# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
毫无预兆地,Meta版Sora——Movie Gen,就在刚刚抢先上线了!
Meta将其称为「迄今最先进的媒体基础模型」。

全新上线的大杀器Movie Gen Video,是一个30B参数的Transformer模型,可以从单个文本提示,生成高质量的高清图像和视频,视频为1080P、16秒、每秒16帧。

一同推出的还有Movie Gen Audio。这是一个13B参数的Transformer模型。通过视频输入和文本提示,它就可以可控性生成和视频同步的高保真音频,时长最长45秒。
最惊人的是,这次Meta一并连论文都发布了。

论文中,详细介绍了Movie Gen的架构、训练方法和实验结果。

论文地址:https://ai.meta.com/static-resource/movie-gen-research-paper/?utm_source=twitter&utm_medium=organic_social&utm_content=thread&utm_campaign=moviegen
从论文可以看出,Movie Gen Video沿用了Transformer的设计,尤其借鉴了Llama 3。而研究人员引入的「流匹配」(Flow Matching),让视频在精度和细节表现上,都优于扩散模型。
稍显遗憾的是,这次Meta发的也是「期货」,产品预计明年才正式向公众开放。
不出意外的,围观群众给出亮眼点评:「Meta居然抢着OpenAI之前发布了Sora,呵呵」。
就在昨天,Sora负责人Tim Brooks选择离职,Meta这个时间点放出Movie Gen,也真是够扎心的。
而HuggingFace工程师也直接贴出Meta开源主页,在线催更模型开源。
也有人期待,Meta版Sora的这次发布,或许或激出其他家的下一个王炸级产品。

凭借开源Movie Gen,Meta正式进军AI视频领域。
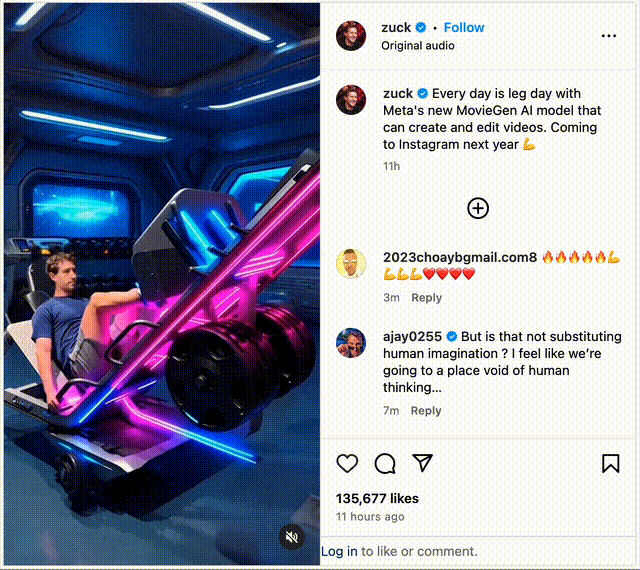
可以说,Movie Gen在编辑、个性化功能方面,站在了一个新阶段。而且,最令人印象深刻的,便是把一张个人照,转换成个性化视频。
小扎在社交平台上以身试法,将自己照片作为输入,Movie Gen为其配上了健身的视频。

现在,只要使用简单的文本输入,就能生成自定义的视频了。
从官网放出的Demo可以看出,Meta所言不虚,Movie Gen的确可以说「为沉浸式AI内容」树立了新标准。
更为瞩目的是,Movie Gen可以创建不同宽高比的高清长视频。在业内,这属于首次!
这个「雷声大作,伴随着管弦乐曲」的视频,对于山石地貌和电闪雷鸣的刻画惊人的逼真,配乐更是恢弘激昂。

Thunder cracks loudly, with an orchestral music track.
一个小女孩拿着风筝跑过海滩,仿佛电影中的场景。

戴着粉色太阳镜躺在甜甜圈游泳圈上的树懒,视频中光影和水波都很自然。

在冒着热气的温泉中玩着小木船的白毛红脸猴,无论是热气、水面、猴子毛发还是水中怪石,都看不出破绽。

在海边耍着火圈的男人,视频完全符合prompt的要求,镜头、光影和氛围的刻画,已经达到了大片级画质。

各种超现实的场景,Movie Gen都能完美生成,比如这只毛茸茸的冲浪考拉。

而只要使用文本输入,就可以编辑现有视频。
Movie Gen可以支持非常精确的视频编辑,无论是样式、过渡,还是精细编辑。
通过文字输入,就能让小女孩向空中放飞的灯笼,变成一个气泡。

