# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM能耗的疯狂增长,甚至已经引起了联合国的注意,成为了不容小觑的能源消耗者。
据统计,2023年初ChatGPT服务的平均用电量为每天564兆瓦时,相当于18000个美国家庭每天的总用电量。
谷歌的情况更加严峻。最坏的情况下,谷歌AI服务消耗的电力可能和一整个爱尔兰相当,约为每年29.3 TWh。

要在提升推理速度的同时降低大模型的能耗,减少神经网络所需的计算量才是关键。
而LLM等大规模神经网络,大部分计算量正是消耗在浮点级精度的矩阵乘法上。
从线性注意力机制到量化,大多数Transformer的优化都离不开对于乘法效率的大幅提高。要么减少运算操作次数,要么减少操作数的位数。
但如果从乘法运算这个更加底层的逻辑出发,两位华人研究者提出,可以用一个整数加法器以高精度近似进行浮点数乘法运算,即L-Mul乘法算法。

论文地址:https://arxiv.org/abs/2410.00907
相比量化过程中的FP8乘法,L-Mul能达到更高的精度,而且运算量显著减少。
实验结果显示,在张量处理硬件中应用L-Mul操作能将逐元素浮点张量乘法的能量成本降低95%,点积的能量成本降低80%。
此外,L-Mul可以直接集成到各个级别的现有模型中,无需额外训练,甚至能无损替换注意力机制中所有的矩阵、元素级别的浮点数乘法。

整体而言,L-Mul方法专注于提高对张量进行算术运算的效率——这与当前在I/O和控制优化方面的研究是相互独立但又相辅相成的。
由此作者认为,真正高能效、高计算效率的人工智能计算将从I/O、控制流,和算术运算的全面优化整合中产生。
大多数机器学习模型,包括神经网络,都使用浮点张量来表示它们的输入、输出和可训练参数。
其中,典型的选择是32位和16位浮点张量,即fp32和fp16。

在现代计算硬件中,浮点数之间的乘法比加法运算消耗更多的能量,浮点数运算也显然比整数更加昂贵。
用n代表数字位数,那么整数加法的计算复杂度仅有O(n);而对于指数部分有e位、尾数部分有m位的浮点数,乘法运算则需要O(e)复杂度的加法加上O(m^2)复杂度的乘法。
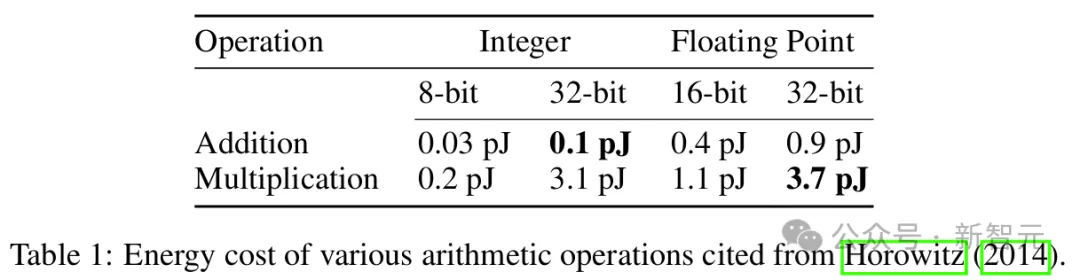
如表1所示,元素级别的运算上,fp32乘法和int32加法已经差距悬殊,能量高出37倍;如果是张量级别的运算,那更是相差甚远。
比如下面两种常用的运算:逐元素乘法Y_1和点积Y_2。

计算Y_1时,如果A和X都是fp32张量,相比int32矩阵的加法所消耗的能量也会高出37倍。
同样,计算Y_2时涉及m×n×k次的浮点乘法和加法,两个数字的每次乘加运算都会消耗0.9+3.7=4.6(pJ)能量。
如果替换为int32,那么每次运算的能量成本就变为0.1+0.9=1.0 pJ,仅为原始成本的21.7%。
类似地,如果原始精度为fp16,替换为int16后也能达到1−(0.05+0.4)/(1.1+0.4)=70%的效率提升。
那么,对于n位的浮点数,到底要如何用整数加法近似计算浮点数乘法,实现O(n)复杂度?
