个句子逻辑上推导出来,要么与第一个句子矛盾,要么是中立的(可能是真实的)。
作者从每个数据集的测试集中随机抽取两个测试样本,共进行 10 个测试用例。表 4 给出了每个数据集的示例,其中 01 -preview 准确地分析了逻辑关系,展示了高级推理能力和特定于领域的知识。这展示了它在各种复杂场景中的实际应用的潜力。

芯片设计
o1-preview 在芯片设计中的实验涵盖工程助手聊天机器人、EDA 脚本生成和错误总结分析三大关键任务,展示了其在技术咨询、代码生成和错误检测方面的强大能力。这些应用不仅有望彻底改变半导体行业,减少时间和错误成本,优化设计性能,还标志着向实现通用人工智能(AGI)的重要迈进,证明了 AI 在处理复杂、高风险专业任务中的潜力。
在评估 o1-preview 作为工程助手聊天机器人的表现时,作者发现其在多个任务中展现出比 ChipNeMo 更高级的解决问题能力。比如在第一个例子中(图 21),询问如何使用 testgen 框架运行多个随机测试种子。ChipNeMo 的回应虽然功能正确,但较为基础,缺乏对大规模模拟优化的深入见解。相比之下,o1-preview 不仅覆盖了基本配置步骤,还详细解释了如何并行化测试过程,确保测试的随机性和可扩展性,展示了更高水平的专业知识,特别是在处理大规模模拟中的随机数生成完整性和错误处理等关键问题上。

在 EDA 脚本生成任务中,作者测试了 o1-preview 和 ChipNeMo 生成 EDA 工具脚本的能力。
在图 24 所示的第一个例子中,任务是编写 TOOL1 代码来统计给定矩形边界内的触发器单元数量,这是物理设计中常见的操作,用于确定逻辑分布和优化布局。ChipNeMo 的回应提供了一个基本的解决方案,涵盖了如何遍历设计层次结构并在指定区域内计数触发器的基本机制。虽然其结构和功能正确,但灵活性有限,未涉及处理边缘情况(如重叠区域或边界条件)或优化搜索算法以适应更大设计的高级特性,这些在生产环境中是至关重要的。
相比之下,o1-preview 的回应更为细致。除了提供核心代码外,o1-preview 还讨论了潜在的优化策略,如如何高效遍历大型设计和更优雅地处理边界条件。此外,o1-preview 还包括了扩展功能的注释和建议,如添加计数其他类型单元的功能或将脚本集成到更大的设计规则检查自动化流程中。这一回应展示了对实际 EDA 环境中复杂性的深刻理解,强调了灵活性和可扩展性的重要性。o1-preview 能够预见工程师在大规模设计中部署此脚本时可能遇到的问题,使其回应在专业环境中更具实用性。