在沙地上跑步的男子,手中可以加上蓝色绒球,周围环境可以换成仙人掌沙漠,甚至可以让男子换上一身恐龙套装。

在观众席上观影的一对男女,可以让他们戴上3D眼镜、背景换成游乐园,甚至加上下雨的特效。

南极冰原上的企鹅可以穿上维多利亚式的衣服,背景可以加上遮阳伞和沙滩床,甚至整幅画面都能变成铅笔素描画。

并且,Movie Gen还有一个Sora没有的亮点——个性化视频!
只要上传我们想要的图像,它就可以由此生成个性化视频,保留人物的身份和动作。
输入这个女孩的照片,给出prompt,就能让她在南瓜地上戴着围巾喝咖啡。

让这名男子化身科学家,穿上实验服开始做实验。

一张照片,就能生成自己和爱犬在露台上的自拍视频。

甚至让自己在西部世界小镇中化身骑马的女牛仔,身后就是落基山脉。一秒走进大片不是梦!

Movie Gen还可以将视频、文本作为输入,并为视频生成音频。
它可让你创建和扩展视频音效、背景音乐或整个配乐。
比如,下面企鹅戏水的画面中,配上了AI生成的优美的管弦乐曲。

文本输入:A beautiful orchestral piece that evokes a sense of wonder
AI生成的烟花音效,也是如此地逼真。

文本输入:Whistling sounds, followed by a sharp explosion and loud crackling.
倾泻而下的瀑布和和雨水,站在高处遥望远方顿感壮观。

文本输入:Rain pours against the cliff and the person, with music playing in the background.
一条蛇在草地里缓慢前进,给人一种危机四伏的赶脚。

文本输入:Rustling leaves and snapping twigs, with an orchestral music track.
AI生成的背景音,很有山地摩托摩托竞赛那味儿了。

文本输入:ATV engine roars and accelerates, with guitar music.
还有溜滑板,配着动作,给出不同节奏的音效。

文本输入:Wheels spinning, and a slamming sound as the skateboard lands on concrete.
Movie Gen发布同时,Meta还祭出了92页的技术报告。值得一提的是,这次团队也被命名为「Movie Gen team」。

Pytorch之父Soumith Chintala表示,其中很多细节将会推动AI视频领域的发展。
接下来,一起看看Movie Gen得以实现的技术要点吧。

研究人员表示,Movie Gen主要是基于两种基础模型打造的,一个是Movie Gen Video,另一个是Movie Gen Audio。
Movie Gen Video参数有300亿,基础架构细节如下图所示。

