# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
顶流新会议首届COLM成功举办,Mamba等4篇论文获得杰出论文奖。

新架构Mamba系列经历了原论文被ICLR拒稿引起热议等风波后,Mamba 2后续被ICML 2024接收,现在开山之作也终于获得了应有的认可。
虽然COLM刚刚才办第一届,热闹程度已不输老牌顶会,根据参会者现场返图,海报区人挤人。

作为专注语言建模的会议(Conference on Language Modeling),四篇获奖论文分别探讨了序列建模的新架构、语言模型中的评估问题、数据中的知识截止问题、以及生成文本的检测。
Mamba作者Tri Dao参会感觉,由于专注于单一领域,人们投入程度更高。
第一篇:Mamba: Linear-Time Sequence Modeling with Selective State Spaces,团队来自CMU、斯坦福
https://arxiv.org/abs/2312.00752
获奖理由
Mamba 解决了结构化状态空间序列模型中的关键架构和实现问题,创造了一个潜在可行的Transformer替代方案。虽然建模长序列的最优架构仍有待商榷,但这是具有次二次复杂性的序列建模中的一个重要且有影响力的进步。

第二篇:Auxiliary task demands mask the capabilities of smaller language models,团队来自哈佛、斯坦福
https://arxiv.org/abs/2404.02418
获奖理由
本文借鉴了人类儿童推理行为的研究,认为对语言模型性能的解释应考虑任务需求——与正在评估的能力无关但可能影响模型分数的因素。作者表明,任务需求对小型语言模型的影响尤为显著,表明当前的评估可能低估了它们的能力。

第三篇:Dated Data: Tracing Knowledge Cutoffs in Large Language Models,团队来自约翰霍普金斯大学
https://arxiv.org/abs/2403.12958
获奖理由
本文介绍了大语言模型训练中的“有效知识截止”:与训练期间使用的数据的特定部分相关的日期。作者引入了一种简单的方法来评估资源的有效截止,并研究了有效截止与报告截止之间的不一致,揭示了大语言模型中数据文档的重要后果。

第四篇:AI-generated text boundary detection with RoFT,团队来自华为俄罗斯AI基础与算法实验室、伦敦玛丽女王大学等
https://arxiv.org/abs/2311.08349
获奖理由
本文提出了一种思考生成文本检测的新方法:检测包含人类编写和人工智能生成的文本的文档中人类编写和人工智能生成的文本之间的过渡。鉴于大型语言模型如何用于协作文本创作,这种观点特别有先见之明。实验表明,基于困惑度的方法和内在维度估计优于传统分类器,并且能够很好地适应混合了人类和人工智能生成的文本的环境中的细微挑战。

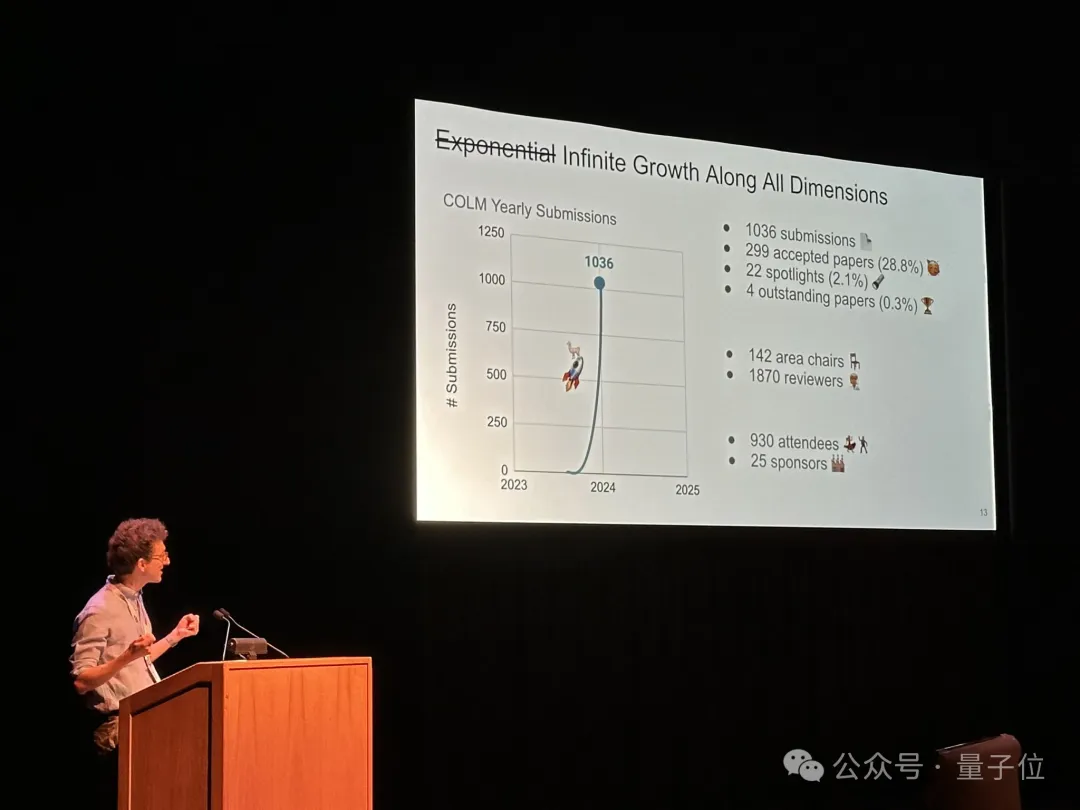
主办方介绍了了第一届COLM的总体情况,今年共有1036篇投稿,入选率28.8%。选出22篇spotlights,4篇杰出论文,现场930人参会
还开了一个由于从0开始,增长趋势是无穷大的小玩笑。
首届七位组织者均是来自业界学界的大佬,其中有三位是华人学者谷歌周登勇、普林斯顿陈丹琦、Meta的Angela Fan。

除了杰出论文奖外,斯坦福AI实验室主任Christopher Manning的开幕演讲也很受关注,根据现场参会学者总结,要点如下:

文章来自于“量子位”,作者“梦晨”。




