# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
米开朗基罗,文艺复兴时期著名的雕塑家。
曾有人问他是如何创作出如此伟大的作品,他回答说:
「The sculpture is already complete within the marble block, before I start my work. It is already there, I just have to chisel away the superfluous material.」
「在我开始工作之前,雕塑已经在大理石块中完成了。它已经在那里了,我只需要凿掉多余的材料。」
(小编PS:在我写稿之前,稿子已经在字典里完成了......)

这种写意的表述可以类比到许多工作,比如大语言模型从上下文中理解信息。
LLM可能面对着很长的语境(大理石),需要「凿掉」其中不相关的信息,才能理解有效的内部结构(雕塑)
所以,对于LLM来说,米开朗基罗的能力就可以是长上下文的能力。
然而,无论是用户还是研究者都不免会有疑问:你这瓜保熟吗?号称百万token的长上下文真的能理解吗?

近日,来自谷歌DeepMind的研究人员提出了Michelangelo,「用米开朗基罗的观点」来测量任意上下文长度的基础模型性能。

论文地址:https://arxiv.org/abs/2409.12640
作者设计了用于长上下文推理评估的潜在结构查询框架LSQ,框架包含了长上下文评估的现有工作。
Michelangelo由三个简单的潜在结构查询实例组成,每个实例负责测量的能力和实例化的数据分布有所不同。

研究人员在目前性能最好的几个模型上进行了高达1M上下文的评估。
实验证明,GPT和Claude模型在128K的上下文范围中表现都不错,而Gemini也确实做到了在高达1M的上下文中具有泛化能力。
然而,如果是比较困难的推理任务,大家就基本全军覆没了。

