# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
通用机器人模型,目前最大的障碍便是「异构性」。
也就是说,必须收集全方位——每个机器人、任务和环境的特定数据,而且学习后的策略还不能泛化到这些特定设置之外。
由此,AI大神何恺明带队的MIT、Meta FAIR团队,提出了异构预训练Transformer(HPT)模型。
即预训练一个大型、可共享的神经网络主干,就能学习与任务和机器人形态无关的共享表示。
简单讲,就是在你的策略模型中间放置一个可扩展的Transformer,不用从头开始训练!

论文地址:https://arxiv.org/pdf/2409.20537
研究人员将不同本体视觉输入对齐到统一的token序列,再处理这些token以控制不同任务的机器人。
最后发现,HPT优于多个基准模型,并在模拟器基准和真实世界环境中,将未见任务微调策略性能,提升20%。
值得一提的是,这项研究被NeurIPS 2024接收为Spotlight。
在真实环境中,HPT加持下的机器人本体,能够自主向柴犬投食。

而且, 即便是洒了一地狗粮,机器人也能用抹布,将其收到一起。

而在模拟环境中,HPT架构让机器人任务操作,更加精准。
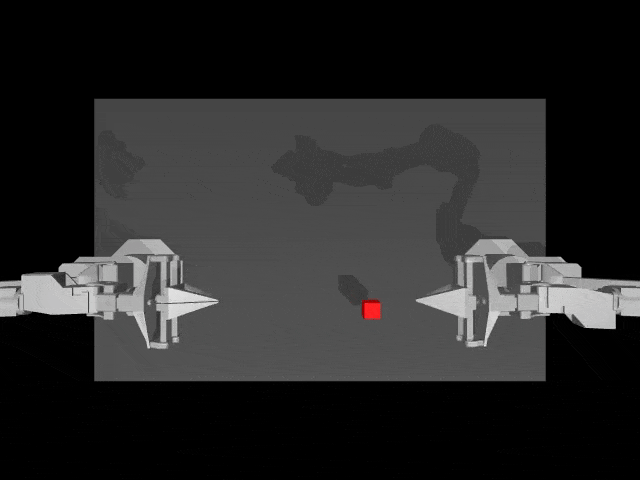
接下来,一起深度了解下异构预训练Transformer(HPT)模型的核心要素吧。
如今,构建特定的机器人策略很困难,其中最大的难题就是数据收集和缺少泛化性。
不同硬件的机器人在物理上具有不同的本体(embodiment),每种实例可以有不同的「本体感觉」(proprioception),包括不同的自由度、末端执行器、运动控制器和为特定应用构建的工作空间配置。

