# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当备受期待的GPT-5历经数次跳票,OpenAI全新发布的o1模型及时挽回了行业的信心,并从此为大模型领域开启了一个新的竞技方向——当推理模型大行其道时,行业如何从Infra层面着手降低推理阶段的算力成本?
9月中旬,OpenAI蓄势已久的“草莓”最终以“o1”的新命名面世,它改变了以往的技术范式,通过推理阶段的扩展(Inference time scaling law),将模型的推理能力提高到了新的高度。
这条被OpenAI称之为“新范式”的技术路径,为大模型领域带来了一系列变革,其中尤为重要的一点是自此将推理层面算力建设的必要性推到了更为突出的中心位。为达到理想效果,行业必须要解决推理效果、效率与成本之间的不可能三角问题。
从AI Infra层面来看,这背后涌现的是创业公司的新机会。对此,以趋境科技为代表的算力层玩家开始推行一种并非为了兼顾训练和推理而顾此失彼,而是专注于推理场景成本优化的一体机产品,这可能是大模型领域一笔浓墨重彩的技术叙事新篇章。

更进一步的,与当前行业主要针对GPU算力利用率进行单点优化的传统方案相比,趋境科技大模型知识推理一体机采用了业界首创的全系统推理架构。其通过“以存换算”技术释放存力作为算力的补充,降低对算力的需求;同时采用“异构协同”的思路,紧密联动HBM/DRAM/SSD和CPU/GPU/NPU全系统异构设备,突破显存容量的限制,充分释放全系统的存力和算力。
这一创新方案突破了以往方案的理论优化极限,实现了整合机器所有异构算力资源的目标,使得推理吞吐量提升超过10倍,大幅降低了大模型的落地成本。
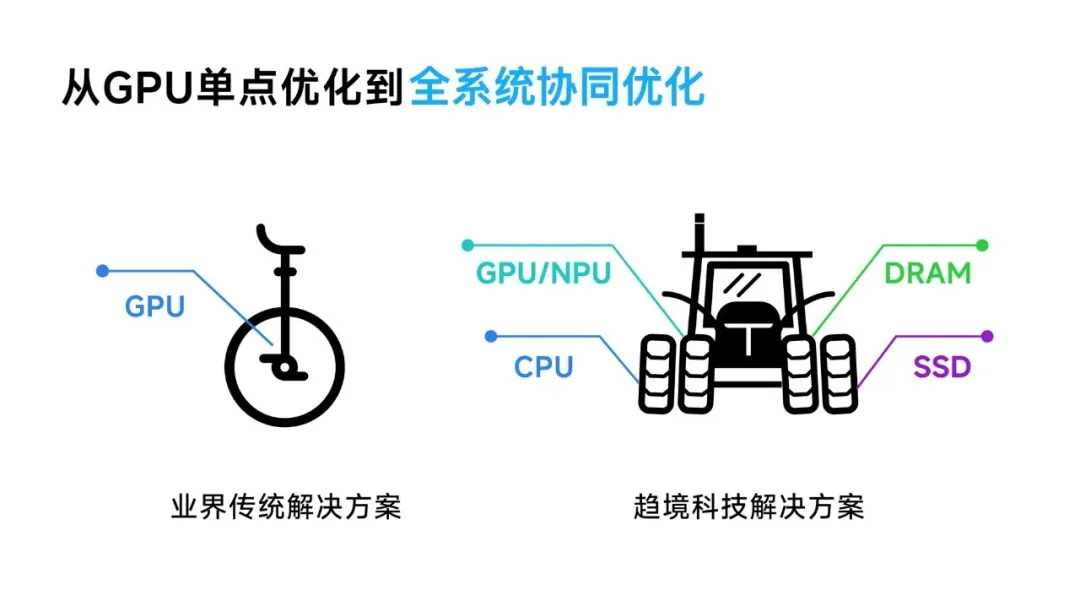
作为兼顾高性能、低成本、高效率三者的解决方案,趋境科技大模型知识推理一体机将有力推动大模型从研发层面的“训练自由”走向落地层面的“推理自由”。
传统GPT 1到4时代的Pre-Training(预训练)阶段Scaling Law依赖模型参数、训练算力和数据规模三方面的共同增长。但随着互联网世界客观存在的高质量数据逐渐耗尽(假定算力仍不受限的情况下),这一三角关系陷入瓶颈状态,已无法快速有效地提升模型性能。
不过,OpenAI o1的出现至少在现阶段冲散了这层迷雾。通过结合强化学习等技术,该模型将CoT能力内化到模型中,通过将复杂问题拆解为多个连续关联的简单问题,模仿人类逐步解决问题的方式,从而提升了模型的推理性能。

在这背后,OpenAI o1的特性是无论在训练还是后续部署阶段都大量消耗推理算力进行复杂的思维链生成。这种特性使得o1不仅在预训练阶段表现出色,而且可以在后训练阶段通过增加推理计算量来进一步提升性能,即所谓的推理时缩放律(Inference time scaling law)。
至此,AI大模型领域通往AGI征程的Scaling Law第二曲线正式确立。
