# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
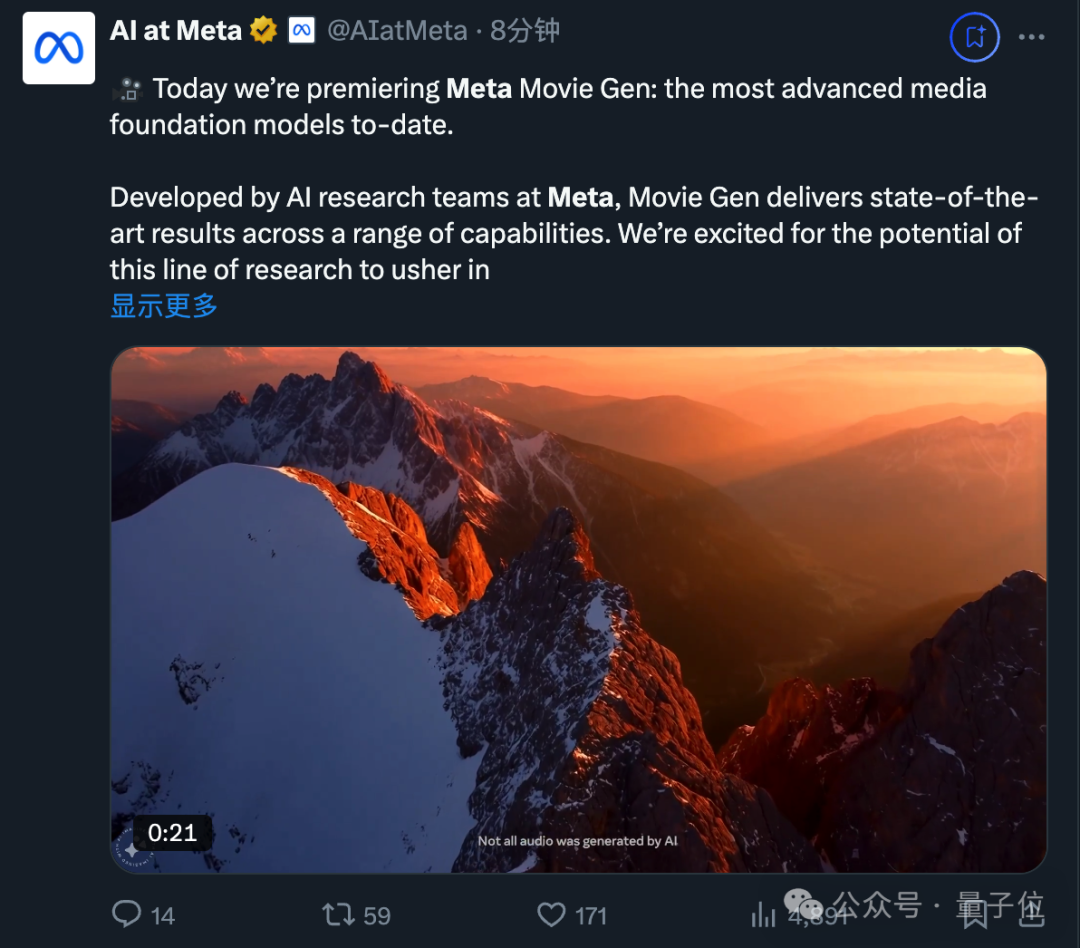
刚刚,Meta抢在OpenAI之前推出自己的Sora——Meta Movie Gen
Sora有的它都有,可创建不同宽高比的高清长视频,支持1080p、16秒、每秒16帧。
Sora没有的它还有,能生成配套的背景音乐和音效、根据文本指令编辑视频,以及根据用户上传的图像生成个性化视频。

Meta表示,这是“迄今为止最先进的媒体基础模型(Media Foundation Models)”。
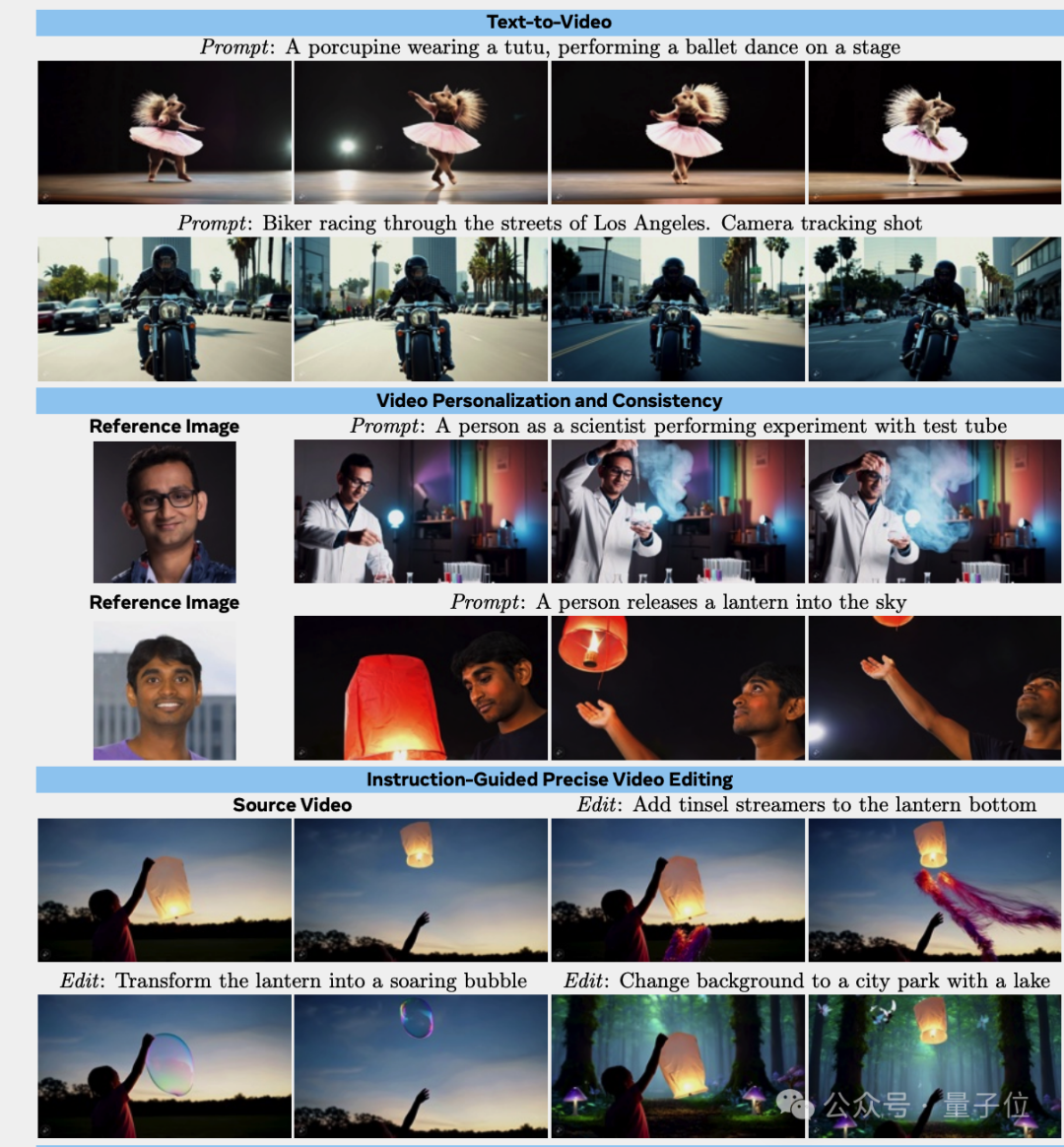
只需一句“把灯笼变成飞向空中的泡泡”,就能替换视频中的物体,同时透明的泡泡正确反射了背景环境。

上传一张自己的照片,就能成为AI电影的主角。

生成的视频不再无声,也不只是能安一个背景音乐。
比如看这里!视频会配合滑板轮子转动和落地配上逼真音效。(注意打开声音)

有人表示,随着大量创作者学会使用AI视频编辑工具,很难想象几年后长视频和短视频会变成什么样。
