# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM依然不会规划,LRM可以吗?
OpenAI声称,草莓o1已经突破了自回归LLM常规限制,成为一种新型的「大推理模型」(LRM)。
它能够基于强化学习,通过CoT多步推理。并且,这种推理过程的代价,是高昂的。
来自ASU研究人员以此为契机,全面评估了当前LLM和新型LRM,在测试基准PlanBench上表现。

论文地址:https://arxiv.org/pdf/2409.13373
PlanBench是他们在22年提出,评估大模型规划能力的测试基准。
在最新测试中,研究人员发现,o1-preview表现出色,大幅领先其他模型,但也未完全通过PlanBench基准测试。
其他LLM,在Mystery Blocksworld上的性能都不过5%。在基准上的结果曲线,和X轴几乎融合。
足见,这些大模型的规划能力,非常地弱。
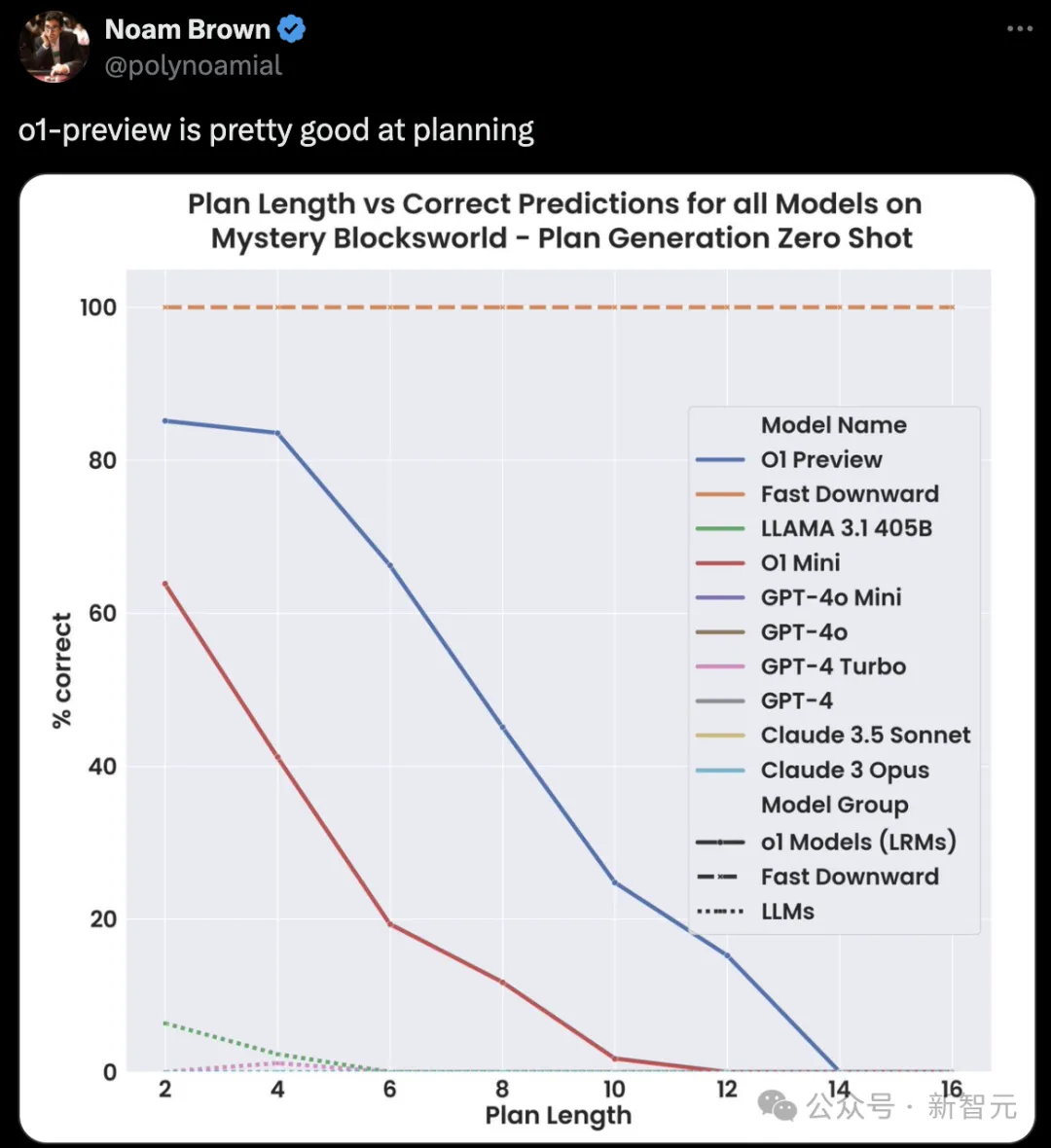
不过,作者指出,规划推理越长,o1-preview的准确率便会低于25%。
另外一个值得注意的点是,即便o1-preview超越了多数近似检索的普通LLM,成为一种近似「推理器」。
但是,这种推理成本高达42美元/100个实例。

总而言之,o1在推理规划方面开辟了新天地,但仍旧不是终极AI大脑。
作者认为,o1模型以往LLM很大不同在于,前者被训练成为近似「推理器」,而后者粗略视为「检索器」。
由此,o1发布之后,研究人员对其与普通的LLM进行了区分,并将o1称为「大推理模型」。
而要评估新模型的能力,以及局限性,还需要新的工具和评估方法。
