# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI已完全融入数学家的工作流中。陶哲轩刚刚宣布,最新方程理论项目已完成99.9963%,众包之力外加AI辅助取得了重大成绩。他认为,剩余大约700个让人类头疼的难题,AI或许更有潜力。
AI,已成为菲尔兹奖得主最得心应手的工具。
大约三周前,陶哲轩提出了一个协作项目——
结合专业和业余数学家、自动定理证明器、AI工具,以及证明辅助语言Lean,来描述与4694条幺半群(magmas)方程定理定理相关的蕴含图。

这些定理最多可以使用,四次幺半群运算来表达。
也就是说,需要确定4694条定理之间可能存在4694 * (4694 - 1) = 22028942蕴含的关系真伪。

地址:https://github.com/teorth/equational_theories/blob/main/data/equations.txt
这一项目在9月25日发布当天便启动了,如今,已经紧锣密鼓进行了19天。

刚刚,陶哲轩公布了项目的最新进展:
从已解决原始蕴含关系角度来看,截至目前,项目进度已完成99.9963%。
在需要解决的22028942个蕴含关系中,8178279个被证明为真,13854531个被证明为假,只有826个仍未解决。

而且,项目每一天的进展,他都记录到了个人日志中。
一起看看,陶哲轩如何通过「众包方式」,探索数学新领域。
在集合中,有249个蕴含关系推测为假,并且很快就证明了是假的。
出于编译效率的考量,他们并没有在Lean中记录每一个证明,只在其中证明了一个较小的592790个蕴含关系集合,然后通过传递性推导出更广泛的蕴含关系集合。

例如,利用如果方程X蕴含方程Y,方程Y蕴含方程Z,那么方程X蕴含方程Z的事实。
他们还很快利用蕴含图对偶对称性,对其进一步简化。
经过项目志愿者的不懈努力,陶哲轩称现在有了很多出色的可视化工具(尚未完成的),来检查蕴含图的各个部分。
比如,如下这张图描述了方程1491:x = (y ◇ x) ◇ (y ◇ (y ◇ x ))的所有结果。

陶哲轩将其称之为「Obelix law」。它还有一个伙伴Asterix law,即方程65:x = y ◇ (x ◇ (y ◇ x ))。
如下是,他们正在研究的所有方程定理的表格,以及它们蕴含/被蕴含定理数量。
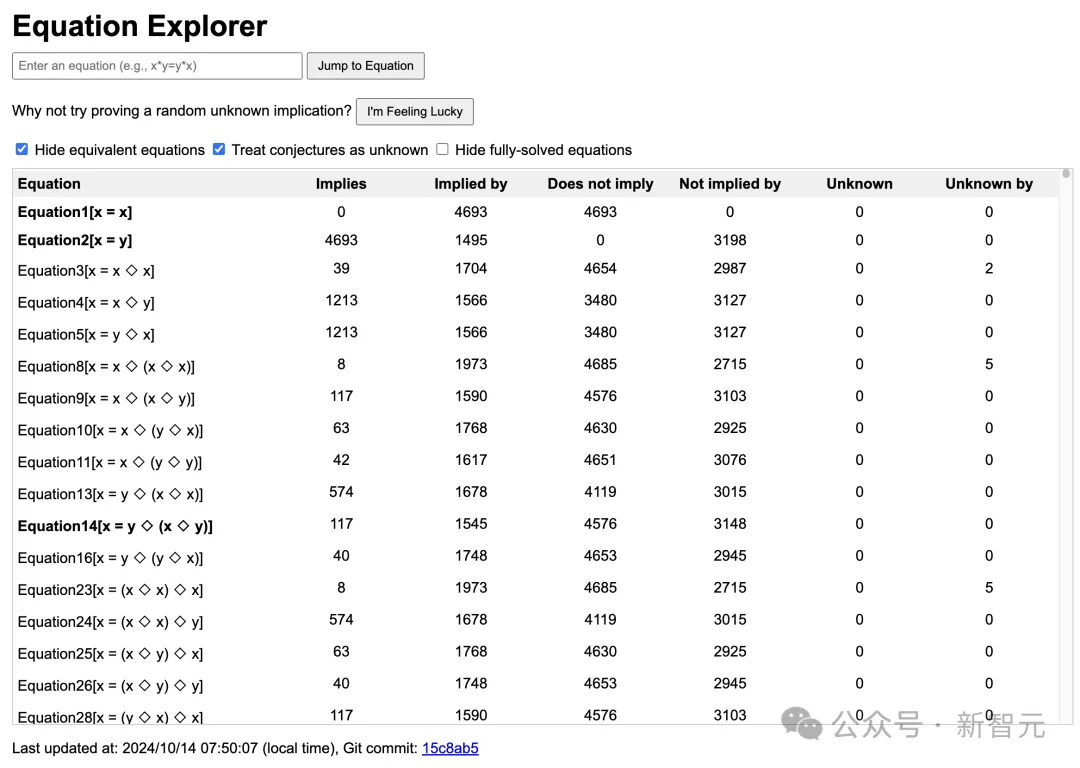
地址:https://teorth.github.io/equational_theories/implications/
这些界面也在某种程度上与Lean集成。
比如,我们可以点击查看Obelix law蕴含方程359,陶哲轩将其作为题目,让大家进行挑战。他暗示,在Lean中仅用4行就可以完成证明。