此外,另一种常见的异构性就是视觉异构性。
不同机器人搭载了不同的视觉传感器,而且通常配备在不同位置(比如手腕/第三视角);每个机器人的外观也会因环境和任务而有很大差异。
正是由于这些难以跨越的异构性障碍,因此通常需要收集每个机器人、任务和环境的特定数据,并且学习到的策略不能泛化到这些特定设置之外。
虽然机器人领域已经积累了海量的开源数据,但异构性让数据集很难被共同利用。
从图4中就可以看出,仅仅是按环境分类,机器人领域的数据就能被「瓜分」为远程遥控、模拟、野外、人类视频等接近4等份。
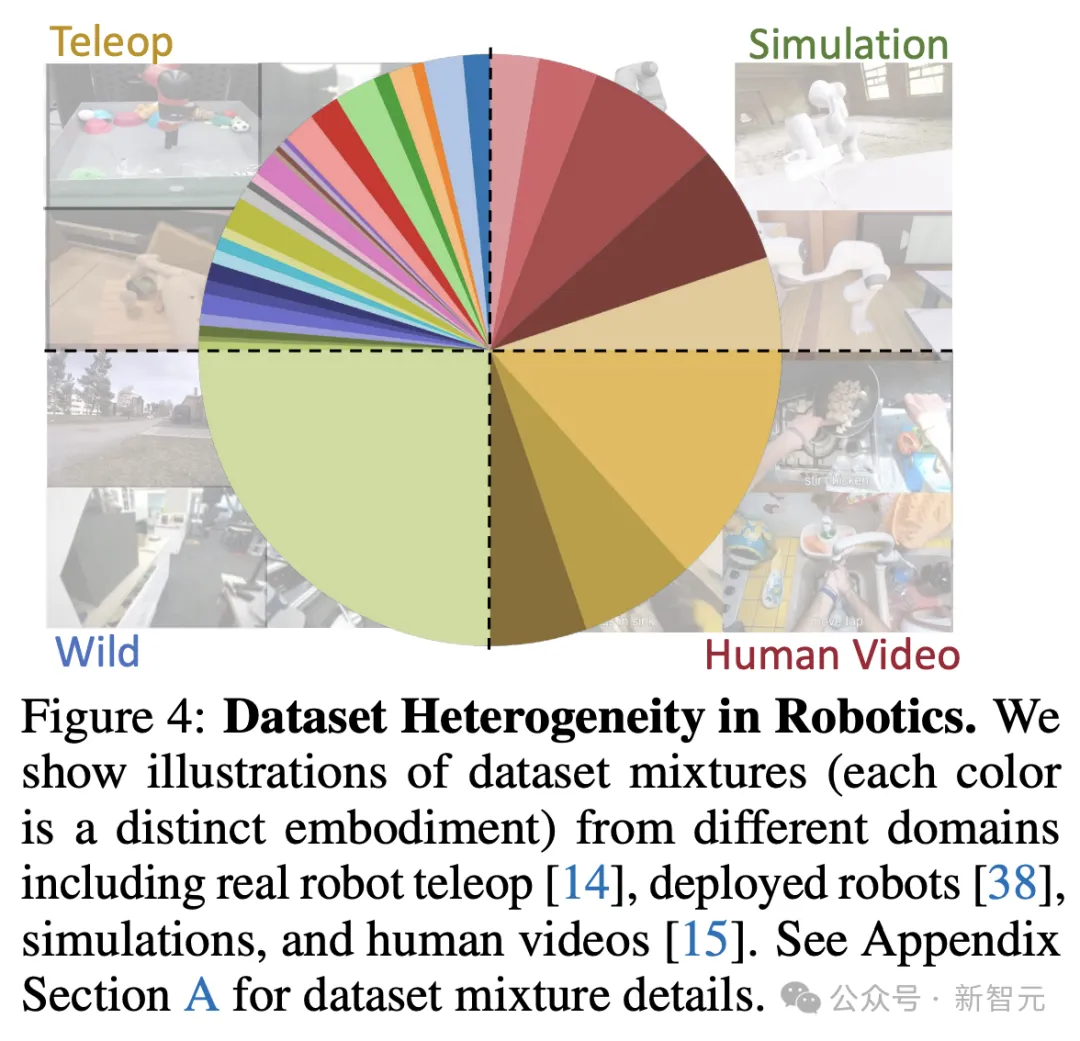
机器人领域数据集的异质性
近些年来NLP和CV领域的突飞猛进,让我们看到了彻底改变机器学习领域的一个历史教训:对大规模、高质量和多样化数据进行预训练,可以带来通常优于特定模型的通用模型。
话至此处,当今机器人领域的一个中心问题浮出水面:如何利用异构数据来预训练机器人基础模型?
除了更多数据带来的好处之外,不同任务的训练还可以增强表示(representation)的通用性。
这类基础模型将会在各种任务上实现高成功率、对异常值更加稳健,并且能够灵活地适应新任务。
那么,到底应该如何充分利用异构化的数据集?
如图1所示,一个基本的思路是,将来自不同领域和任务的输入信号映射到高维表示空间,并让它们表现出一致的缩放行为。
之后,只需要最少的微调,就可以将得到的高维表示迁移到特定的下游任务,同时获得良好的性能。