PlanBench是在2022年GPT-3发布不久之后,亮相arXiv。此后,作者也在一个特定子集上(包含600个3-5 block问题的静态数据集),重新测试模型。
尽管相继出现的LLM参数规模越来越大,算力成本越来越高,但它们在简单的规划问题上,依旧无法实现饱和。
而且,多项研究中的改进并不稳健,可推广力没有那么高。
因此,PlanBench可以作为LLM和LRM在推理规划任务上,是否取得进步的一个衡量标准。
不过需要注意的是,这种测试只能作为性能的上限,尤其局限于静态测试集。
如下表1中,展示了当前大模型在600个3-5 Blocksworld静态问题测试集,以及600个语义相同但语法混淆的实例Mystery Blocksworld中的结果。
在这些模型中,Llama 3.1 405B在常规Blocksworld上,取得了最佳性能62.6%。
然而,尽管本质问题相同,许多模型在Mystery Blocksworld上,性能大打折扣几乎溃败。
没有一个模型,在PlanBench测试集中,达到5%的性能。
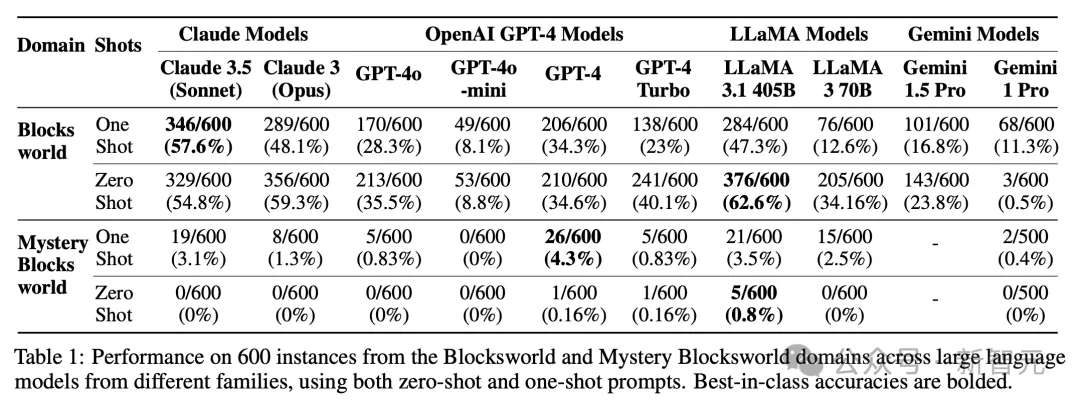
这是因为,LLM非常擅长提供等效表征之间的转换。
因此,大模型在Blocksworld未混淆语义语法的问题上,性能更高。这也预示着,如果LLM能够组合推理操作,明确提供从Mystery Blocksworld到Blocksworld表征翻译,或许LLM在此的性能差距应该会大幅缩小。
通过重写提示,研究人员发现,性能仅是提高了很小一部分—— GPT-4达到了10%。

作者还发现,与之前结果相反,单样本提示(one-shot)相较于零样本,并没有显著改善模型性能。
事实上,在许多模型中,one-shot效果似乎要差得多!