考虑两个浮点数x和y,它们的指数和小数部分的位数分别为x_e、y_e和x_m、y_m。
传统的浮点乘法可以表示为:
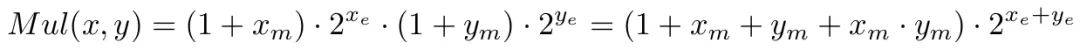
再加上一个异或操作(⊕)来决定结果的符号为正或为负。
其中,尾数部分的乘法操作是提升效率的瓶颈,复杂度为O(m^2)。
L-Mul所做的,就是移除这个操作,引入了一种新的乘法算法,以O(m)的计算复杂度处理尾数:
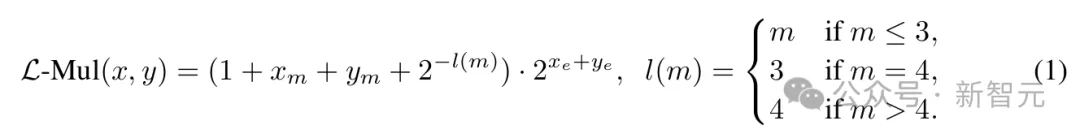
对比上面的公式可以发现,我们仅仅是将x_m · y_m替换为2^{-l(m)},其中l(m)是一个简单的分段函数。
虽然等式(1)包含4个加法操作,但浮点数的位格式设计能帮助我们用一个加法器实现L-Mul算法。
浮点格式隐式处理1+x_m,所以不必计算(1+...)的值;整数加法操作还会自动将尾数进位发送到指数,这与传统浮点乘法器中的舍入过程不同。
在传统方法中,小数部分需要手动舍入为1.x,并且向指数部分添加进位需要作为独立步骤进行;而根据L-Mul中的分段函数l(m),如果尾数和大于2,进位会自动添加到指数。
因此,通过跳过尾数乘法和舍入操作,L-Mul算法比传统浮点乘法更高效。
算法的具体实现过程如图2所示,最佳实现是在硬件级别,因此作者添加了在英伟达GPU上模拟该过程的内联PTX汇编代码。
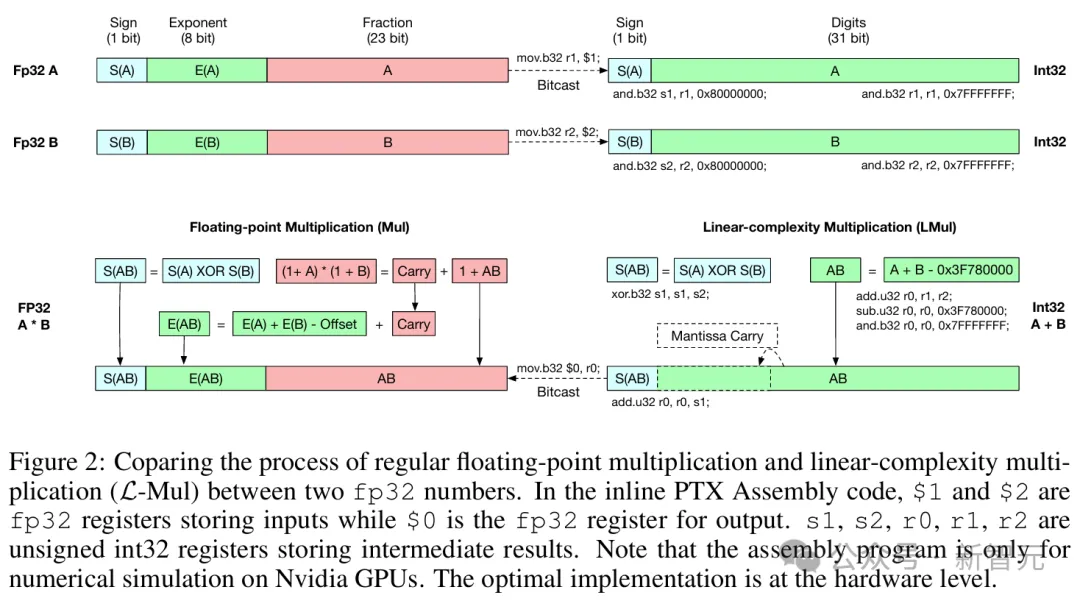
常规浮点乘法和L-Mul算法的复杂度比较;在汇编代码中,$1和$2是存储输入的fp32寄存器,$0是用于输出的fp32寄存器。s1、s2、r0、r1、r2是存储中间结果的无符号int32寄存器