它能够联合文本到图像和文本到视频的生成。
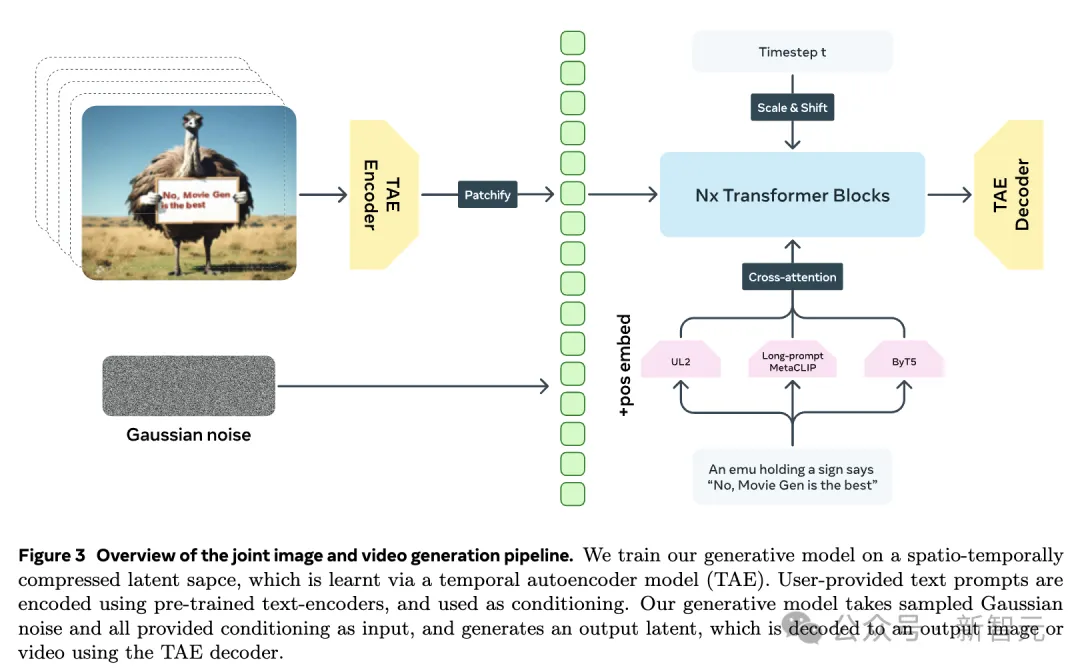
Movie Gen Video可以遵循文本提示,生成长达16秒、16帧每秒高清视频。
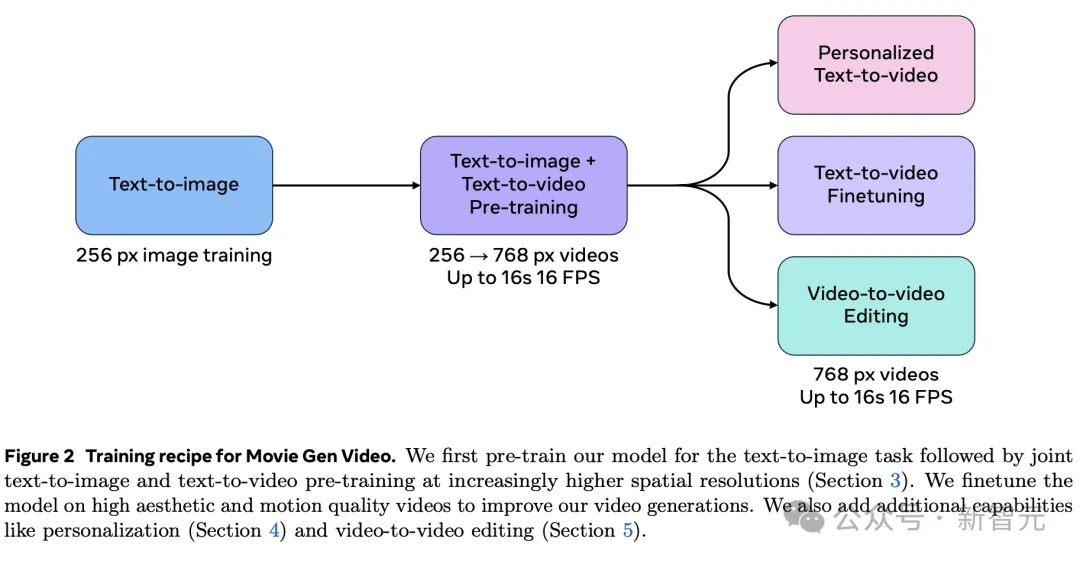
它也是通过预训练微调完成,在骨干网络架构上,它继续沿用了Transformer的设计,尤其是借鉴的Llama3的设计。
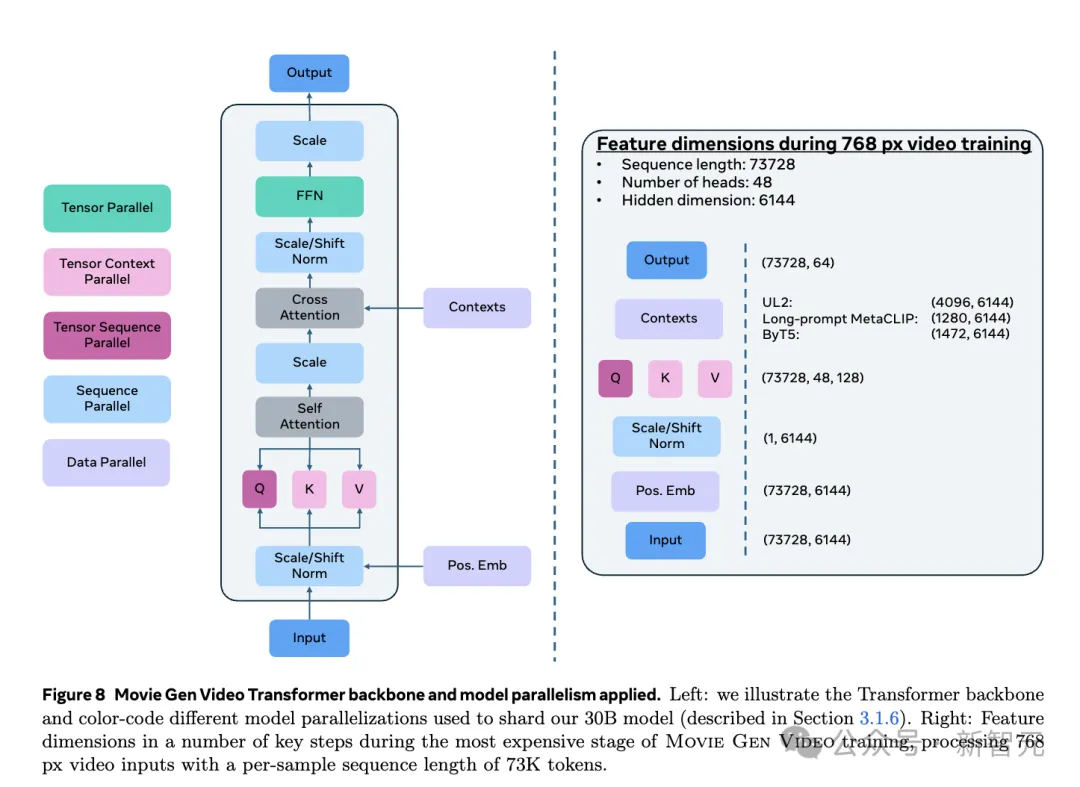
而且,该模型有强大的适应性,可生成不同纵横比、分辨率和时长的高质量图像和视频。
预训练阶段,在大约1亿个视频和10亿张图像上进行了联合预训练。
它是通过「看」视频,来学习视觉世界。
实验结果发现,Movie Gen Video模型能够理解物理世界——
可以推理物体运动、主-客体交互、几何关系、相机运动、物理规律,以及各种概念的合理运动。