这一点,在对Llama系列模型的测试中,最为明显。
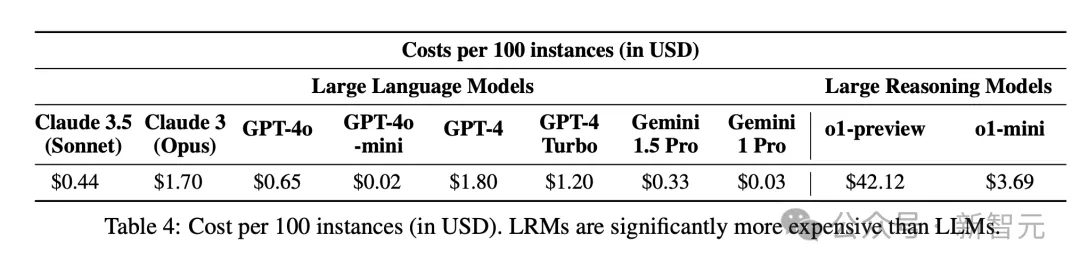
顺便提一句,在起初基准迭代中,研究人员并没有考虑效率问题,因为普通LLM生成某些输出,所需时间只取决于输出长度,与实例的语义内容、难度无关。
然而,LRM会根据输入内容,自适应改变每个实例所需的时间和成本,因此衡量计算效率变得尤为重要。
对此,ASU团队计算了不同模型的提示成本,如下表4所示。
看得出,100个实例,o1-preview推理的代价最高,为42.12美金。
接下来,就到了评估o1在PlanBench基准上的能力了。
很多研究者都曾认为,通过近似检索来生成输出的「标准」自回归LLM,尽管能够在一系列系统1(快速、直觉性思考)任务中有着优异的表现,但不太可能具备更类似于系统2(慢速、分析性思考)的近似推理能力,而这种能力对于规划任务来说至关重要。
如今,OpenAI试图在o1上以不同的方式为底层LLM增添类似系统2的能力。
根据研究人员的推测,o1将底层LLM(很可能是经过修改的GPT-4o)与一个经过强化学习训练的系统相结合,该系统引导思维链推理轨迹的创建、整理和最终选择。
由此可知,o1与其他LLM存在两个主要区别:
第一,新增了一个额外的强化学习预训练阶段(可能是从大量合成数据中学习不同思维链的q值);
第二,采用了一个新的自适应扩展推理程序(可能是通过类似rollout的方式进一步细化学习到的q值,然后再选择特定的思维链)。
不管怎样,从已知的细节来看,这个模型在本质上与之前的LLM有根本的差异。
在需要2到16步计划来解决的原始Blocksworld测试上,o1实现了高达97.8%的正确率。在Mystery Blocksworld上,也有着52.8%的正确率。
更进一步,研究人员通过完全随机的字符串生成了新的混淆,并以此得到了难度更高的Randomized Mystery Blocksworld。
