# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。
其中,RLHF 是一种广泛使用的方法,依赖于从人类反馈中学习强化策略。RLHF 的流程包括两个阶段:首先,通过人类偏好数据训练奖励模型(Reward Model, RM),然后使用该奖励模型指导策略模型(Policy Model)的强化学习优化。然而,RLHF 存在若干显著问题,如高内存占用、训练不稳定以及流程复杂等。
为了解决 RLHF 的复杂性,DPO 方法被提出。DPO 简化了 RLHF 的流程,将强化学习的训练阶段转化为一个二分类问题,减少了内存消耗并提高了训练稳定性。但 DPO 无法充分利用奖励模型,且仅适用于成对的偏好数据,无法处理更为广泛的反馈类型。
此外,KTO 进一步扩展了 DPO,能够处理二元数据(如正向和负向反馈),但它同样有其局限性,无法统一处理不同类型的反馈数据,也无法有效利用已有的奖励模型。
在这种背景下,来自 Salesforce、厦门大学的研究团队提出了一种名为 UNA 的新方法,它通过一种通用的隐式奖励函数,统一了当前主流的大规模语言模型(LLM)对齐技术。主要包括 RLHF、DPO 和 KTO,这些技术的结合不仅简化了模型的训练流程,还提高了模型对齐的性能,稳定性和效率。

UNA 的核心创新点在于通过一个(generalized implicit reward function)将 RLHF、DPO 和 KTO 统一为一个监督学习问题。UNA 的创新体现在以下几个方面:
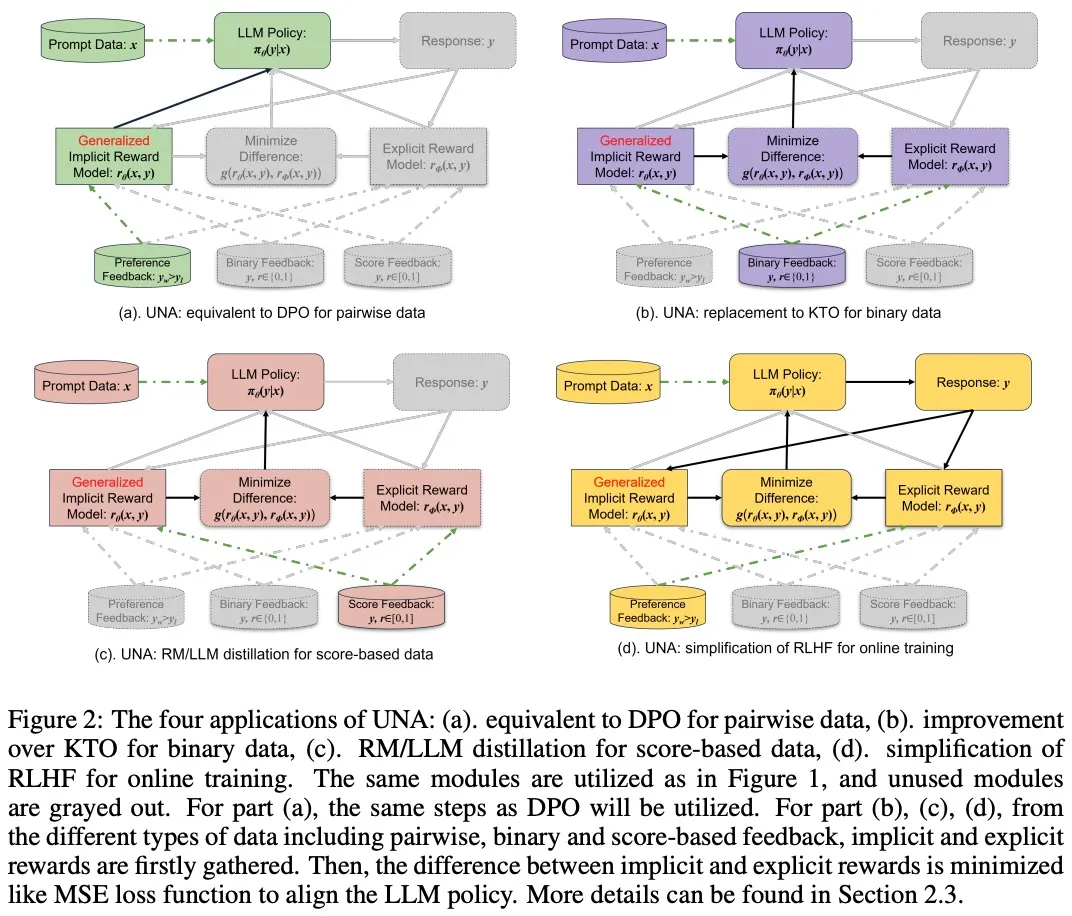