L-Mul结果的构造可以用以下等式表示,其中所有位级计算都作为无符号整数之间的操作执行:
在此基础上,作者进一步用L-Mul实现了注意力机制。
在Transformer模型中,注意力机制由于其处理输入上下文C的O(|C|^2)复杂度而具有高计算成本。
但如果使用L-Mul,无需额外训练,就可以用最小的性能损失替代复杂的张量乘法,实现更高效的注意力机制,如下所示:
其中L-matmul(Q, K^T)表示矩阵乘法操作,其中所有常规浮点乘法都被替换为整数加法,用L-Mul实现,显著降低了计算资源消耗。
精度分析的目标是确定L-Mul近似计算的精度,相当于将浮点数的小数部分舍入到多少位,并和具有2位或3位尾数的fp8(e5m2或e4m3)进行比较。
考虑正浮点数x、y,并明确舍入后要保留的k位,可以写成以下格式:
其中x_k、y_k是x_m、y_m的前k位,x_r、y_r是k位舍入后将被忽略的剩余位的值。x′、y′是保留尾数前k位并进行舍入后的数值。
考虑x和y在全精度下有m位尾数。例如,FP16有10位尾数,BF16包含7位。
乘法运算Mul(x, y) = x · y的误差及其期望值可以表示为:
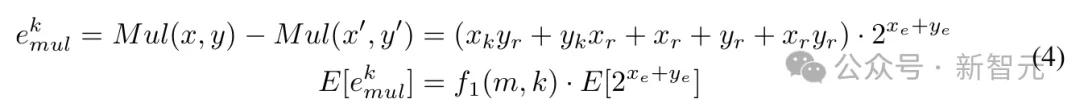
与k位尾数的浮点乘法相比,k位尾数L-Mul的误差为:
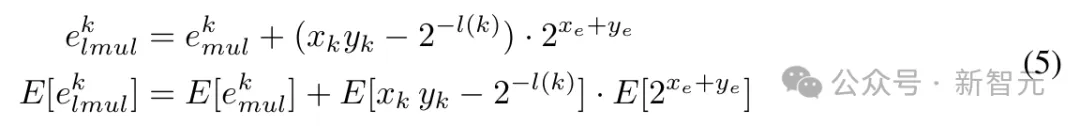
利用上述方程,可以计算k位L-Mul和浮点乘法之间精度差的期望值,具体来说:
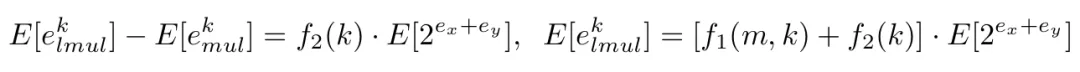
当x_m、y_m呈均匀分布时,可以计算以下期望:

通过估计f1(m,k)和f2(k)并进一步推断E[e^k_{lmu}k] 和 E[e^k_{mul}]可以得知, 如果是在操作数均匀分布的情况下,L-Mul比fp8_e5m2更精确;然而,预训练LLM的权重分布通常是存在偏差的。
这种近似计算究竟能否适用于当前的LLM,还需要实验结果来证明。
基于五个流行大语言模型的组合权重分布,实验结果发现,在实践中,L-Mul可以在使用5位尾数的情况下实现超越fp8_e4m3的更高准确度。
此外,结合门运算的复杂度估算可以进一步证实,L-Mul比fp8乘法更加高效且准确。这一结果突显了L-Mul在低精度计算中的潜在优势。
关于精度和成本分析的更详细理论推导可见于论文2.3节以及附录A。
要证明L-Mul的实际应用价值,就需要在LLM的实际任务上运行。
论文选择了各种基于Transformer的语言模型,包括Llama 3.1、Mistral、Gemma 2等,并在各种语言和视觉任务基准上评估了L-Mul算法的数值精度。
对比全精度模型权重的运行结果,可以证明,对基于Transformer的LLM而言,在注意力机制中用L-Mul替换标准乘法运算可以达到几乎无损的近似效果,可以在微调或免训练设置下替换Transformer层中的不同模块。
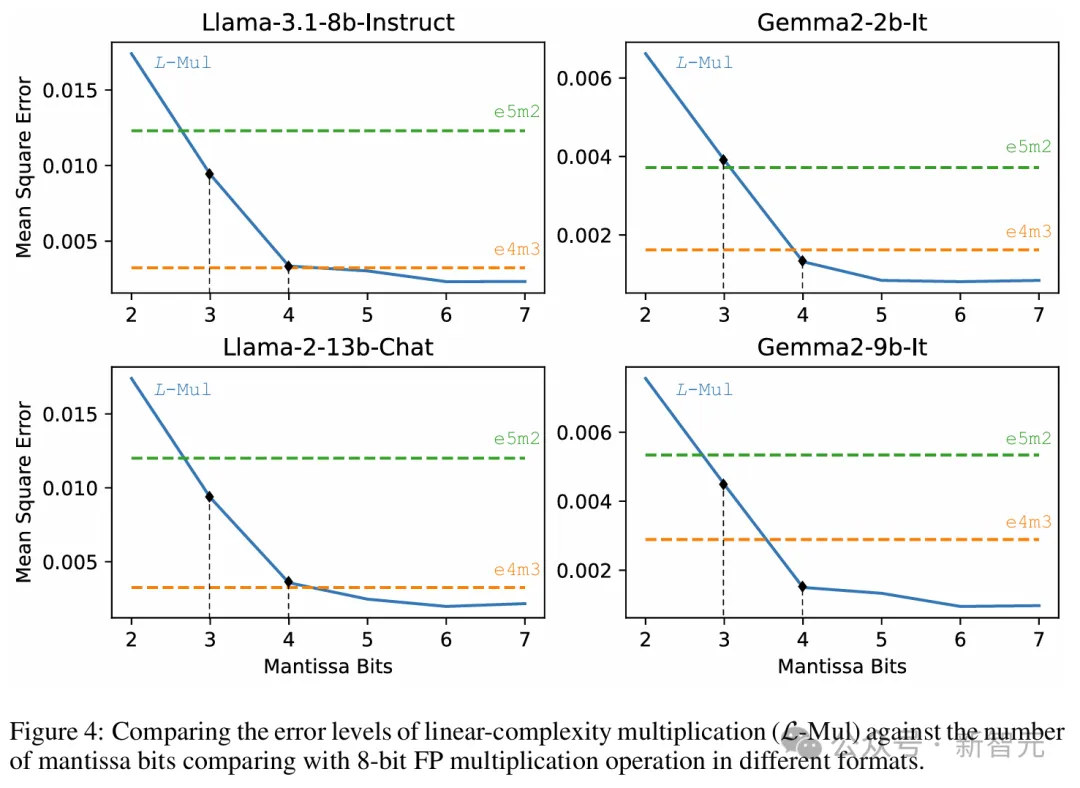
图3展示了选择不同k值和l(k)值的均方误差(mean square errors)结果,实验包含Llama 3.1和Gemma 2的两个小模型,在GSM8k数据集上运行。
在两个模型中,使用3位尾数的L-Mul比fp8_e5m2更精确,而使用4位尾数的L-Mul可以达到或近似于fp8_e4m3的误差水平。