上图展示了几个前沿模型在框架的其中一项任务MRCR(Multi-Round Co-reference Resolution)上的性能。
MRCR是一项合成的长推理任务,使用简单的度量进行评估,并在许多模型族中使用固定提示,实验中所有型号的LLM在32K之前的区间中,性能都随上下文长度而显著下降。
这一方面可以看出大家的能力都有点水分,另一方面也表明在比较短的长度(32K)上就已经可以摸清底细了。
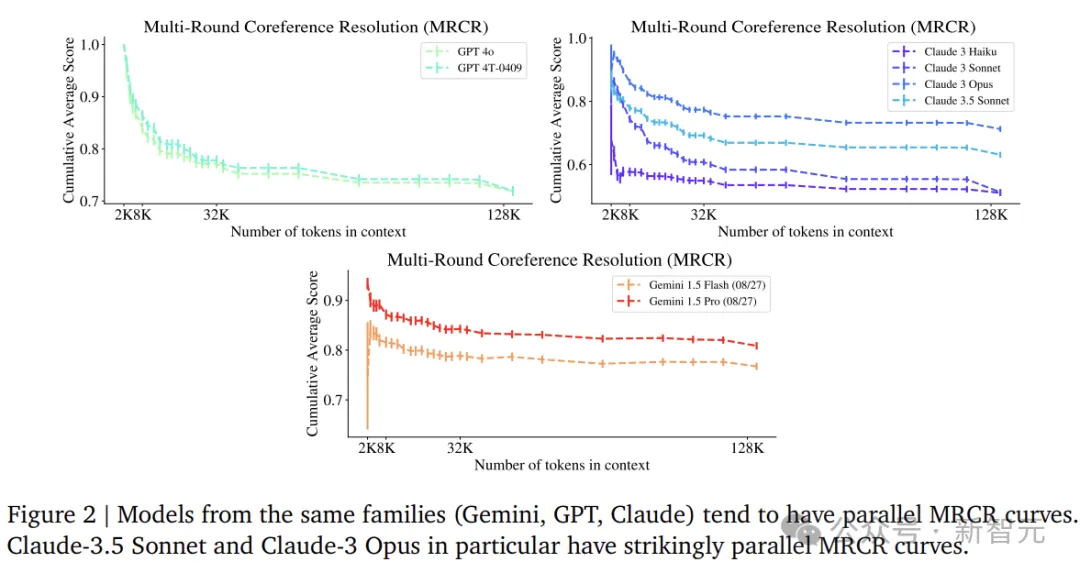
对比不同模型系类的MRCR实验,可以发现有趣的联系——近似平行的曲线,这可能暗示这些模型在训练过程中存在独特的相似之处(即使性能可能存在绝对差异)。
通过要求模型从结构中提取信息,而不是从键中提取值,我们可以更深入地测试语言模型上下文理解能力,而不仅仅是检索。
尽管随着超长上下文的刷榜,基准测试也在不断跟进,比如在大海中多捞几根针,又或者是更现实的长语境问答评估。
但归根结底,这些都只是不同环境中的检索任务,而模型检索一个或多个事实的能力并不一定意味着模型能够从完整的上下文中综合信息。
另外,目前的长上下文基准还存在以下一些问题:
相对较小的上下文长度;
高度人工性,没有自然语言或代码设置;
需要大量的人力才能延伸到更长的上下文长度;
有时,回答问题所需的信息可能存在于预训练数据中,或者可以短路上下文长度并使用更多本地信息回答问题。
Michelangelo由三个直观且简单的长上下文综合任务基元组成,它们要求模型综合散布在整个上下文中的多条信息以产生答案,并测量模型综合能力的不同方面,以提供对长上下文模型行为的更全面理解。
Michelangelo的每项评估都定位在自然语言或基于代码的环境中,与现有基准相比,合成程度较低。
任务在上下文长度上可以任意扩展,同时保持固定的复杂性,并且不会导致逻辑矛盾或短路。
另外,实例的生成基于自然语言的方法,不依赖于现有的评估集或互联网数据,因此避免了泄露。
考虑一个简短的Python列表,并提出一系列修改该列表的操作,比如append、insert、pop、remove、sort、reverse。
给定操作序列,模型需要输出结果潜在列表的视图:能够打印列表的完整切片、列表切片的总和、最小值或最大值,列表的长度(列表长度不取决于实例的总上下文长度,而是取决于相关操作的数量)。
为了填充上下文,这里统一采用三种不影响列表潜在状态的策略:
1)插入print语句(Do nothing);
2)插入偶数个反向操作;
3)插入所有在本地自我抵消的操作块。

作者考虑了三个复杂度级别,分别包含1个、5个和20个相关操作。
使用近似度量来对Latent List任务进行评分,以下代码描述了计算此分数的确切方法:

在MRCR任务中,模型根据与用户之间的长时间对话,来进行不同主题的写作(例如诗歌、谜语、论文)。
这里使用PaLM 2模型提供与每个请求和主题相对应的多个输出。
在每个对话中,包含不同于其余对话的主题和写作格式的用户请求将随机放置在上下文中。

