# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 OpenAI GPT-4o 的发布,大语言模型已经不再局限于文本处理,而是向着全模态智能助手的方向发展。这篇论文提出了 EMOVA(EMotionally Omni-present Voice Assistant),一个能够同时处理图像、文本和语音模态,能看、能听、会说的多模态全能助手,并通过情感控制,拥有更加人性化的交流能力。以下,我们将深入了解 EMOVA 的研究背景、模型架构和实验效果。
近年来,多模态大模型得到广泛关注,尤其是可以同时处理视觉和语言信息的模型,如 LLaVA [1] 和 Intern-VL [2],或者语音文本交互的模型,如 Mini-Omni [3]。然而,当前的研究多偏向于双模态组合,要让大语言模型在 “看、听、说” 三个方面同时具备优越表现依然充满挑战。传统的解决方案往往依赖外部语音生成工具,无法实现真正的端到端语音对话。而 EMOVA 的出现填补了这个空白,在保持图文理解性能不下降的前提下,让模型具备情感丰富的语音交流能力,实现了一个全能型、情感丰富、能看能听会说的智能助手。
EMOVA 的架构如图一所示,它结合了连续的视觉编码器和离散的语音分词器,能够将输入的图像、文本和语音信息进行高效处理,并端到端生成文本和带情感的语音输出。以下是其架构的几个关键点:
1. 视觉编码器:采用连续的视觉编码器,捕捉图像的精细视觉特征,保证领先的视觉语言理解性能;
2. 语音分词器:采用了语义声学分离的语音分词器,将输入的语音分解为语义内容(语音所表达的意思)和声学风格(语音的情感、音调等)。这种设计将语音输入转化为 “新的语言”,不仅降低了语音模态的合入难度,更为后续个性化语音生成以及情感注入提供了灵活度;
3. 情感控制模块:引入了一个轻量级的风格模块,支持对语音情感(如开心、悲伤等)、说话人特征(如性别)、语速、音调的控制,在保持语义不变的情况下,根据对话上下文动态调节语音输出的风格,使人机交互更加自然。
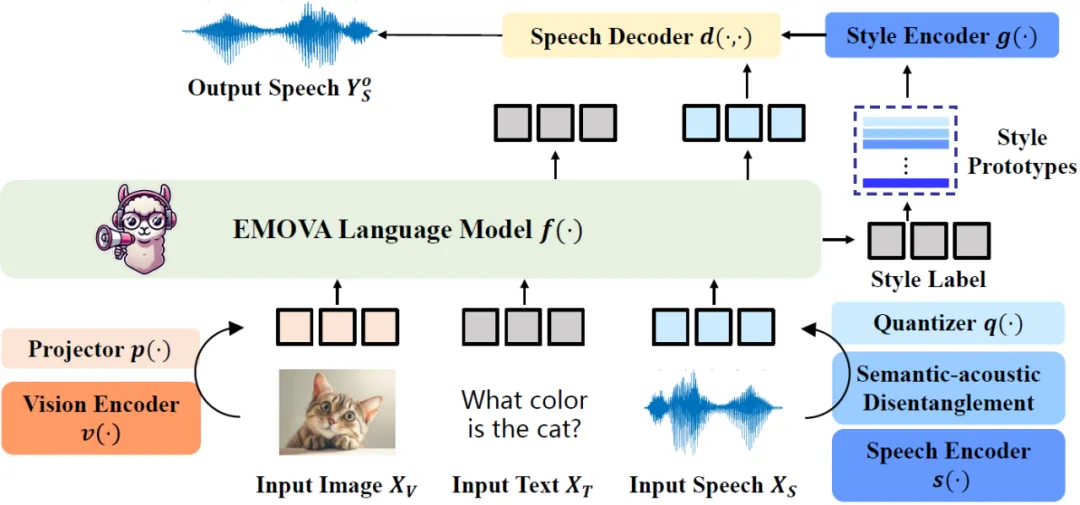
图一:EMOVA 模型架构
EMOVA 提出了数据高效的全模态对齐,以文本模态作为媒介,通过公开可用的图像文本和语音文本数据进行全模态训练,而不依赖稀缺的图像 - 文本 - 语音三模态数据。实验发现:
1. 模态间的相互促进:在解耦语义和声学特征的基础上,语音文本数据和图像文本不仅不会相互冲突,反而能够互相促进,同时提升模型在视觉语言和语音语言任务中的表现;