这一次,与Sora只有演示和官网博客不同,Meta在92页的论文中把架构、训练细节都公开了。

不过模型本身还没开源,遭到抱抱脸工程师贴脸开大,直接在评论区扔下Meta的开源主页链接:
在这等着您嗷。
Meta在论文中特别强调,数据规模、模型大小、训练算力的扩展对于训练大规模媒体生成模型至关重要。通过系统地提升这几个维度,才使得如此强大的媒体生成系统成为可能。
其中最另业界关注的一点是,这一次他们完全扔掉了扩散模型的扩散损失函数,使用Transformer做骨干网络,流匹配(Flow Matching)做训练目标。
具体来说Movie Gen由视频生成和音频生成两个模型组成。
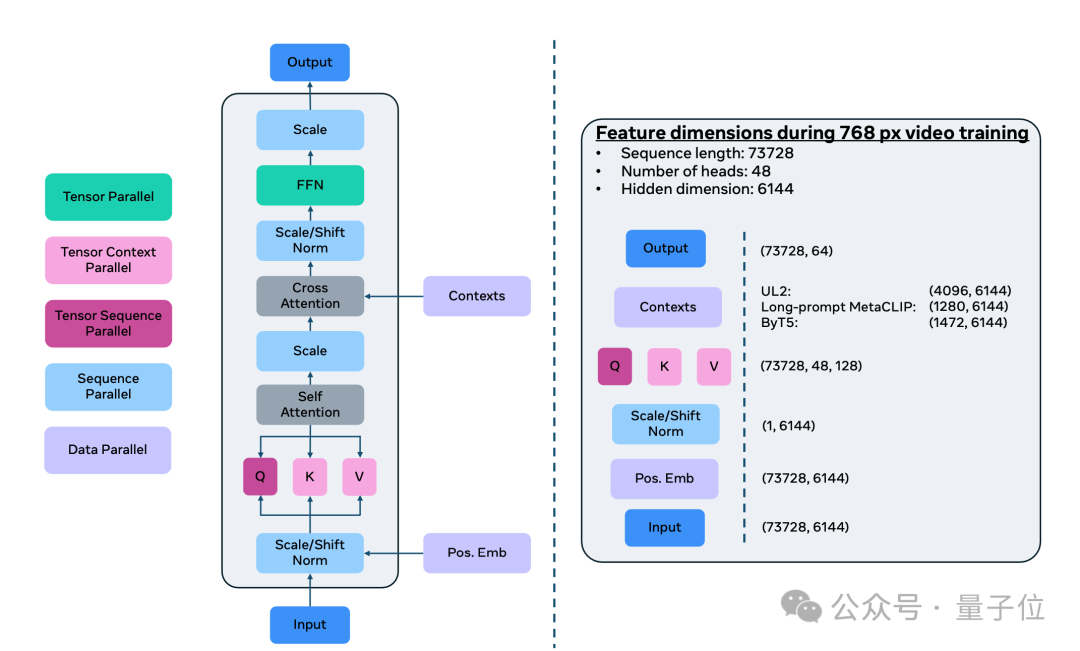
Movie Gen Video:30B参数Transformer模型,可以从单个文本提示生成16秒、16帧每秒的高清视频,相当于73K个视频tokens。
对于精确视频编辑,它可以执行添加、删除或替换元素,或背景替换、样式更改等全局修改。
对于个性化视频,它在保持角色身份一致性和运动自然性方面取得SOTA性能。
Movie Gen Audio:13B参数Transformer模型,可以接受视频输入以及可选的文本提示,生成与视频同步的高保真音频。