而在这一新的阶段,算力消耗重点由训练层迁移至推理层,推理层在模型落地后对应用效果承担直接责任,确保推理算力,已经成为大模型产业持续发展的核心需求。同时,一旦某种技术范式成为新的行业风向,整个行业从研发到应用落地的推理算力需求将迎来爆炸式增长。要确保模型在应用领域实现规模化效应,对推理算力的效率与成本优化成为关键任务。
这意味着以推理为中心的算力建设新范式正式到来。
OpenAI o1的出现对于推理算力层的改变到底有多重要,其显著受限的算力成本就是一个明显的例证。在每个ChatGPT Plus付费用户每周已经可以使用GPT-4o 4480次的情况下,对o1-preview和o1-mini的使用依然分别被限制到只有每周30次和50次。
另外,o1的回答时长也从GPT系列的秒级增长到数十秒乃至更久,背后需要处理的文本量也大幅提升。这两者都意味着更高的算力成本。受此影响,OpenAI o1仍处于路透阶段时就带动了英伟达和微软的股价一同上涨。
这高启的推理成本使得企业部署大模型时要构建的效果、效率和成本之间的平衡愈发困难,形成所谓的“不可能三角”。通俗来讲,“不可能三角”就是既要通过能力更强的大模型实现好的效果,又要在实际的部署中提供更低的响应延迟,同时还要做到更低的成本。实际上,这也是如今千行百业落地大模型的痛点所在。

这背后可能的一种原因是,传统算力建设范式下的算力集群方案主要为训练场景打造,对于推理阶段显得成本高昂。
以英伟达HGX方案为例,这是大模型训练中广泛采用的算力建设方案之一。由于其设计重点在于支持大规模的模型训练,通常涉及多个高端GPU和高速互连技术。对于推理任务,这些高昂成本的开销可能并不经济。
也就是说,在技术的两面性下,传统算力建设范式体现在训练阶段的优势,在推理阶段得不到凸显,甚至可能成为拖累。
对此,已有业界观点将传统算力构建方式中价格高昂的“GPU超级节点”方案比喻为“AI大型机”。这种比喻借鉴了过去技术革新的历史教训,指出仅有从依赖IBM等公司的昂贵大型计算机转向以Google为代表的基于全系统优化的低成本x86服务器集群时,我们才真正开启了大数据时代。
同样地,为了让广泛的企业能够更有效地部署大模型解决方案,提供在成本和部署效率上都有优势的方案变得至关重要。因此,迅速找到一个大模型时代下在成本效益和部署效率上都有明显优势的“x86服务器”方案显得尤为紧迫,也已成为行业的必然趋势。
纵观国内当前AI Infra层的创业公司,这个赛道不是没有尝试给出解法。事实上,作为在2024年初新入局的玩家,上半年刚完成一轮天使轮融资的趋境科技提供了一种全新选择:大模型知识推理一体机。
此前,行业的技术思路更着重于优化GPU利用率,但在新的市场需求背景下,这并不足以解决多个数量级的差距。尤其在国产GPU产品与英伟达有显著差距的情况下,算力性能与推理任务需求量的失衡更加严重。
因此,趋境科技的新产品升级思路,选择从体系结构入手,其首创全系统推理架构能够充分协同存储、CPU、GPU、NPU等多种设备,从而突破了以往方案的理论优化极限,实现了整合机器所有异构算力资源的目标,使得推理吞吐量提升超过10倍,大幅降低了大模型的落地成本。