2. 同时对齐优于顺序对齐:联合对齐图像文本和语音文本数据的效果明显优于顺序对齐(先图像文本对齐,再语音文本对齐,或反之),有效避免 “灾难性遗忘”;
3. 全模态能力激发:少量多样化的全模态指令微调数据,可以有效激发模型面对图像、文本和语音组合指令的响应能力和遵从性。
这种双模态对齐方法利用了文本作为桥梁,避免了全模态图文音训练数据的匮乏问题,并通过联合优化,进一步增强了模型的跨模态能力。
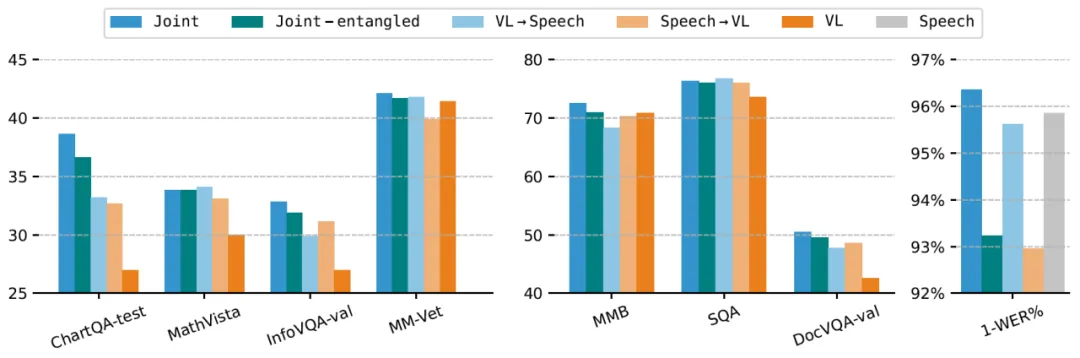
图二:全模态同时对齐提升模型在视觉语言和语音语言任务中的表现
在多个图像文本、语音文本的基准测试中,EMOVA 展现了优越的性能:
1. 视觉理解任务:EMOVA 在多个数据集上达到了当前的最佳水平,特别是在复杂的图像理解任务中表现尤为突出,如在 SEED-Image、OCR Bench 等榜单的性能甚至超过了 GPT-4o;
2. 语音任务:EMOVA 不仅在语音识别任务上取得最佳性能,还能生成情感丰富、自然流畅的语音,展示了其语义声学分离技术和情感控制模块的有效性;
总的来说,EMOVA 是首个能够在保持视觉文本和语音文本性能领先的同时,支持带有情感的语音对话的模型。这使得它不仅可以在多模态理解场景表现出色,还能够根据用户的需求调整情感风格,提升交互体验。
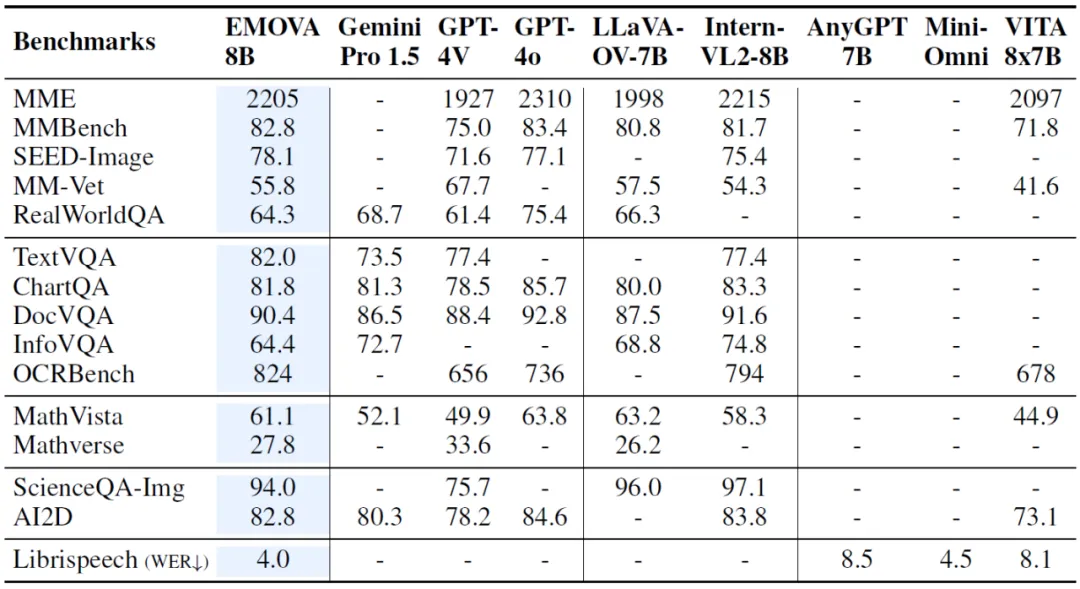
图 3 EMOVA 在视觉文本和语音文本任务上的性能测试
EMOVA 作为一个全模态的情感语音助手,实现了端到端的语音、图像、文本处理,并通过创新的语义声学分离和轻量化的情感控制模块,展现出优越的性能。无论是在实际应用还是研究前沿,EMOVA 都展现出了巨大的潜力,为未来 AI 具备更加人性化的情感表达提供的新的实现思路。
参考文献:
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2024). Visual instruction tuning. In NeurIPS.
[2] Chen, Z., Wu, J., et al. (2024). InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR.
[3] Xie, Z., & Wu, C. (2024). Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming. arXiv preprint arXiv:2408.16725.
文章来自于微信公众号“机器之心”.



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