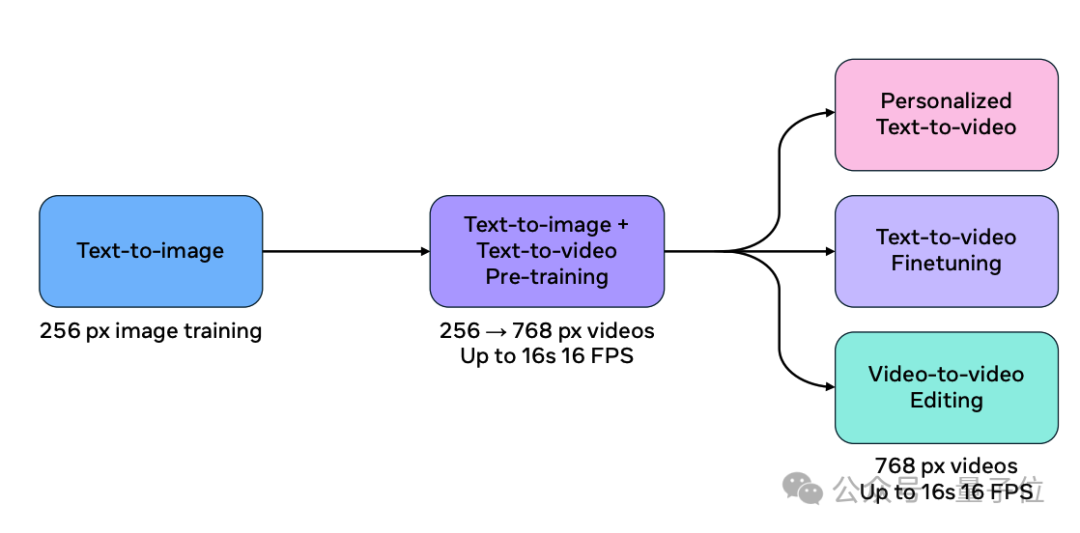
Movie Gen Video通过预训练-微调范式完成,在骨干网络架构上,它沿用了Transoformer,特别是Llama3的许多设计。
在海量的视频-文本和图像-文本数据集上进行联合训练,学习对视觉世界的理解。这个阶段的训练数据规模达到了O(100)M视频和O(1)B图像,用以学习运动、场景、物理、几何、音频等概念。
研究人员精心挑选了一小部分高质量视频进行有监督微调,以进一步提升生成视频的运动流畅度和美学品质。
为了进一步提高效果,模型还引入了流匹配(Flow Matching)作为训练目标,这使得视频生成的效果在精度和细节表现上优于扩散模型。
扩散模型通过从数据分布逐渐加入噪声,然后在推理时通过逆过程去除噪声来生成样本,用大量的迭代步数逐步逼近目标分布。
流匹配则是通过直接学习样本从噪声向目标数据分布转化的速度,模型只需通过估计如何在每个时间步中演化样本,即可生成高质量的结果。
与扩散模型相比,流匹配方法训练更加高效,计算成本更低,并且生成的结果在时间维度上具有更好的连续性和一致性。