在微调阶段,研究人员精选了一部分视频,对模型在美学、运动质量方面完成了微调。
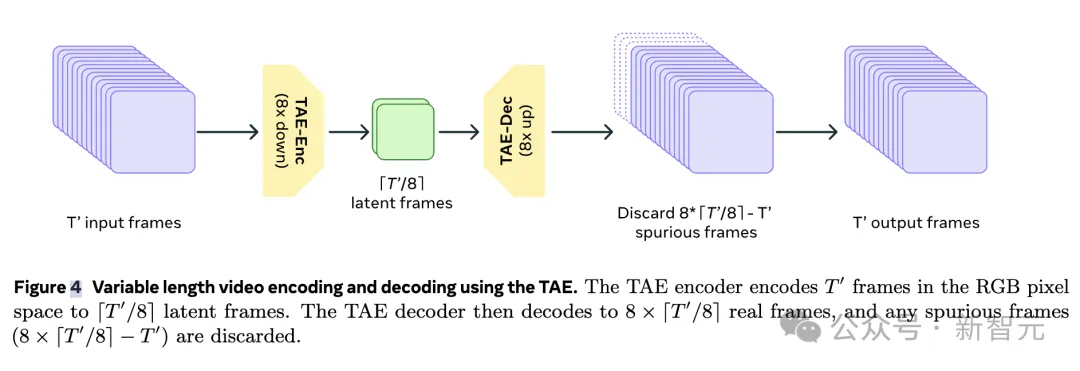
为了提高训练、推理效率,研究人员在时空压缩的潜在空间(Latent Space)中进行生成。
为此,他们训练了一个单一的时间自编码器(TAE),用于将RGB图像和视频映射到潜在空间。
然后,再使用预训练文本编码器,来编码用户提供的文本提示,并获得文本提示嵌入,这些嵌入用作模型的条件。
值得一提的是,研究人员还引入「流匹配」(Flow Matching)来训练生成模型,这使得视频生成效果在精度、细节表现上,都优于扩散模型。
「流匹配」是一种新兴的生成模型训练方法,其核心思想是——直接学习样本从初始噪声状态向目标数据分布转化的过程。
而且,模型只需通过估计如何在每个时间步中演化样本,即可生成高质量的结果。
与扩散模型相比,「流匹配」训练效率更高、计算成本更低、并且在时间维度保持连续性和一致性。