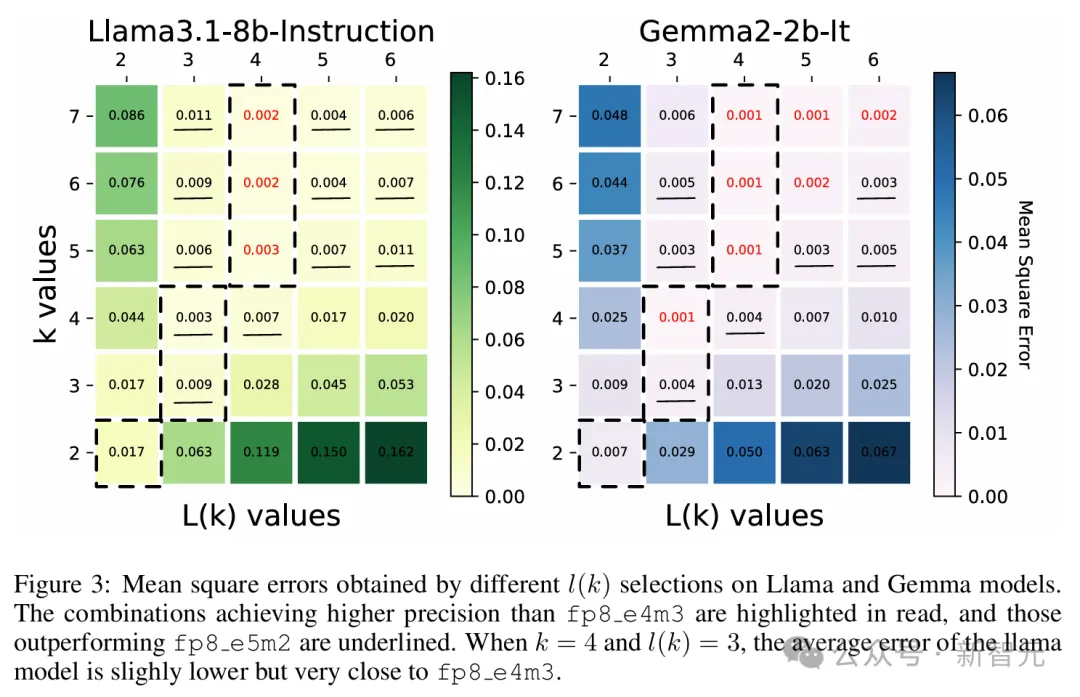
红色表示平均误差低于fp8_e4m3,下划线表示误差介于e4m3和e5m2之间
以上两个模型的平均误差如图4所示。
前面的理论推导显示,L-Mul在使用的计算资源少于fp8_e5m2时,期望误差可以低于fp8_e4m3,此处的实验结果正式了前面理论估计的正确性。
实验表明,在各种规模的LLM中,使用6位尾数FP操作数的L-Mul算法近似达到最低平均误差,显著优于e5m2、e4m3两种fp8格式。
此外,3位和4位尾数的L-Mul分别达到或超过了fp8_e5m2和fp8_e4m3的精度。
L-Mul与不同格式fp8浮点是进行乘法运算的误差水平比较
本节的实验旨在证明,L-Mul可以在不损失性能的情况下替代注意力机制中的张量乘法,而使用fp8乘法则会降低推理精度。
这就意味着,L-Mul可以在降低注意力计算能耗80%的同时达到相同的推理性能。
对于文本任务,表2展示了Llama和Mistral模型在各种自然语言基准测试上的评估结果,包括MMLU、BBH、ARC-C等。
结果表明,L-Mul不仅显著减少了计算资源,而且在绝大多数测试中(12/14)的得分高于fp8_e4m3。
与bf16推理相比,性能差距被降低到最低水平。在两个模型中,bf16和L-Mul之间在常识、结构化推理和语言理解方面的平均性能差异仅为0.07%。
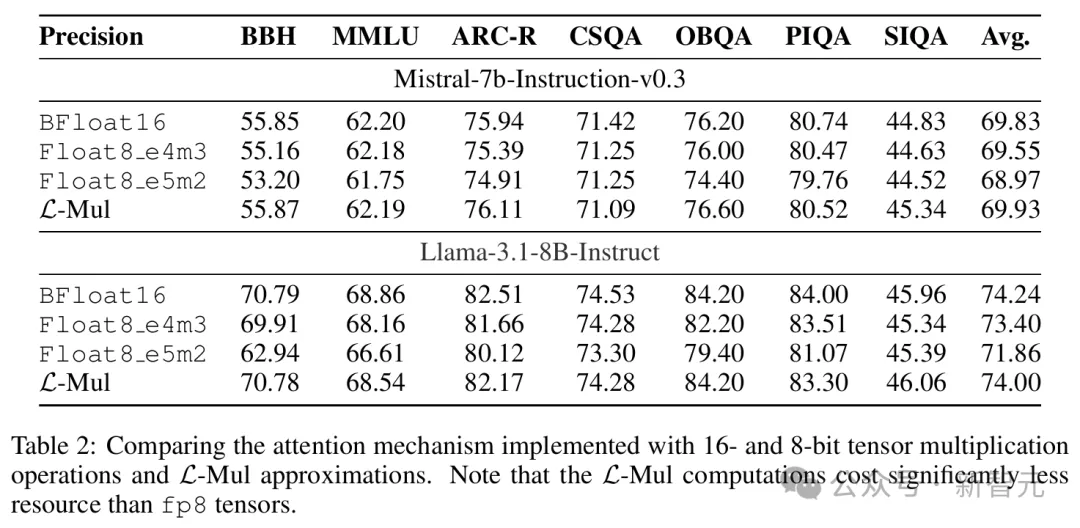
值得注意的是,对于Mistral和Gemma2两个模型,基于L-Mul的注意力机制与bf16基准相比略微提高了平均性能,分别达到52.92%和47.01%。