HPT概念示意图
HPT所要做的,就是找到一种共享的策略「语言」,能够对齐来自不同预训练的异质的本体感觉和视觉信息,将自己的信号映射到共享的潜在空间。
HPT全称为Heterogeneous Pre-trained Transformers,是一个架构系列,采用了模块化的设计思路,从异构本体的数据中进行可扩展学习。
受到多模态数据学习的启发,HPT使用了特定于本体的分词器(stem)来对齐各种传感器输入,映射为固定数量的token,之后送入Transformer结构的共享主干(trunk),将token映射为共享表示并进行预训练。
在对每种本体的输入进行标记化(tokenize)之后,HPT就运行在一个包含潜在token短序列的共享空间上运行。
论文提到,这种层次结构的动机,也是来源于人类身体的脊髓神经回路层面中,特定运动反应和感知刺激之间的反馈循环。
预训练完成后,使用特定于任务的动作解码器(head)来产生下游动作输出,但所用的实例和任务在预训练期间都是未知的。
预训练包含了超过50个单独的数据源,模型参数超过1B,模型的代码和权重都已公开发布。
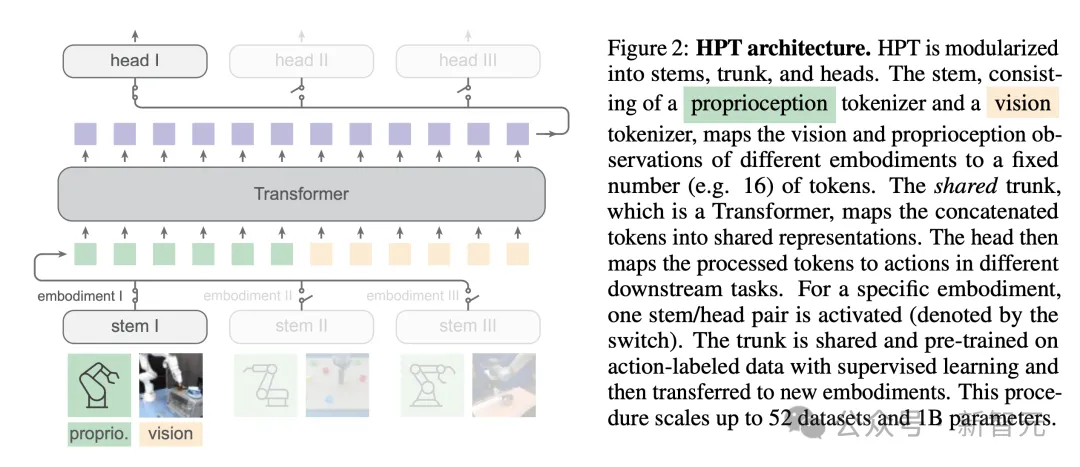
HPT架构
从上面的描述来看,要解决异构性问题,最直接和最关键的就是如何训练stem,将来自异构的本体和模态的传感器输入对齐到共享表示空间中。
如图3所示,stem包含两个主要部分,即本体感受分词器和视觉分词器,将来自不同本体的异构输入映射为固定维度、固定数量的token,让trunk能够以相同的方式处理。
其中的关键思想,是利用cross-attention机制,让固定数量的可学习token关注到各种特征。
虽然这篇论文主要处理本体感觉和视觉,但处理触觉、3D和动作输入等其他类型的异构传感器信号也可以在stem中灵活扩展。
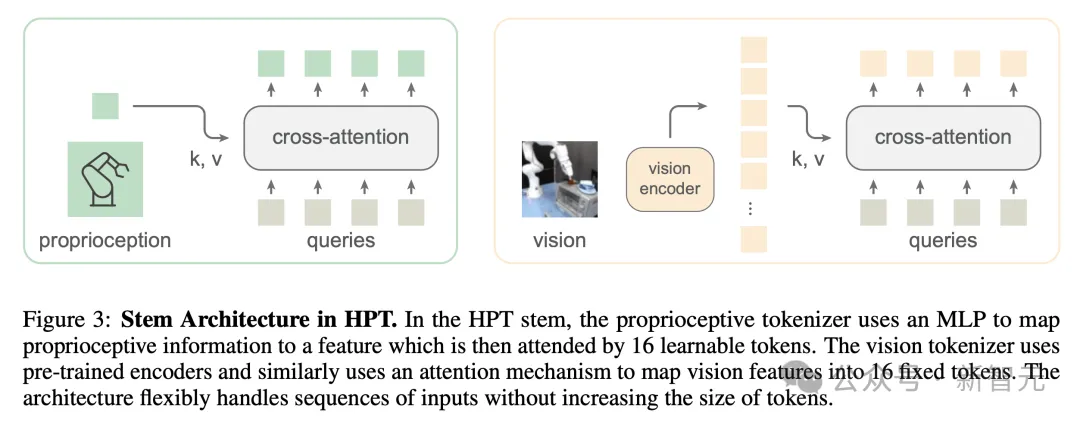
HPT中的stem架构
按照时间顺序单独处理每个模态后,将所有token拼接在一起并添加额外的模态嵌入和正弦位置嵌入,就得到了trunk的输入序列。
为了避免过拟合,stem被设计为仅有少量参数,只包含一个MLP和一个注意力层。
作为预训练的核心组件,trunk是一个有潜在d维空间的Transormer结构,参数量固定,在不同的本体和任务之间共享,以捕获复杂的输入-输出关系。
给定从不同分布中采样的异构本体的数据集????_1,…,????_k,…,????_K ,令????_k={τ^(i)}_{1≤i≤M_k} 表示????_k中一组轨迹M_k,τ^(i)={o_t^(i), a_t^(i)}_{1≤t≤T}表示第i个最大长度为T的轨迹,每个元组包含observation变量和action变量。
训练目标如公式(1)所示,需要最小化数据集中的以下损失:
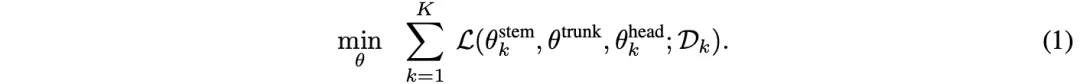
其中ℒ是行为克隆损失,计算为预测结果和真实标签之间的Huber 损失。
该训练过程有两个数据缩放轴:单个数据集D_k的体量M_k,以及数据集总数K。
在预训练阶段,每次迭代时仅更新trunk部分参数,并且基于训练批次采样更新特定于每个异构本体和任务的stem和head部分。
论文进行了一系列预训练实验,包括不同规模的网络参数和数据集大小,旨在回答一个问题:HPT预训练在跨域异构数据中是否展现出了扩展能力?
总体而言,某种程度上,HPT随着数据集数量、数据多样性、模型体量和训练计算量呈现出缩放行为。
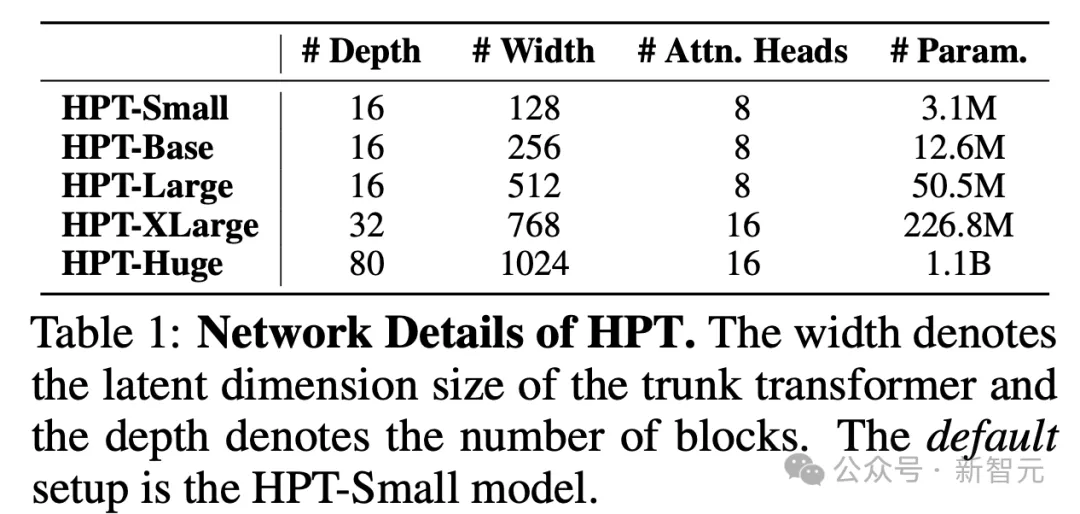
HPT网络详细信息,宽度表述turnk transformer的潜在维度,深度表示block数量,默认设置为HPT-Small型号