有网友对此总结道,在质量和文本对齐上,人类评估都强烈倾向于流匹配,而不是扩散。

此外,Movie Gen Video在技术上也引入了很多创新:
他们引入了创新的位置编码方法——「因子化可学习编码」,能够独立对高度、宽度、时间三个维度进行编码,然后将其相加。
基于这种灵活设计,让模型不仅能够适应不同宽高比,还能处理任意长度的视频。
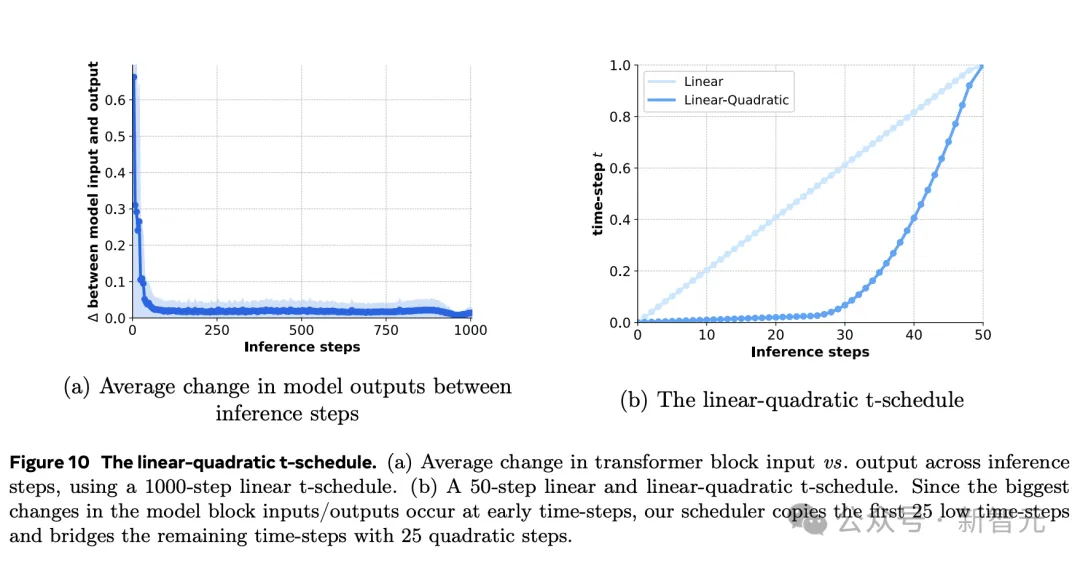
另外,为了解决模型推理效率问题,研究人员采用了一种「线性-二次时间步长」的策略。
如下图所示,仅需50步,就能实现接近1000步采样效果,大幅提升了推理速度。
与此同时,Movie Gen Video还采用了一种巧妙的「时间平铺」方法,进一步提升生成效率。