将对话作为上下文,要求模型重现其中一个请求产生的对话的输出。
MRCR任务还通过格式和主题重叠,来创建与查询相似的对抗性样本。
比如,请求「Reproduce the poem about penguins.」要求模型区分关于企鹅的诗和关于火烈鸟的诗,而「Reproduce the first poem about penguins.」要求模型对顺序进行推理。
作者通过模型输出和正确响应之间的字符串相似性对MRCR进行评分。
IDK任务向模型展示大量文本并提出一个问题,鉴于预训练语料库庞大,该问题没有客观答案。
例如,可能有一个关于一个女人和她的狗的虚构故事,其中详细说明了狗的名字和年龄,但没有详细说明它的颜色。然后向模型提问:女人的狗是什么颜色的?
此任务的每个实例,都会提供四个选项作为答案,其中一个始终是「I don't know」,而其他选项都是相对合理的回答。
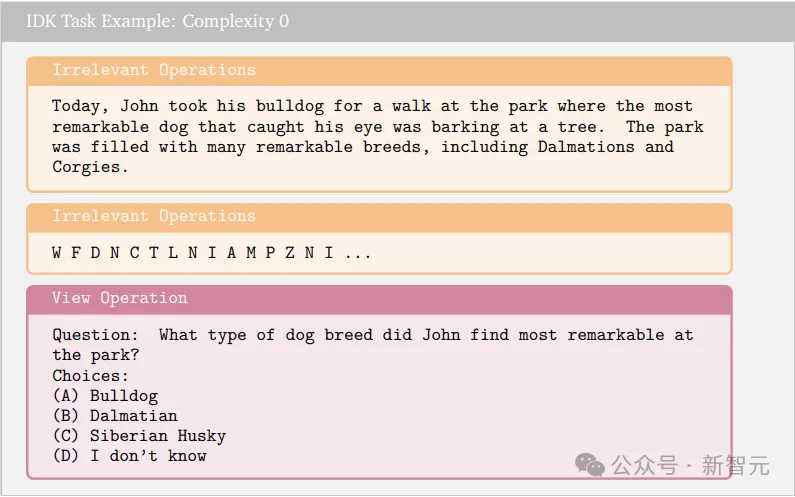
评估中设置70%的任务实例对应于真实答案是「I don't know」,30%的实例对应于在上下文中可找到答案(即简单检索任务),最后根据模型输出是否具有正确答案进行评分。
长上下文评估通常应遵循以下原则:
通常可扩展至任意上下文长度;
由相关信息的数量编制索引的复杂度;
上下文长度难度应与任务对应的复杂度解耦,没有不相关的信息;
覆盖自然语言文本和代码(两个基本领域);
避免数据泄露;
测试模型对上下文中传达的隐含信息的理解;
用尽可能少的评估次数,测试长上下文综合能力的正交维度。
本文的评估框架将呈现给模型的上下文视为一个信息流,它构成了对潜在结构的更新:完整的上下文长度就像一块大理石,里面有许多不相关的信息,LLM需要凿掉不相关的信息,才会露出里面的雕像(潜在结构)。
举个例子,你可以想象读一本描写家庭的书——父母可能会离婚,孩子长大后会结婚,长辈会去世。在这个过程中,与家谱对应的潜在结构发生了变化和更新(书中的大部分信息则根本不影响家谱)。
考虑每个评估中的128K上下文:
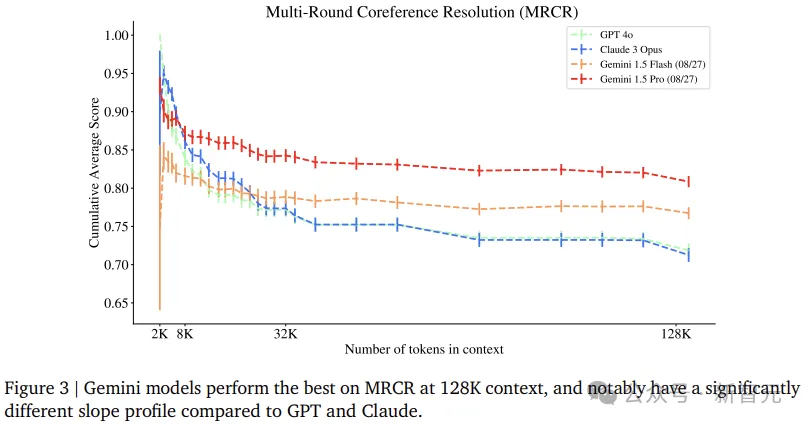
如图所示,在短上下文中,这些模型的性能最初会出现一次急剧的超线性下降。

请注意,任务复杂度在整个上下文中保持固定,因此这种下降完全是由于模型的长上下文处理能力。

之后,性能通常会趋于平缓或继续以大致线性的速度下降,并通常会持续到非常大的上下文长度。
我们可以将这种行为解释为模型具有足够好的子功能,足以在给定任务上实现一定水平的性能,并且这些子功能的长度泛化到了非常大的上下文长度。
文章来自于“新智元”,作者“alan”。