预训练数据集详细信息,默认使用来自RT-X的27个数据集的16k个轨迹进行训练
数据方面,如图5所示,即使在异构程度逐渐增大的本体中也具有稳定且可扩展的验证损失。
此外,作者还发现,计算量(相当于每次训练运行看到的样本量)和数据量需要共同扩展,才能在训练过程中更接近收敛。
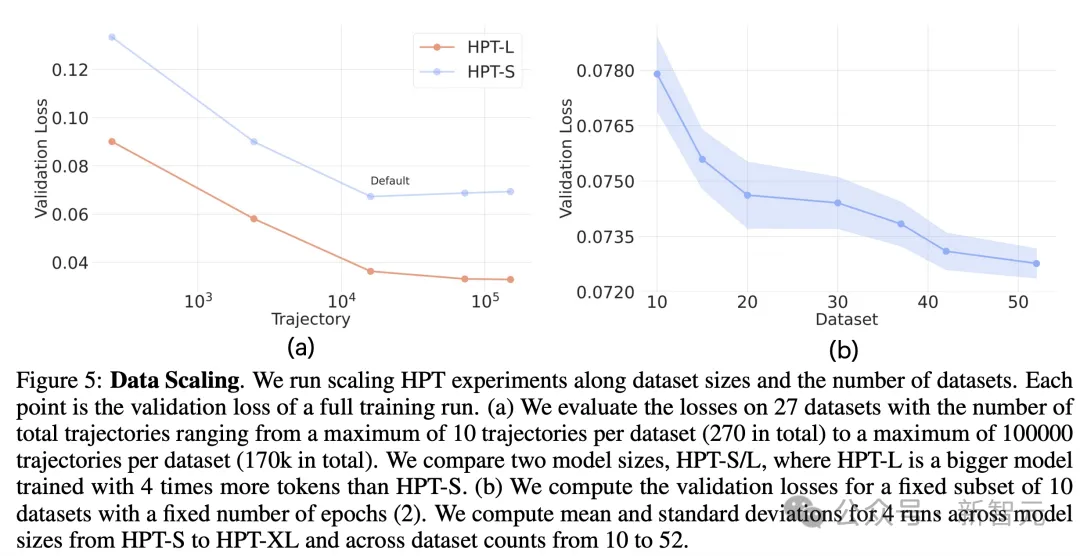
如图6所示,增加批大小(左)相当于有效地扩展训练token数(右),通常可以提高模型性能,直至最后收敛。
另一个观察结果是,使用分布式方法,在每个训练批中聚合尽可能更多的数据集,用更大的批大小来弥补异构训练中的较大方差。
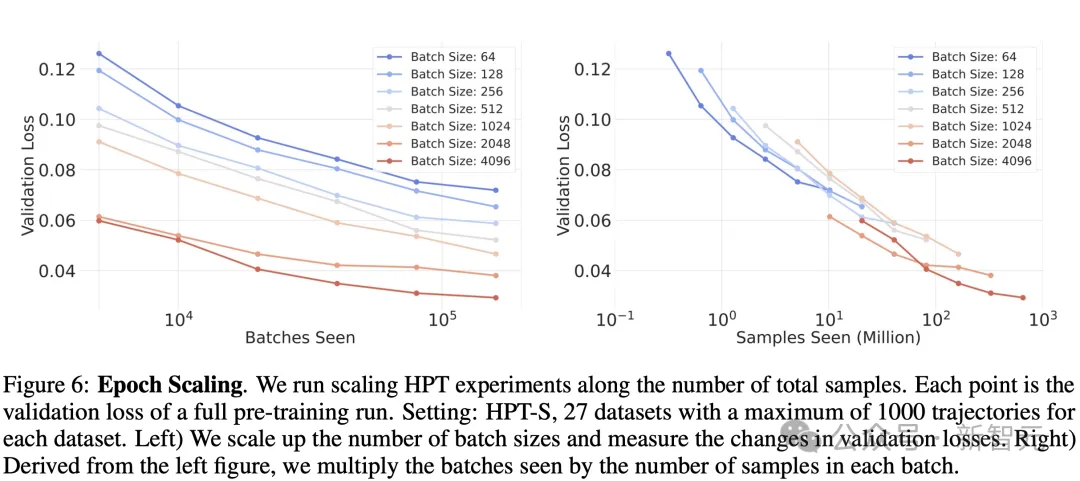
如图7所示,固定数据集和轨迹数量,沿着模型大小(从1M到1B)进行缩放,并逐渐将批大小从256增加到 2048(模型大小每增加一倍),并使用具有170k轨迹的更大数据集。
可以观察到,当我们扩展到具有更大计算量(红线)的更大模型时,预训练可以实现较低的验证损失,直到达到稳定水平,但没有发现缩放模型深度和模型宽度之间存在显著差异。
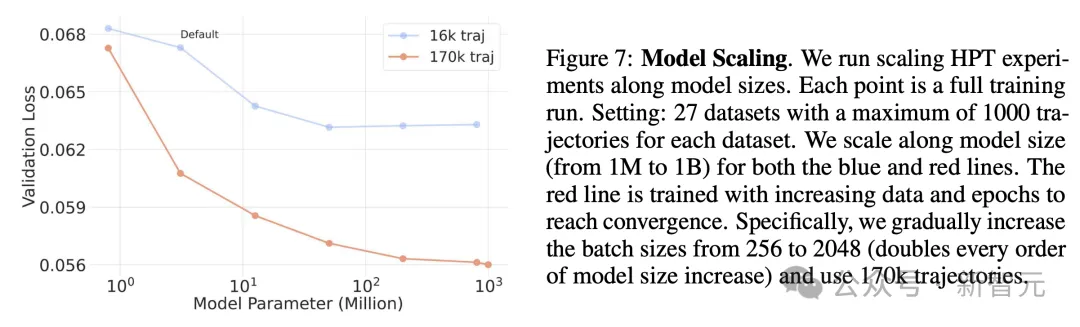
图8中的实验结果表明,HPT可以相当有效地处理异构数据。尽管与真实机器人存在很大的差距,但对其他本体的数据集(例如模拟环境和人类视频数据集)进行预训练是可能的。