Llama3.1使用L-Mul时,准确率略低于bf16,但仍高于fp8_e4m3和fp8_e5m2。
相反,将注意力计算中的张量四舍五入到fp8_e5m2会导致显著的性能下降,尽管e5m2比L-Mul更复杂。
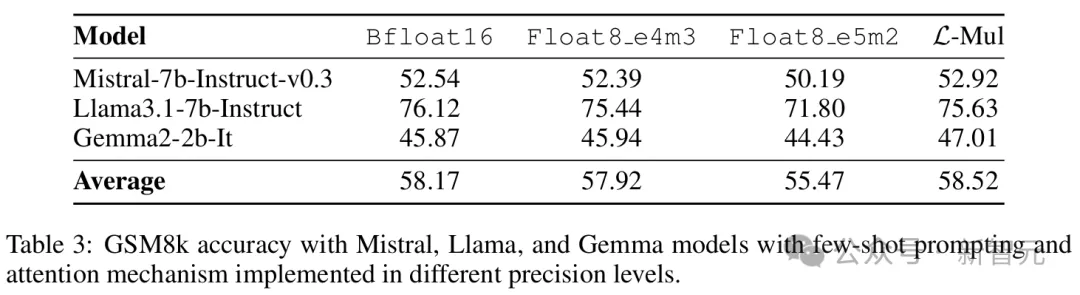
3个语言模型在GSM8k数据集上使用少样本提示的运行结果,包括L-Mul方法和3种精度bf16、fp8_e4m3、fp8_e5m2的对比
视觉-语言任务主要用Llava模型进行了测试,结果如表4所示。
除了在TextVQA基准上的准确率差距略大,达到了0.5%,在POPE、VQAv2、Llava-Bench、VizWiz等其他基准上,L-Mul达到了和bf16相似甚至更好的性能。
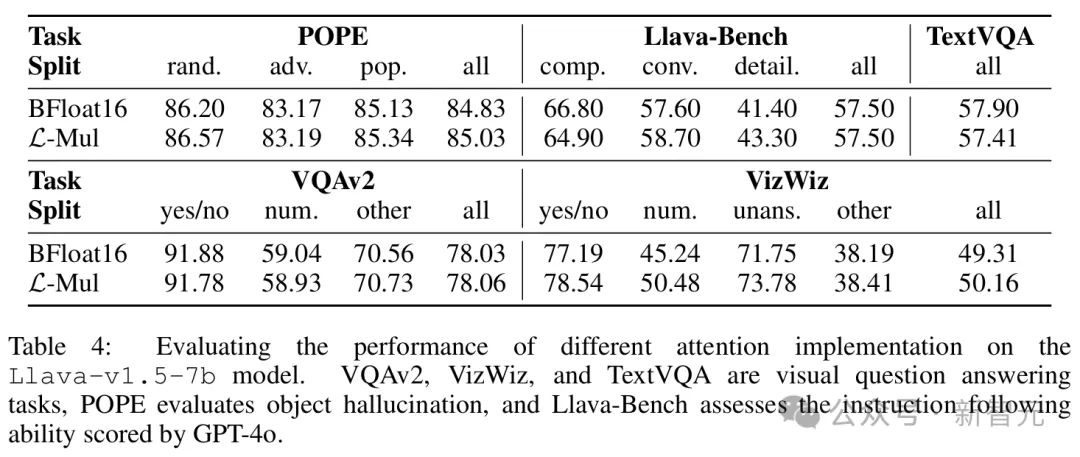
此外,误差估计和消融实验(表5)可以进一步表明,在无需额外训练的设置下,4位尾数的L-Mul可以达到与fp8_e4m3相当的准确性,而3位尾数的L-Mul优于fp8_e5m2乘法。

以上的实验结果,是直接将预训练LLM从标准注意力适配到新的基于L-Mul的注意力机制运行的,没有进行额外训练。
进一步的研究还表明,微调可以弥补L-Mul和标准乘法之间的性能差距。
本节的实验中,不仅在Gemma2的注意力机制层中实现L-Mul,而且对于模型中所有乘法运算——包括线性变换中的矩阵乘法、元素级乘法以及注意力机制层内的乘法,都使用L-Mul和fp8_e4m3进行近似,之后在GSM8k数据集上对更新后的模型进行微调。
将注意力机制、线性变换和逐元素乘积中的所有乘法运算替换为3位尾数L-Mul的模型进行微调,其性能可与使用fp8_e4m3累积精度的标准模型微调相媲美。