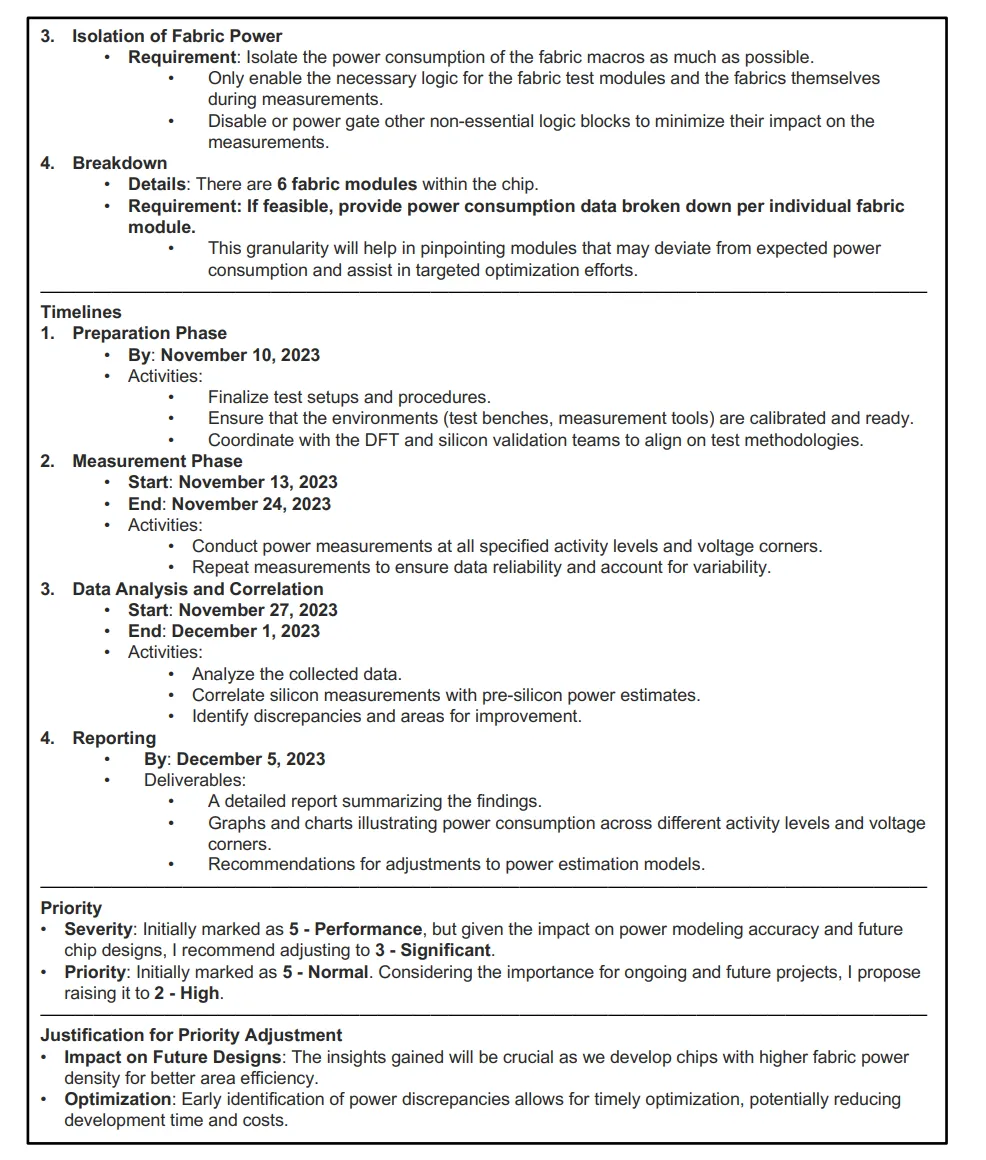
在 Bug Summary & Analysis 任务中,作者测试了 o1-preview 和 ChipNeMo 分析与芯片布线电流测量相关的错误报告的能力,这是一个在芯片功率优化中至关重要的任务。半导体设计中的错误分析不仅涉及识别问题的根本原因,还需要以一种使团队能够高效优先处理和解决的方式总结问题。
ChipNeMo 的技术总结详细列出了功耗测量的条件,如测试模块的活动百分比和所需的电压角。管理总结仅传达了用户之间的讨论,没有深入分析或提供明确的行动计划。ChipNeMo 的回应主要集中在总结错误报告的即时事实,缺乏对功耗测量对未来设计影响的深入分析,也没有提出将硅数据与预硅估计相关联的策略。
相比之下,o1-preview 不仅涵盖了与 ChipNeMo 相同的技术和管理方面,还深入分析了功耗测量的更广泛影响。它讨论了布线功耗数据如何影响未来的芯片设计,特别是优化功耗密度和提高面积效率,这些因素在现代芯片开发中至关重要。
此外,o1-preview 提供了更详细的请求解读,建议使用更精细的隔离技术和数据分解方法。它还提供了一个更清晰的任务分配框架,确保工程团队能够优先处理任务,并设定具体的时间表和里程碑,以隔离和测量布线宏单元的功耗。


高中数学推理
为了调查 o1-preview 的数学性能,作者设计了一系列涵盖不同难度级别的测试。本节首先从高中数学竞赛题目开始,随后在下一节中涉及大学水平的数学问题,以便观察模型在不同复杂度层次上的逻辑推理能力。
在本节中,作者选择了两个主要的数学领域:代数和计数与概率。选择这两个领域是因为它们高度依赖于问题解决技能,并且常用于评估逻辑和抽象思维。
具体来说,作者进行了 10 项测试,包括 5 个代数问题和 5 个计数与概率问题,难度等级从 1 到 5 不等。o1-preview 表现出色,所有 10 个测试案例均达到了 100% 的准确率。这一稳定的表现表明,它能够处理从简单到复杂的各类数学问题。除了提供正确的最终答案外,o1-preview 的解决方案还详细地展示了每一步的推理过程,这些步骤与参考答案中的关键步骤一致。这种详细的解答方式表明,模型在数学领域的逻辑推理能力已接近人类水平。
以下是一些测试案例:


大学数学推理
本节中的问题由作者手动创建。这些问题因其高度的抽象性和所需的复杂推理而特别具有挑战性。这些问题可以大致分为以下几类:
表 5 列出了 o1-preview 在各类问题中的答题情况。
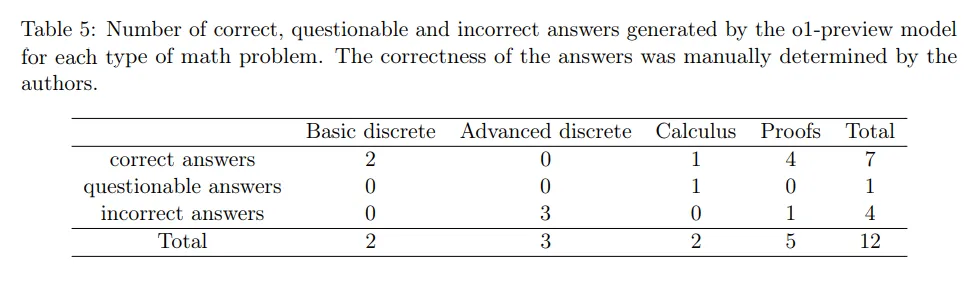
总的来看,o1-preview 在大学数学推理中表现出了以下优点:
但同时,他们也观察到了一些局限性:
作者在论文中针对很多问题都给出了详细分析。
结论
作者对 o1-preview 在不同领域的全面评估揭示了几个主要观点:
文章来源于“机器之心”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