趋境科技的“大模型知识推理一体机”产品,通过软硬一体化的方式,支持本地部署百亿级别以上的大模型,并开放API接口,支持第三方灵活调用,同时提供企业assistant使用页面,提供“开箱即用”的私有化大模型部署和推理服务。其核心优势就是高性能、低成本、高效率,基本上解决了企业落地大模型的大部分顾虑。
这种效果得益于趋境科技看待行业的独特技术视角。在趋境科技看来,大模型推理优化不能只关注GPU,磁盘、内存、CPU同样可以为大模型提供“异构算力”。这背后衍生出两项核心技术策略作为支撑。
其一便是趋境科技业界首创的“以存换算” 技术。
早期的大模型推理架构将每次推理视为独立请求,缺乏高效处理所需的“记忆”能力。尽管后续在技术有所更新,但大模型仍主要依赖于“死记硬背”。
针对这一问题,趋境科技创新性地设计了“融合推理(Fusion Attention)”思路来利用存储空间,即便是面对全新的问题也可以从历史相关信息中提取可复用的部分内容,与现场信息进行在线融合计算。这一技术显著提升了可复用的历史计算结果,进而降低了计算量。
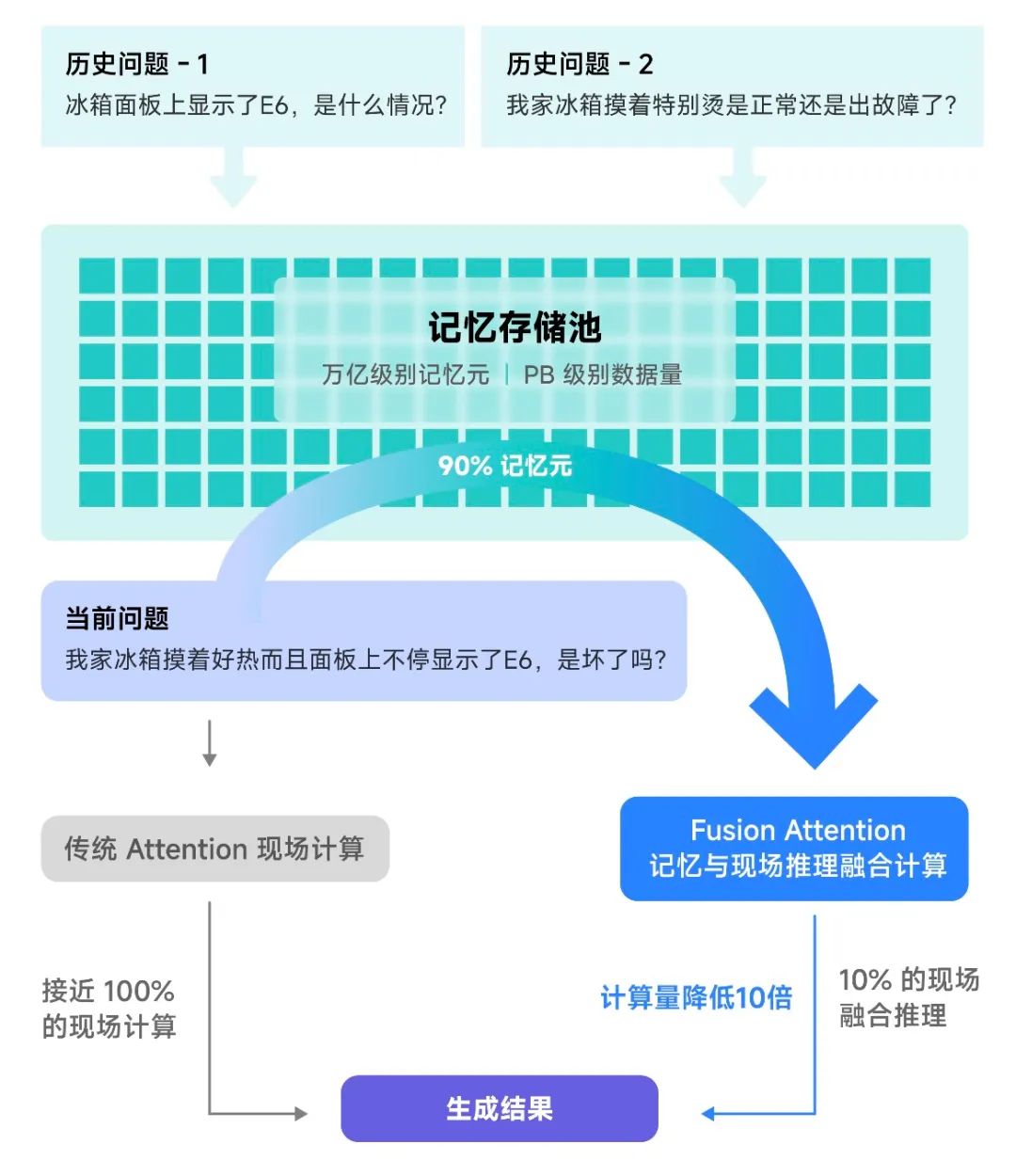
这样一来,尤其在RAG场景中,“以存换算”能够降低把响应延迟降低20倍,性能提升10倍。
在此基础上,趋境科技首创的“全系统异构协同”架构设计也成为重要技术支撑。该架构是首个允许在单GPU卡上支持1Million超长上下文的推理框架,以及首个单GPU上运行2000亿参数MoE超大模型等等。
目前,趋境科技已联合清华大学一起将异构协同推理框架的个人版,名为KTransformers的框架在GitHub开源,并在Hugging Face等开源社区引起广泛关注和讨论。行业合作伙伴也对此兴趣颇高,已有多家知名大模型公司主动抛出橄榄枝,与其共同发起大模型推理相关的项目建设。
趋境科技AI知识推理机一体机采用的全系统异构协同架构是全量商业版,在开源版的基础上协同性能更强,加入了针对团队的多卡高并发调度、RAG支持等策略。
回顾行业发展历程,AI Infra的主要优化方向包括模型的训练和推理过程。训练阶段包括参数调优、数据训练等环节,是多家大厂和创业公司跟进的“主流方向”,但趋境科技此前就曾预判,随着模型架构逐渐收敛于Transformer及其变种,训练优化的技术壁垒和提升空间正在缩小。因此,相比之下,推理端的优化蕴含更大的潜力。
可以说,OpenAI o1开启了大模型的技术新范式,而趋境科技则踩中了与之对应的AI Infra层的技术趋势与爆发机遇。
面向新的技术周期,以趋境科技为代表的推理算力建设范式革新,将有机会真正破局算力需求的增长困境。通过提出高性能、低成本、高效率的解决方案,它将有力推动大模型从研发层面的“训练自由”走向落地层面的“推理自由”。
文章来自于“智能涌现”,作者“智能涌现”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