具体来说,这种方法将输入的视频,在时间维度上切分成多个小片段,然后对每个片对独立进行编码和解码,最后再将所有处理好的片段,重新拼接成完成视频。
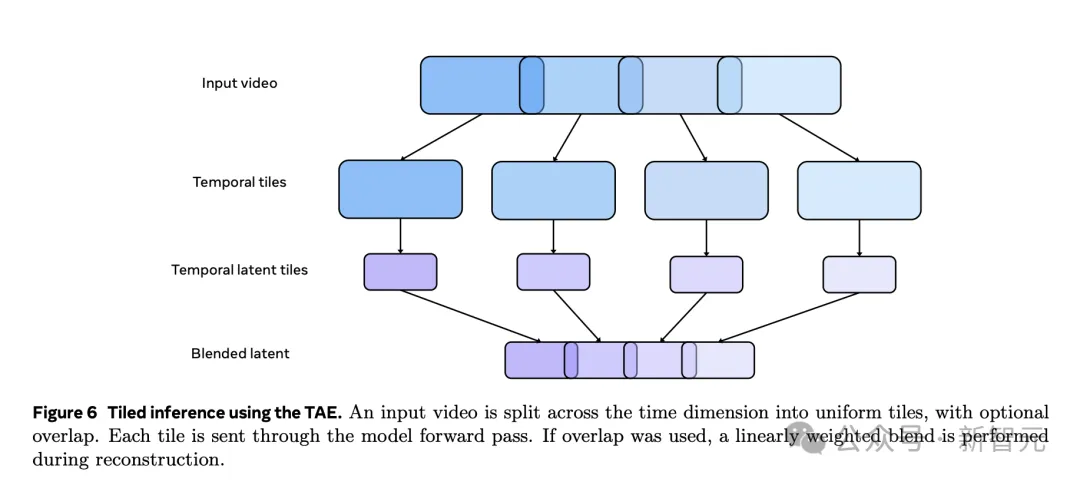
这种分而治之策略,不仅显著降低内存需求,还提高了整体推理效率。
为了确保最终生成的视频质量,团队在解码阶段采用了精心设计的重叠和混合技术。
最后微调得到的Movie Gen Video模型,与当前最先进的模型相比,大幅超越LuamaLabs的Dream Machine,还有Gen-3。
它仅小幅超越了Sora、Kling 1.5。
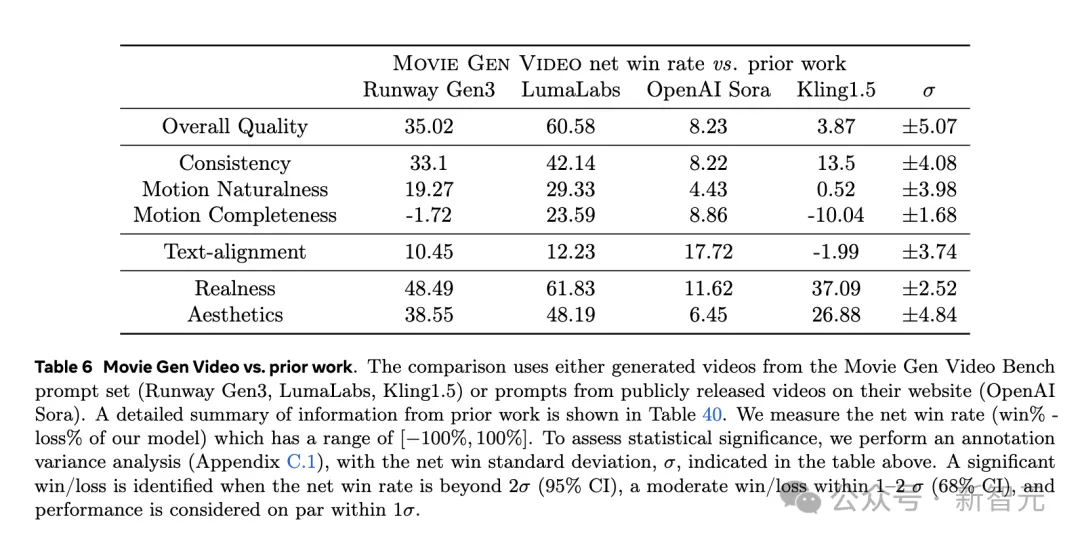
如下是,生成图像质量的对比。总的来说,Movie Gen Video在画面一致性、质量等方面,均取得了最优表现。