如上,作者使用了最后一次迭代中验证集上的损失来评估预训练。
接下来,他们将通过实验,去验证机器人在迁移学习中,任务成功率的问题:
预训练的HPT模型,是否可以迁移到模拟和现实世界中的全新本体、任务、以及环境中?
如下图10(a)中,研究人员在闭环模拟中测试了下游任务的模型,并观察到使用HPT-B到HPTXL预训练模型,提到的任务成功率。
在图10(b)中,他们在最近发布的Simpler基准上运行HPT,它允许在高保真模拟上与Octo、RT1-X、RT2-X进行比较。
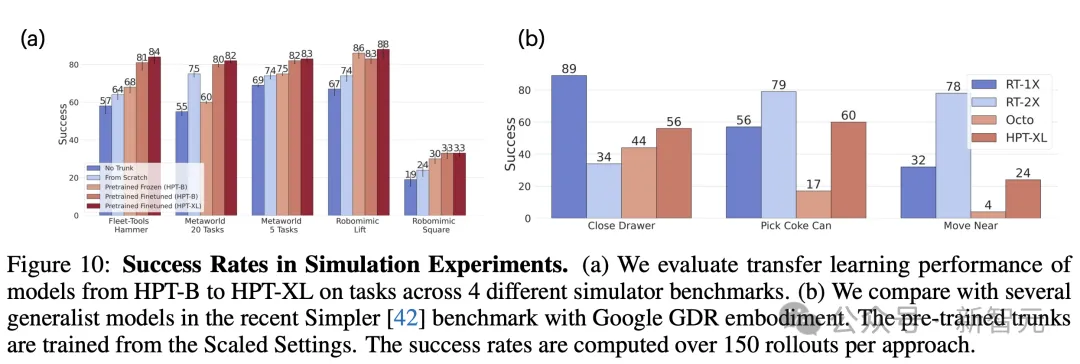
在Google EDR机器人中,研究人员重点关注三个不同的任务「关闭抽屉」、「选可乐罐」。
对于每个任务,他们测试了几种不同的初始化,所有任务总共有300+ episode。