在过去的几周里,他还了解到这些定理中,有许多之前已经出现在文献中。
由此,这里编制了这些方程的「导览」。

地址:https://github.com/teorth/equational_theories/wiki/Tour-of-selected-equations
例如,除了众所周知的交换律(方程43)、结合律(方程4512)之外,一些方程(方程14、方程29、方程381、方程3722、方程3744)曾出现在一些Putnam数学竞赛中;
方程168定义了一个引人入胜的结构,被称为「中心幺半群」(central groupoid)。特别是,由Evans和Knuth研究过,并且是Knuth-Bendix完成算法的关键灵感来源;


而方程1571则对指数为二的阿贝尔群(abelian groups)进行了分类。

根据Birkhoff完备性定理,如果一个方程定理蕴含另一个,那么它可以通过有限次重写操作来证明。
不过,所需的重写次数可能相当长。
上面提到的1491蕴含359的证明已经相当具有挑战性,需要四到五次重写。
另外,方程1689蕴含方程2的证明,更是极其冗长。尽管如此,标准的自动定理证明器,如Vampire,完全有能力证明绝大多数这些蕴含关系。
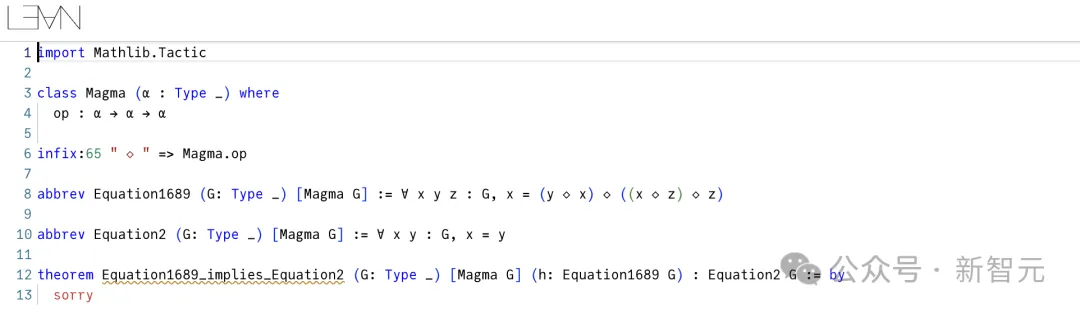
更微妙的是反蕴含关系,在这种情况下必须证明定理X不蕴含定理Y。原则上,只需要展示一个遵循X但不遵循Y的幺半群即可。
在很大一部分情况下,他们可以简单地搜索小型有限幺半群——比如两个、三个或四个元素的幺半群——来获得这种反蕴含关系。
但这些并不足够,事实上,他们只知道有些反蕴含关系,只能通过构造无限幺半群来证明。
比如,现在已知的Asterix law不蕴含Obelix law,但所有反例必然是无限的。
有趣的是,已知的构造方法与集合论中著名的forcing技术有一些相似之处,即不断向(部分)幺半群添加「通用」元素,以forcing存在具有某些特定属性的反例。
不过,这里的构造肯定比集合论构造简单得多。
他们还从「线性」幺半群x ◇ y = ax + by构造中取得了有益的进展。这些构造存在于交换环和非交换环中。
与「汇聚」(confluent)方程定理相关的自由幺半群,以及更普遍的具有完整重写系统的定理。
因此,未解决的蕴含关系数量继续稳步减少。
经过相当繁忙的后端设置和「灭火」(putting out fires)工作后,项目现在运行得相当顺利。
项目在Lean Zulip频道上协调,所有贡献都通过GitHub上的拉取请求(pull request)过程进行,并通过基于问题的GitHub项目进行跟踪。
另外两位维护者Pietro Monticone、Shreyas Srinivas为其提供了宝贵的监督。
与之前的PFR形式化项目相比,这次项目的工作流程遵循了标准的GitHub实践,大致如下:

