# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本篇综述工作已被《IEEE 模式分析与机器智能汇刊》(IEEE TPAMI)接收,论文第一作者顾尚定博士来自慕尼黑工业大学、加州大学伯克利分校,论文通讯作者陈广教授来自同济大学计算机科学与技术学院。共同作者包括北京大学杨龙博士、伦敦国王大学杜雅丽教授、伦敦大学学院汪军教授、慕尼黑工业大学 Florian Walter 和 Alois Knoll 教授。
随着人工智能(AI)的飞速发展,强化学习(Reinforcement Learning,RL)在诸多复杂决策任务中取得了显著的成功。我们在自动驾驶、机器人控制和推荐系统等实际应用中,越来越依赖于这些智能系统。然而,现实世界中的强化学习在应用过程中也面临着巨大的挑战,尤其是如何保证系统的安全性。为了解决这一问题,安全强化学习(Safe Reinforcement Learning, Safe RL)应运而生,成为当前学术界和工业界关注的焦点。
这篇文章将为大家解析由慕尼黑工业大学、同济大学、加州大学伯克利分校、伦敦大学学院、伦敦国王大学和北京大学的研究人员联合发布的综述《安全强化学习:方法、理论与应用》的重要观点,深入探讨安全强化学习的研究现状、关键问题及未来发展方向。

强化学习的核心目标是通过与环境的交互,不断调整和优化策略以获得最大化的奖励。然而,现实环境中的风险与不确定性往往导致严重的安全问题。例如,在自动驾驶中,车辆不能因为探索策略而危及乘客的安全;在推荐系统中,推荐的内容不能带有种族或其他歧视性信息。
安全强化学习正是在这种背景下提出的,它在传统强化学习的基础上加入了安全约束,旨在优化奖励的同时,保证决策过程中的安全性。具体来说,安全强化学习需要解决以下几个关键问题,即 “2H3W” 问题:
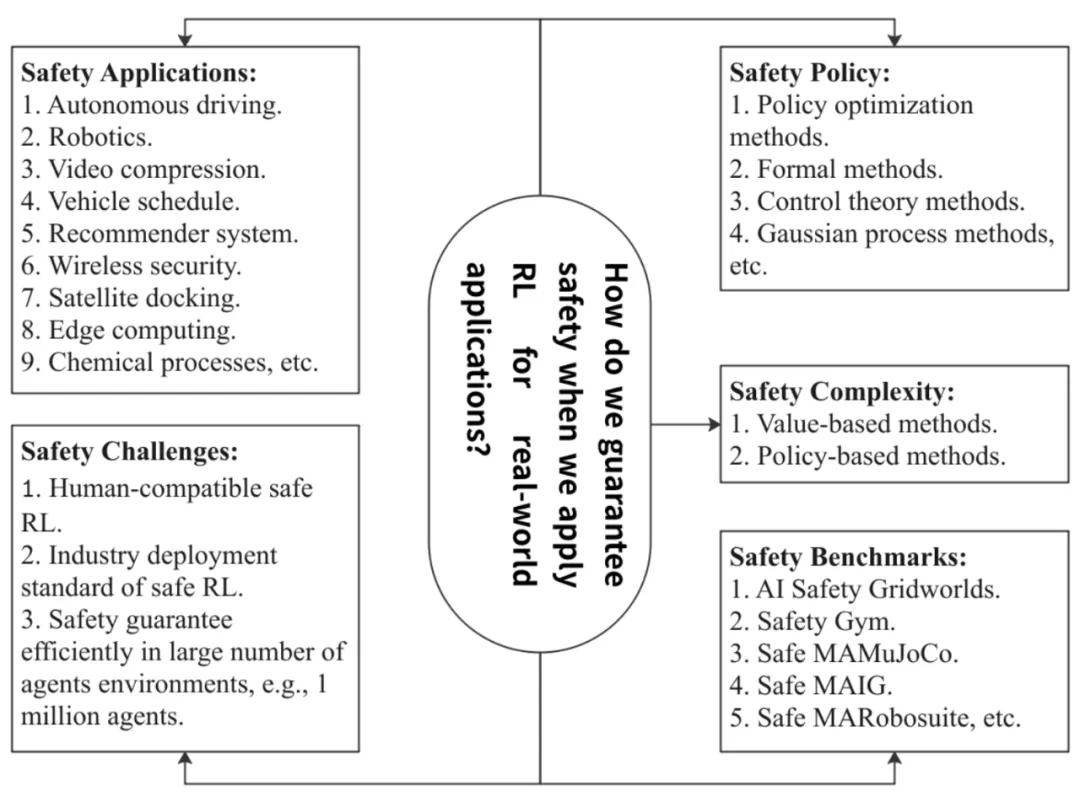
研究者们提出了多种方法来处理安全强化学习的问题,可以大致分类为基于模型的方法和无模型的方法。
基于模型的安全强化学习方法通常依赖于对环境的建模,通过利用物理模型或近似模型进行推理和决策。这类方法通常具有较高的学习效率。例如,基于控制理论的方法通过使用李雅普诺夫函数或模型预测控制(MPC 等工具,可以为机器人和无人驾驶汽车等复杂系统提供严格的安全保证。
无模型的方法则不依赖于精确的环境模型,而是直接通过与环境的交互来进行学习。策略优化和价值优化是其中的两大主流方法。在这些方法中,研究者们通过引入约束条件来确保学习过程中的安全性,如使用拉格朗日乘子法进行安全约束优化,或通过概率估计来避免系统进入危险状态。
安全强化学习的理论分析主要集中在如何评估和证明算法的安全性。包括采样复杂性分析、收敛性证明和策略安全的概率分析等。理论研究不仅帮助我们理解算法的性能边界,还指导我们在实际应用中如何有效地实施这些算法。
安全强化学习与传统的强化学习在理论层面有明显的不同,特别是在约束马尔科夫决策过程(CMDP)的框架下,许多理论分析是基于优化算法和约束策略展开的。以下是一些关键的理论分析点:
传统强化学习的目标是找到能够最大化累积奖励的策略,而安全强化学习则需要在此基础上加入安全约束,确保系统在运行过程中不会进入不安全状态。理论上,安全强化学习通过引入约束条件,如成本函数或概率约束,来避免 “危险” 状态。这使得安全强化学习问题在复杂度上远超传统强化学习问题,尤其是在需要解决安全性与奖励之间的权衡时,安全强化学习的复杂度进一步增加。
为了优化带有安全约束的强化学习问题,拉格朗日乘子法是一个常见的工具。通过引入拉格朗日乘子,安全强化学习问题可以转化为求解一个带有约束的优化问题。其基本思想是在优化目标函数的同时,通过乘子调整约束条件的权重,从而在保证策略安全的前提下,找到最优解。
通过这种方法,安全强化学习可以在训练过程中逐步逼近最优策略,同时确保系统满足安全约束。
在安全强化学习中,另一个关键的理论问题是样本复杂度。样本复杂度衡量的是在给定约束条件下,算法需要多少交互样本才能找到一个足够好的策略。现有研究表明,一般而言,对于安全强化学习,样本复杂度比传统强化学习更高,因为除了优化奖励外,还需要考虑安全约束的满足程度。