提示中袋鼠走路细节,在Sora中到最后并没有展现。

音频模型参数共有130亿,能够生成48kHz的高质量电影音效和音乐。
而且,这些AI音频与输入视频,实现同步。
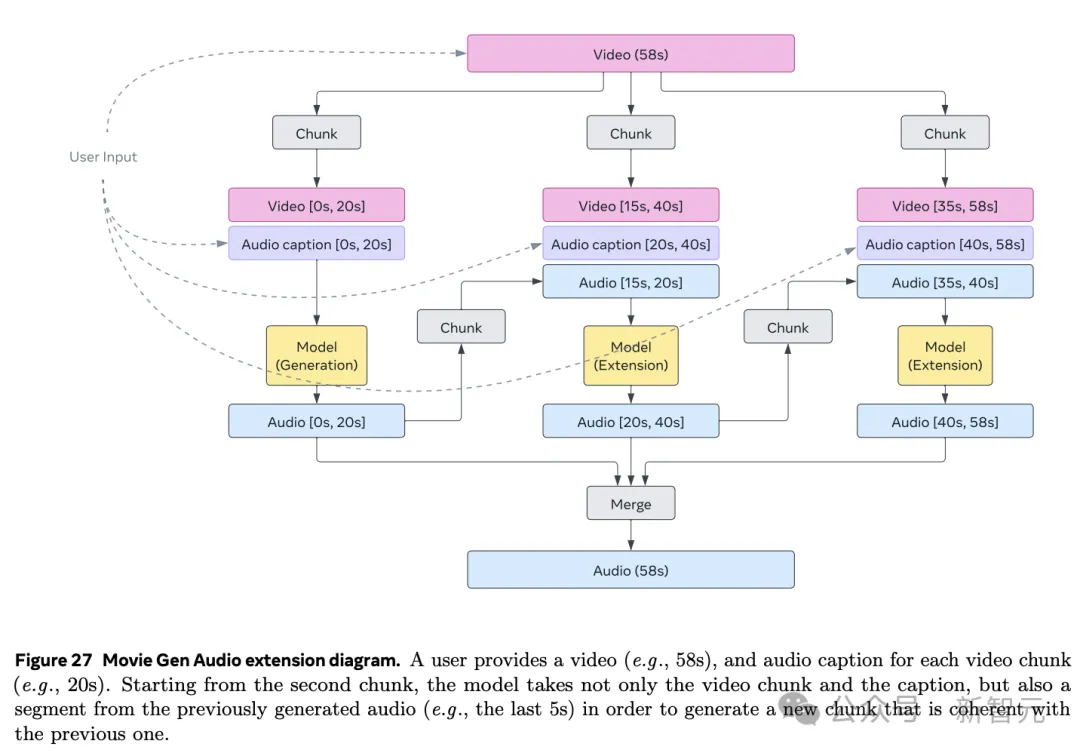
值得一提的是,Movie Gen Audio可以原生处理不同长度音频生成。
这一过程是通过TAE完成解码与编码。
而且,通过音频延伸技术,能够为长达几分钟视频,制作出连贯长音频。
研究人员在大约100万小时音频上,对模型进行了预训练。
得到的预训练模型,不仅学会了物理关联,还学会了视觉世界和音频世界之间的心理关联。
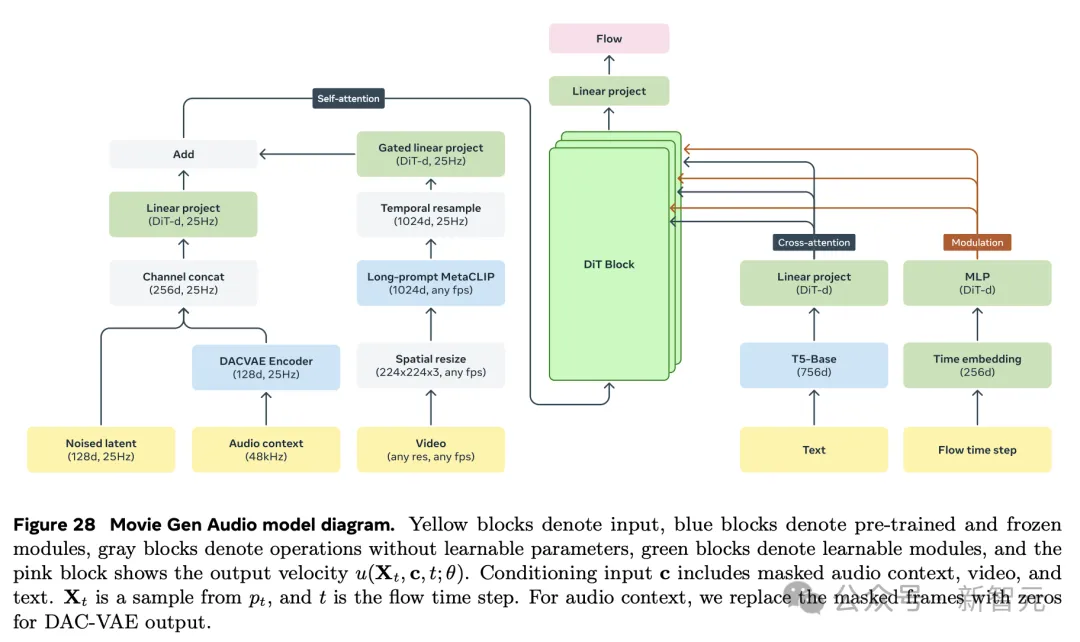
另外,模型还可以生成,与视觉场景匹配的非画面「内环境」声音,即便是声源没有出现在画面中。