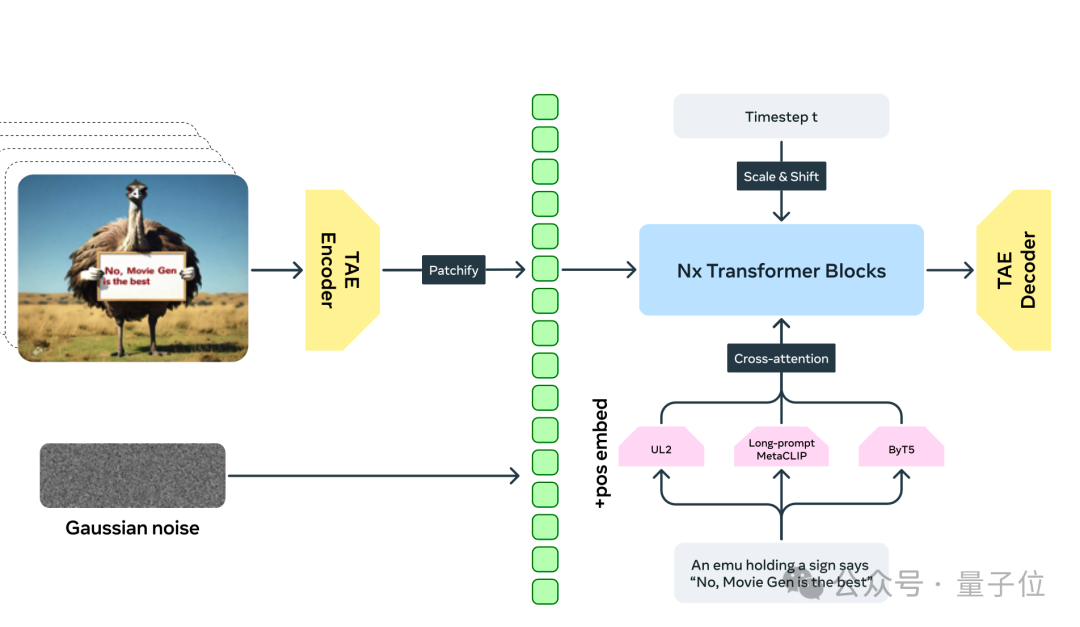
在整体架构上,首先通过时空自编码器(Temporal AutoEncoder, TAE)将像素空间的RGB图像和视频压缩到一个时空潜空间,学习一种更加紧凑的表征。
接着,输入的文本提示被一系列预训练的文本编码器编码成向量表示,作为模型的条件信息。这里用到了多种互补的文本编码器,包括理解语义的编码器如UL2、与视觉对齐的编码器如Long-prompt MetaCLIP,以及理解视觉文本的字符级编码器如ByT5。
最后,生成模型以Flow Matching的目标函数进行训练,从高斯分布采样的噪声向量作为输入,结合文本条件,生成一个输出潜码。这个潜码经过TAE解码,就得到最终的图像或视频输出。
此外Movie Gen Video在技术上还引入了多项创新:
为了让模型同时适配图像和视频,设计了一套因子化的可学习位置编码(factorized learnable positional embedding)机制。对高度、宽度、时间三个维度分别编码,再相加。这样即适配了不同宽高比,又能支持任意长度的视频。
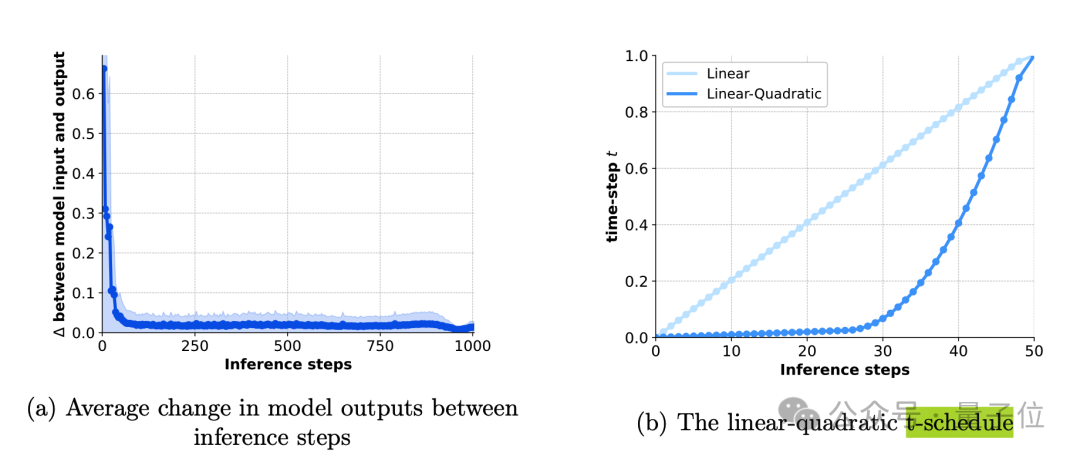