此外,理论分析还包括安全违规(safety violations)的可能性分析。在许多现实应用中,我们无法保证系统在训练过程中永远不会违反安全约束。因此,研究人员开发了各种算法来最小化安全违规的概率,并确保算法在大多数情况下能够遵守安全边界。
在安全强化学习的理论分析中,收敛性是另一个核心问题。确保算法能够在有限的时间内收敛到最优解,同时满足安全约束,是一个具有挑战性的问题。研究人员通常使用梯度下降法或策略梯度法来解决这些问题,并证明了这些方法在某些条件下的收敛性。例如,通过在策略空间中添加限制性搜索区域,可以显著减少探索时的安全违规,并加速算法的收敛。
为了评估安全强化学习算法的效果,研究者们开发了多个基准测试环境。这些基准测试不仅能够帮助我们更好地衡量算法的性能,还能推动安全强化学习算法向实际应用的落地。以下是几个广泛使用的安全强化学习基准测试环境:
1.AI Safety Gridworlds:
这是由 DeepMind 推出的一个 2D 网格环境,专门用于评估安全强化学习算法。每个环境都是网格组成,智能体需要通过采取行动来达到目标,同时避免进入危险区域。该环境的动作空间是离散的,适用于简单的安全决策任务。
2.Safety Gym:
OpenAI 推出的 Safety Gym 基于 Gym 和 MuJoCo 环境,支持机器人导航并避免与障碍物碰撞的任务。此环境中的智能体(如球状机器人、车机器人等)通过执行连续动作来完成任务,能够很好地模拟实际机器人和自动驾驶中的安全挑战。
3.Safe Control Gym:
这是一个集成了传统控制方法和强化学习方法的基准测试环境。Safe Control Gym 专注于安全控制问题,提供了多种任务,如单轴和双轴四旋翼控制、轨迹跟踪等。该环境尤其适用于从仿真到实际应用的安全控制研究。
1.Safe Multi-Agent MuJoCo:
这是一个基于 MuJoCo 的多智能体安全强化学习基准。每个智能体控制机器人的一部分,并且必须共同学习如何操作机器人,同时避免碰撞到危险区域。这个基准环境非常适合评估多智能体系统中的协作和安全问题。
2.Safe Multi-Agent Robosuite:
这是一个基于 Robosuite 的多智能体机器人臂控制环境。多个智能体控制机器人臂的不同关节或者不同智能体控制不同的机械臂,共同完成任务,同时避免碰撞到障碍物。该环境模拟了机器人在实际应用中面对的模块化控制和安全问题。
3.Safe Multi-Agent Isaac Gym:
这是一个基于 Isaac Gym 的高性能多智能体基准测试环境,支持在 GPU 上进行轨迹采样,其计算速度一般而言比 MuJoCo 和 Robosuite 要快至少十倍。该环境主要用于大规模多智能体任务中的安全学习。

安全强化学习在许多关键领域都有着广泛的应用前景:
尽管安全强化学习已取得一定进展,但仍面临许多挑战,包括算法的可扩展性、多任务学习的安全性问题、以及实时性能的保证等。未来的研究需要在这些方面进行更深入的探索,并开发出更智能、更安全的 RL 解决方案。
1. 博弈论与安全强化学习结合:博弈论是解决安全问题的主要方法之一,因为不同类型的博弈可应用于各种实际场景,包括合作和竞争情境。优化在扩展形式博弈中的安全性对实际应用十分有益。例如,在击剑比赛中,关键在于确定确保双方智能体在完成目标的同时保持安全的方法。
2. 信息论与安全强化学习结合:信息论在处理不确定的奖励信号和成本估计方面起着重要作用,特别是在大规模多智能体环境中。通过信息编码理论,可以构建各种智能体行为或奖励信号的表示,从而提升整体效率。
3. 其他潜在方向:包括从人脑理论和生物学洞察中获得灵感,创新安全体强化学习,以及从人类反馈中学习安全且多样化的行为(类似于 ChatGPT)。
安全强化学习作为人工智能领域中的一个重要分支,正在逐步走向成熟。通过解决其面临的挑战,我们有望看到更加安全、智能的 AI 系统在自动驾驶、机器人和推荐系统等领域得到广泛应用。
文章来自于微信公众号“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