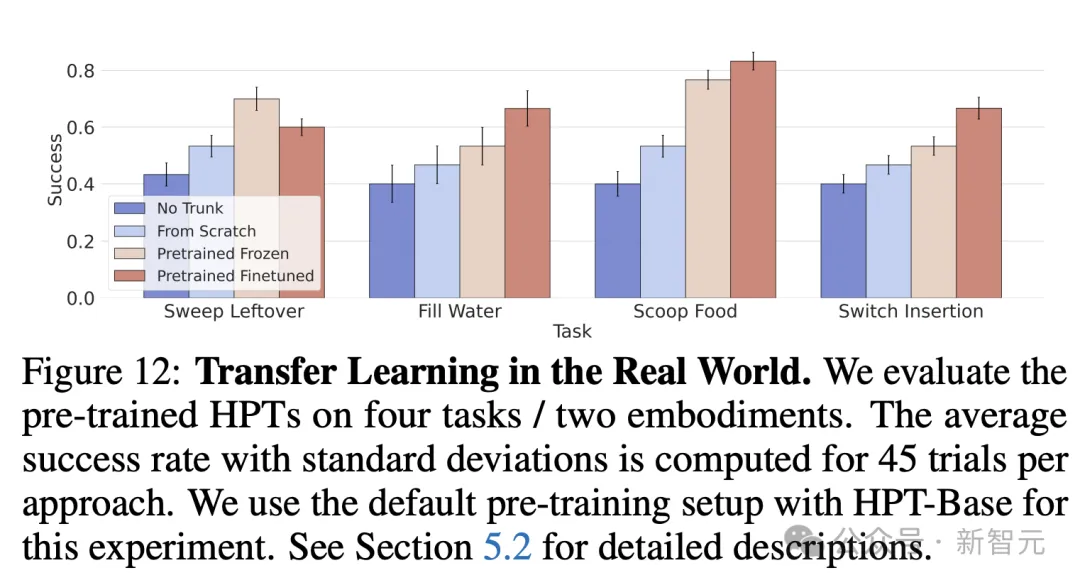
图11定性结果显示,作者观察到预训练的HPT在面对不同姿势、物体数量、相机配置、光照条件时,表现出更好的泛化能力和鲁棒性。