针对推理效率问题,它采用了线性-二次时间步长调度(linear-quadratic t-schedule)策略。仅用50步就能逼近1000步采样的效果,大幅提升了推理速度。
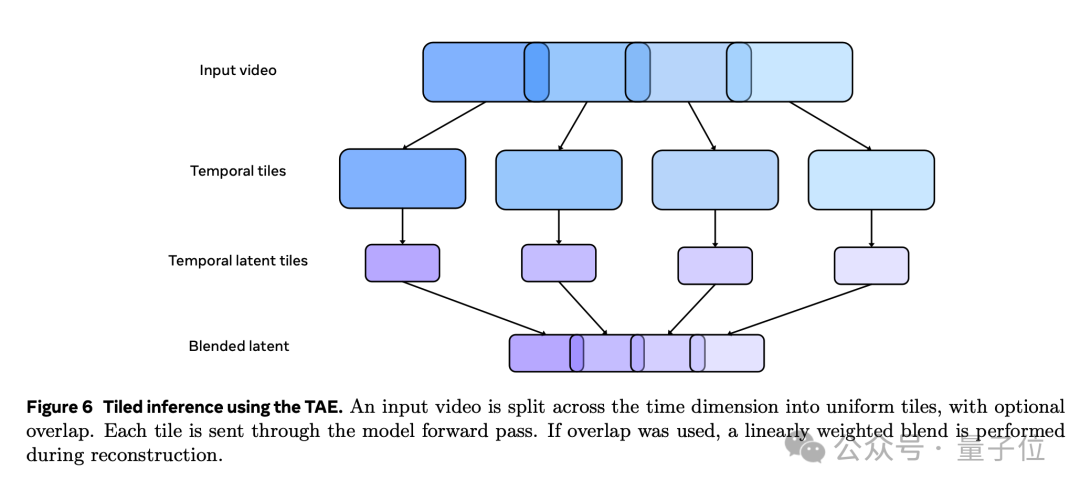
为了进一步提高生成效率,Movie Gen Video模型还采用了基于时间平铺(temporal tiling)的推理方法。应对生成高分辨率长视频时,直接对整个视频进行编码和解码可能会遇到的内存限制问题。
在时间平铺推理中,输入视频在时间维度上被分割成多个片段,每个片段独立进行编码和解码,然后在输出时将所有片段重新拼接在一起。这种方法不仅降低了对内存的需求,还提高了推理的效率。
此外,在解码阶段使用了重叠和混合的方式来消除片段边界处的伪影问题,即通过在片段之间引入重叠区域,并对重叠区域进行加权平均,确保生成的视频在时间维度上保持平滑和一致。
另外Meta还开源了多个基准测试数据集,包括Movie Gen Video Bench、Movie Gen Edit Bench和Movie Gen Audio Bench,为后续研究者提供了权威的评测工具,有利于加速整个领域的进步。
这篇长达92页的论文还介绍了更多在架构、训练方法、数据管理、评估、并行训练和推理优化、以及音频模型的更多信息。
感兴趣的可到文末链接查看。

AI视频生成这块,这两天热闹不断。
就在Meta发布Movie Gen之前不久,OpenAI Sora主创之一Tim Brooks跳槽谷歌DeepMind,继续视频生成和世界模拟器方面的工作。
这让很多人想到,就像当年谷歌迟迟不推出大模型应用,Transformer 8个作者纷纷出走。
现在OpenAI迟迟发布不了Sora,主要作者也跑了。
不过另外也有人认为,Tim Brooks选择现在离开,或许说明他在OpenAI的主要工作完成了,也让人开始猜测:
Meta的发布会迫使OpenAI放出Sora来回应吗?
(截至目前为止,Sora的另一位主创Bill Peebles还未发声。)

现在Meta放出了带有视频编辑功能的模型,再加上10月1日Pika 1.5更新,主打给视频中物体加上融化、膨胀、挤压等物理特效。
不难看出,AI视频生成下半场,要开始卷向AI视频编辑了。
文章来源于“量子位”,作者“梦晨 衡宇”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