值得注意的是,本实验中的L-Mul操作使用3位尾数(k=3),累加精度为fp8_e4m3,以探索极其高效的设置。
结果可以看出,在fp8精度下,微调后的fp8_e4m3 L-Mul模型达到了与标准微调fp8_e4m3模型相当的性能。
这表明,L-Mul可以在不影响微调模型性能的情况下提高训练效率。此外,也揭示了训练L-Mul原生LLM的潜质,用于更加精确、节能的模型托管。

微调后fp8和L-Mul模型在零样本设置下的评估

Hongyin Luo是MIT计算机科学与人工智能实验室(CSAIL)的研究科学家,在Jim Glass博士领导的口语语言系统(SLS)小组工作。
他于2016年在清华大学获得学士学位,导师是NLP领域的大牛级人物:刘知远和孙茂松。
随后于2022年在MIT EECS获得博士学位,专注自然语言处理中的自训练研究。

他的研究重点是提高语言模型的效率、透明性和推理能力。最新研究结合了自然语言与不同的形式推理引擎,包括蕴涵模型(entailment model)和程序解释器。
他构建了小型语言模型,以1/500的计算量表现优于GPT3-175B,开发了处理搜索引擎噪声的自我去噪语言模型,以及无需任务特定示例即可实现准确推理的自然语言嵌入程序。
参考资料:
https://arxiv.org/abs/2410.00907
https://luohongyin.github.io/
文章来自于微信公众号“新智元”,作者“Hongyin Luo”



【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