在这个测试中,o1仍能答对37.3%的问题——与那些一题都答不上来的LLM形成了鲜明对比。
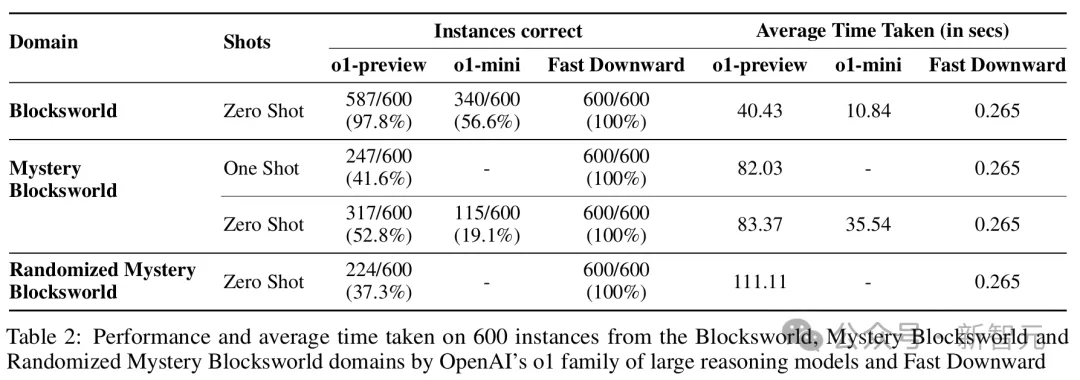
LLM的思维链提示是非常脆弱的,很难随着问题规模的增大而稳健地扩展,而且不能诱导出通用的算法程序跟随。
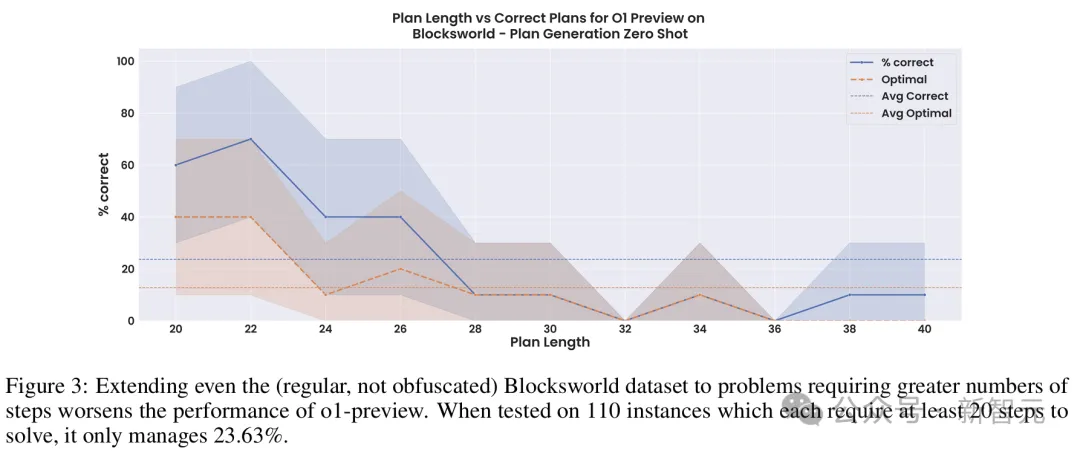
为此,研究人员构建了一组有着110个实例的Blocksworld测试。其中,block的数量从6到20个不等,需要20到40步计划才能完成。
在不做任何混淆处理的情况下,o1-preview仅仅达到了23.63%的准确率,而且大部分都是来自于那些需要少于28步的问题。
可见,模型的性能还远未达到稳健的程度。
一直以来,LLM都难以判断一个问题是否有解,而OpenAI则声称o1已经能够进行准确地识别了。
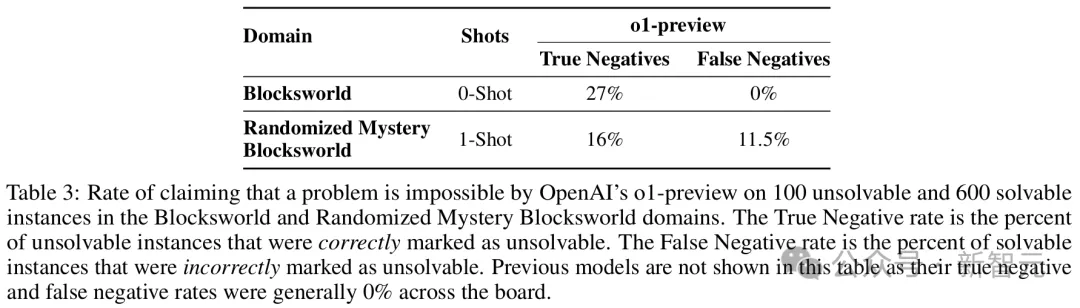
为了系统地测试这一点,研究人员修改了原始测试集中的100个实例——通过在每个实例的目标状态中添加一个on(x,y)类型的连接词,使目标变得不可满足。
结果显示,在Blocksworld中,o1只正确且明确地识别出了27%的实例是不可解的。
在19%的情况下,模型会返回一个点或某种「[empty plan]」标记,但没有对可解性做出任何解释或说明。这是不正确的,因为「empty plan」只有在目标已经满足的情况下才是正确答案。
在剩余的54%的情况下,模型生成了一个「完整」的计划。显然,这是不可能也是不正确的。
在Randomized Mystery Blocksworld中,结果更糟:
- 16%的情况正确识别出了问题不可解
- 5%的情况返回了「empty plan」
- 79%的情况给出了一个不可能或不满足目标的计划
可见,不可解实例仍然是LRM的一个问题。
不仅如此,这种识别能力也是有代价的——o1有时会错误地声称可解的问题是不可解的(假阴性)。