UNA 的理论基础源于对 RLHF 目标函数的重新推导。研究人员证明,给定 RLHF 的经典目标函数,最优策略可以通过一个隐式的奖励函数来诱导。该隐式奖励函数是策略模型与参考策略之间的对比结果,通过这个函数,UNA 能够将不同类型的奖励信息整合到统一的框架中进行处理。

研究人员通过一系列实验验证了 UNA 的有效性和优越性。在多个下游任务中,UNA 相较于传统的 RLHF、DPO 和 KTO 都有显著的性能提升,特别是在训练速度、内存占用和任务表现等方面。以下是实验结果的主要亮点:
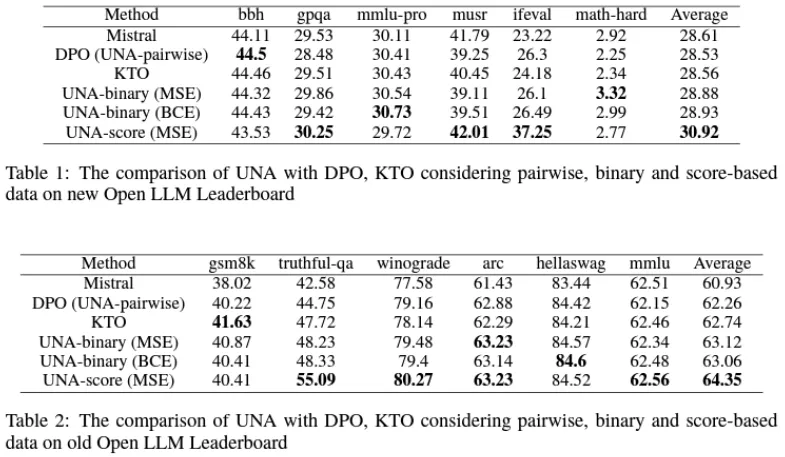
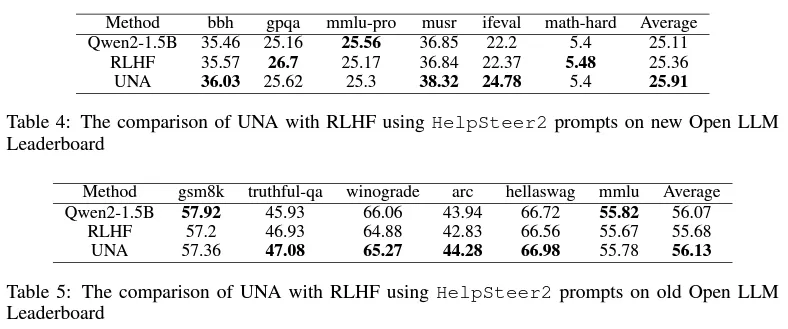
UNA 的提出标志着大规模语言模型对齐技术的一个重要进展。通过统一 RLHF、DPO 和 KTO,UNA 不仅简化了模型的训练流程,还提高了训练的稳定性和效率。其通用的隐式奖励函数为模型的对齐提供了一个统一的框架,使得 UNA 在处理多样化反馈数据时具有更强的适应性和灵活性。实验结果表明,UNA 在多个下游任务中表现优越,为语言模型的实际应用提供了新的可能性。未来,随着 UNA 的进一步发展,预期它将在更多的应用场景中展现出强大的能力。
文章来自于“机器之心”,作者“机器之心”。