如果在Zulip讨论过程中,明确需要完成某些特定任务以推进项目(比如,在Lean中形式化讨论线程中已经推导出的蕴含关系证明),就会创建一个「问题」(通常由陶哲轩自己或其他维护者创建),其他贡献者可以「认领」这个问题,单独工作(使用主GitHub仓库的本地副本)。
然后提交「拉取请求」将他们的贡献合并回主仓库。这个请求随后可以由维护者和其他贡献者审查,如果获得批准,就会关闭相关问题。
更广泛地说,他们正努力记录这个设置中的所有过程和经验教训。
这将成为即将发表的关于这个项目的论文的一部分,现正处于初步规划阶段,可能会包括数十位作者。
陶哲轩表示,自己对项目取得的进展非常满意,而且许多最初的期望已经实现。
在科学方面,他们发现了一些新的技术和构造,用来证明一个给定的方程理论不蕴含另一个;他们还发现了一些具有有趣特征的奇特代数结构,如Asterix和Obelix对,是通过系统性搜索方式被发现的。
参与者方面,非常多样化,从各个职业阶段的数学家、计算机科学家,到感兴趣的学生和业余爱好者。
此外,Lean平台在整合人工生成和机器生成的贡献方面表现良好。
机器生成在数量上是迄今为止最大的贡献来源,但许多自动生成往往是基于人类最初在特殊情况下发现的,然后由项目的不同成员进行推广和形式化。
在讨论线程中,他们还进行了许多非正式的数学论证,但这些论证往往会迅速在Lean中形式化,消除了关于正确性的争议就。
进而,研究人员可以转而专注于如何最好地部署各种经过验证的技术,来解决剩余的蕴含关系。
原本,陶哲轩期待看到现代AI工具,能够在项目中做出重大贡献。
但实际上,它们以一种辅助、次要的方式被使用。
比如,通过GitHub Copilot等工具来加速编写Lean证明、LaTeX文档框架、其他软件代码。
此外,他们的几个可视化工具,也主要是使用Claude等大模型共同编写的。

然而,对于解决蕴含关系这一核心任务,更「传统」的自动定理证明器表现更好。
不过,目前剩余的大约700个蕴含关系,大多数不适合使用传统工具来处理。
有几个蕴含关系(特别是涉及Asterix和Obelix那些),已经让人类专家困惑多日。
陶哲轩认为,在解决剩余的、更困难的蕴含关系时,现代AI可能会发挥更重要的作用。
文章来自于“新智元”,作者“桃子 好困”。




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