最后,模型还可以生成支持情绪,并与视觉场景动作相匹配的非画面内音乐。
而且,它还能与专业地混合音效和背景音乐。
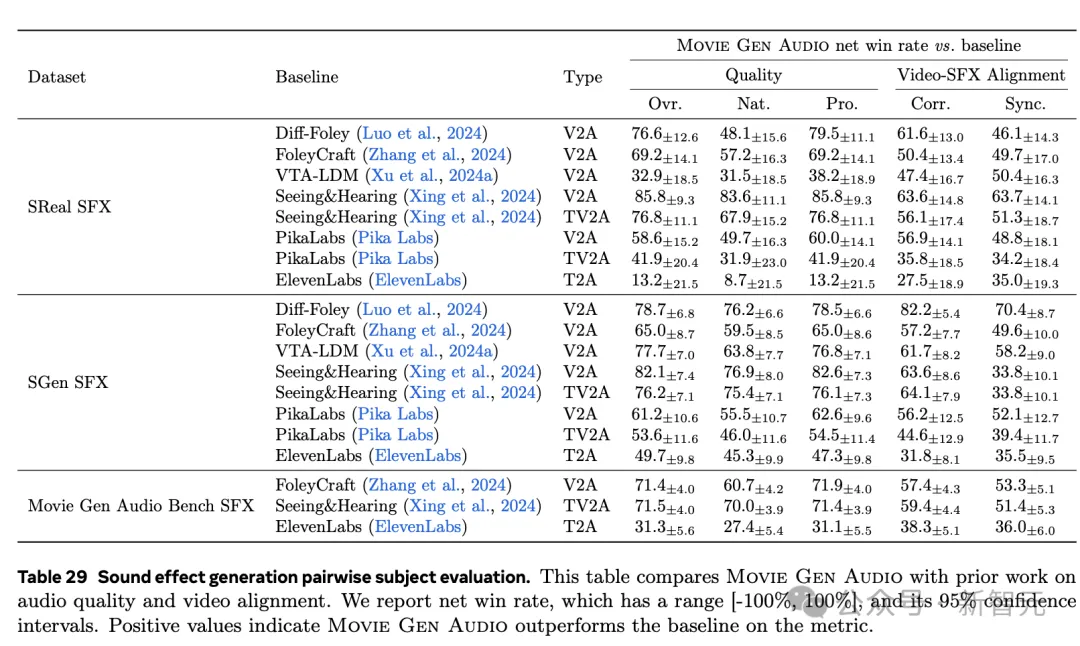
通过评估,与当前先进的音频模型ElevenLabs等相比,Movie Gen Audio结果如下所示。
参考资料:
https://x.com/AIatMeta/status/1842188252541043075
https://ai.meta.com/research/movie-gen/?utm_source=twitter&utm_medium=organic_social&utm_content=video&utm_campaign=moviegen
文章来自于微信公众号“新智元”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