在Randomized Mystery Blocksworld中,模型的假阴性率达到了11.5%。
随着LRM在规划任务上取得更好的性能,评估也必须明确考虑,选择通用模型而非成熟专门系统来带的利弊。
虽然o1-preview准确性超越LLM,但缺乏的是正确性保证。
而且,目前尚不清楚它是否具备成本效益。
与之前模型不同的是,o1 API每次调用价格还包括基于使用「推理token」数量附加费用,并按照最高输出token计费。(这些token是在推理过程中生成,并没有直观展示出来)

这也就意味着,o1 API费用用户是无法控制的。
作者表示,o1推出不到一周,他们在PlanBench基准上测试模型,竟花费了1897.55大洋(约13300元)!
而且,能够访问的o1-preview似乎在每个问题上,使用的推理token数量受到限制。
这一点也可以从图2的平稳变化中,可以看出。(包括如下散点图)
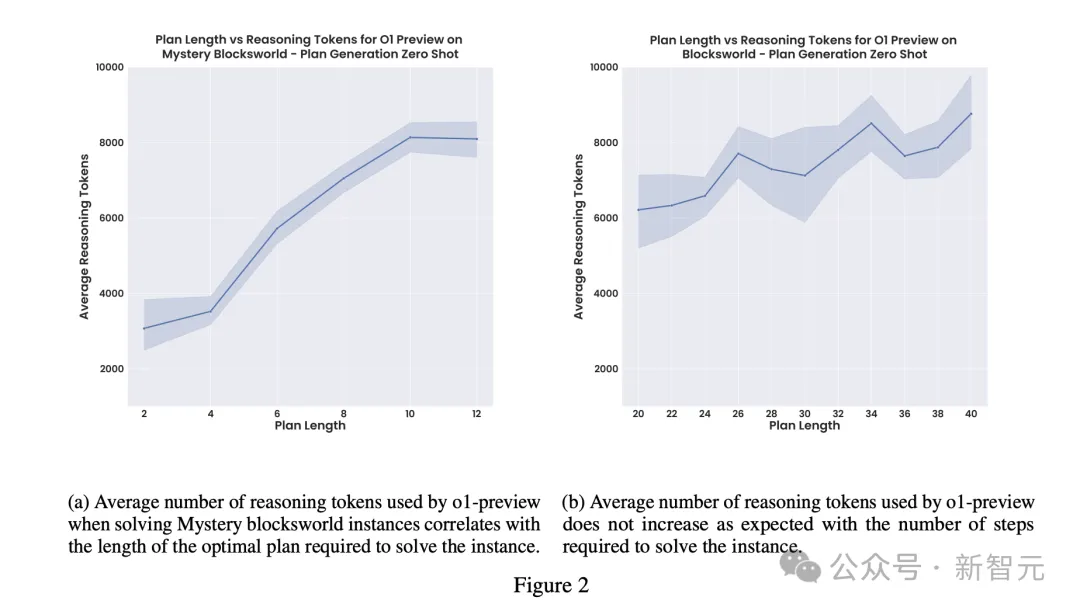
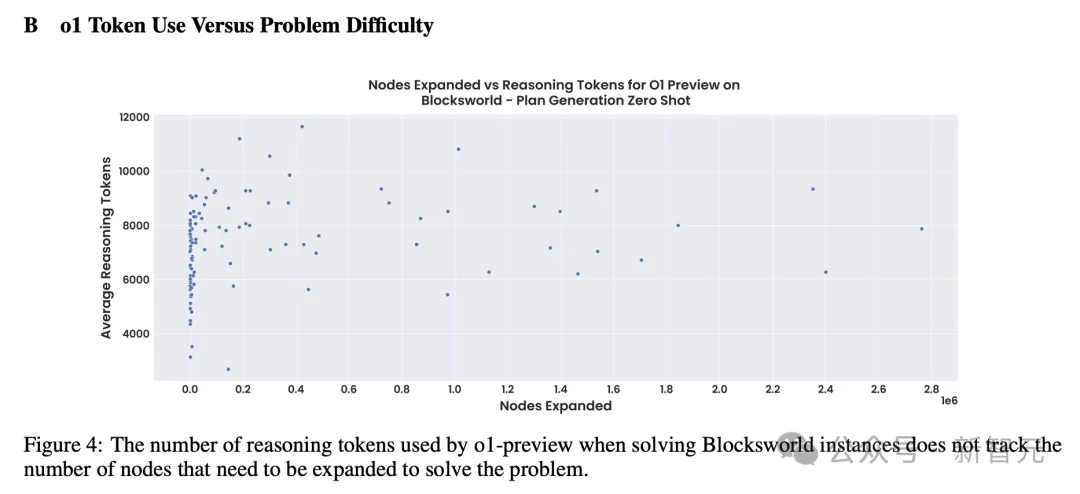
这就存在一种认为降低总成本,最高性能的因素。
如果完整版o1取消这一限制后,可能会提高整体准确性,但随之带来的高昂推理成本更加难以预测(只会更加离谱)。
o1-mini虽然更具性价比,但总体性能还是较差。
由此,o1模型在成本、推理时间、保证、性能权衡上,仅是一种粗粒度的评估选择。
经典的规划器Fast Downward在数据集上,能够以更少时间、计算、成本,实现了100%准确率,同时能够保证答案准确度。
而在PC上运行Fast Downward基本上不需要花什么钱,平均每个实例耗时0.265秒。这要比如上表2中,o1平均时间快了几个数量级。
它通常也是可预测的,而且能直接扩展到更难的实例。
普通LLM非常擅长在不同格式之间转换问题,并可以结合Fast Downward一起使用,成本还仅是LRM一小部分。