在表3中,作者对Sweep Leftover任务进行了消融研究。

尽管最近数据规模激增,但由于异构性的存在,机器人学习的通用性仍然受到限制。
研究人员提出的HPT——一种模块化架构和框架,通过预训练来应对这种异构性。
他希望这一观点能够启发未来的工作,以处理机器人数据的异构性本质,从而为机器人基础模型铺平道路。

Lirui Wang是MIT CSAIL的博士生,导师是Russ Tedrake教授。
在此之前,他曾在华盛顿大学获得学士和硕士学位,导师是Dieter Fox教授。
他的研究兴趣在于机器学习和机器人学。尤其是,他对开发能够在复杂和非结构化的真实世界环境中,泛化的算法和系统感兴趣。
为了实现这一点,他一直致力于研究能够随着异类数据进行扩展的「舰队学习」(fleet learning)。

Xinlei Chen是旧金山Meta Fair实验室的研究科学家。目前的研究兴趣是预训练,特别是自监督、多模态视觉表征的预训练。
他曾在CMU语言技术研究所获得博士学位,就读期间也在机器人研究所工作。此前,他获得了浙大的学士学位。

Jialiang Zhao目前是 MIT CSAIL感知科学小组的博士生,导师是Edward H. Adelson教授,并与Russ Tedrake 、何恺明合作。

何恺明目前是麻省理工学院电子工程与计算机科学系副教授。
他提出的最为著名的研究是深度残差网络(ResNets),并被广泛应用到现代深度学习模型当中,比如Transformer(GPT、ChatGPT)、AlphaGo Zero、AlphaFold、扩散模型等。
在加入MIT之前,何恺明于2016年至2024年担任Facebook AI Research的研究科学家,并于2011年-2016年担任微软亚洲研究院(MSRA)的研究员。
他曾在2011年在香港中文大学获得博士学位,并于2007年在清华大学获得学士学位。
参考资料:
https://liruiw.github.io/hpt/
https://x.com/LiruiWang1/status/1841098699436351742
文章来自于微信公众号“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