对于没有简单PDDL域和实例规范的问题,LLM-Modulo系统可能是一种更安全、更便宜的方法。
即将一个较小、较快的LLM与一个可靠的验证器循环运行,使得组合系统只输出保证正确的解决方案。
后面这两种方法提供正确性保证,却在o1这样的LRM中严重缺失。
如果一个通过那个推理AI非常自信地制定错误计划,就不能部署在安全关键和非遍历领域。
当前,o1还是一个完全黑盒系统,要比之前模型更甚。OpenAI不仅保密其架构和推理过程,还警告禁止想要了解内部机制的用户。
这也就让o1的可解释性变为不可能,也降低了整个系统信任度。
值得一提的是,当模型给出错误答案时,它有时还会为其决定提供一个富有创意但毫无意义的解释。
换句话说就是,o1从产生幻觉变成了PUA……
在一个案例中,它认为一个无法解决的问题是可以解决的,因为一个目标条件虽然在最终状态中不存在,但在执行过程中的某个时点是真的,因此应该继续计算。
在另一个案例中,它宣称on(a,c)是真的,因为正如「on(a,c)」的字面意思,a在b上,而b在c上,因此a在c的「上方」。
结论
总结而言,LLM在原始Blocksworld测试集上的表现,会随着时间的推移有所提升。
其中,表现最佳的是Llama 3.1 405B——准确率高达62.5%。
然而,这些模型在同一领域的混淆版本上的糟糕表现,暴露了它们「近似检索」的本质。
相比之下,新的LRM,也就是o1,不仅几乎接近完美解决了原始Blockworld测试集,而且在混淆版本上首次取得了进展。
受此鼓舞,研究人员又评估了o1在更长问题和无解问题上的表现。
但结果显示,之前这些准确率的提升既不具有泛化性,也不具有稳健性。
最后,团队希望这份研究报告能够很好地展示LLM和LRM的规划能力,并为如何切实评估它们提供有用的建议。
参考资料:
https://arxiv.org/abs/2409.13373
文章来自于微信公众号“新智元”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
