# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
别信忽悠,信实测。
汽车业务失利后,苹果决定加码生成式AI,并将部分汽车部门的员工调到了AI部门。然而对待AI,苹果似乎不如百度、讯飞、OpenAI、xAI等国内外企业那么自信。
日前,苹果研究员发布了一篇名为《理解大语言模型中数学推理局限性 》的论文,质疑大语言模型的数学推理能力,甚至认为大语言模型不具备真正的推理能力。
苹果研究员在论文中举了一个简单的例子,向大模型提出问题“奥利弗周五摘了44个奇异果,周六摘了58个奇异果。周日,他摘的奇异果是周五的两倍。奥利弗一共摘了多少个奇异果?”此时大语言模型都能正确计算出答案。

(图源:豆包AI生成)
但当研究人员为问题增添了一句修饰语“周日,他摘的奇异果是周五的两倍,其中5个比平均小”时,部分大模型就给出了错误的答案,倾向于减掉这五个比较小的奇异果。
在大语言模型的使用过程中,小雷也遇到过大模型“抽风”的情况,某个大语言模型甚至连最基础的乘法都能算错。不过大语言模型一直在向前发展,许多曾经常犯的错误,都已被新技术解决。
苹果研究员吐槽大语言模型数学推理能力不行,究竟是情况属实,还是为自家AI技术落后找借口?实测过后,我们有了结论。
本次大语言模型对比评测,小雷选择了全球名气较高的六款产品,包括:1、GPT-4o;2、讯飞星火大模型;3、豆包;4、Kimi;5、文心3.5五款大模型;6、GPT-4o mini。由于文心大模型4.0收费,其他大语言模型则免费(GPT-4o每日有免费提问次数),因此为了公平起见,小雷选择了免费的文心大模型3.5。
闲话不多说,我们直接进入测试阶段。
第一轮测试的问题,我们选择了苹果研究员提到的奇异果问题(正确答案:190个)。站在人类的视角,奇异果的大小并不影响计算数量,但在大语言模型的视角中,情况却发生了变化。
本轮测试中,五款大语言模型有四款通过了考验,其中豆包和Kimi特地提醒,奇异果的大小并不影响计算总数。GPT-4o虽然也正确计算出了总数,但可能是因为“平均”两个字的翻译问题,还求出了三天平均每天摘取奇异果的数量。唯一没有得出正确答案的大模型是文心大模型3.5,将五个体型小的奇异果排除,得到了摘取185个奇异果的错误答案。

(图源:GPT截图)
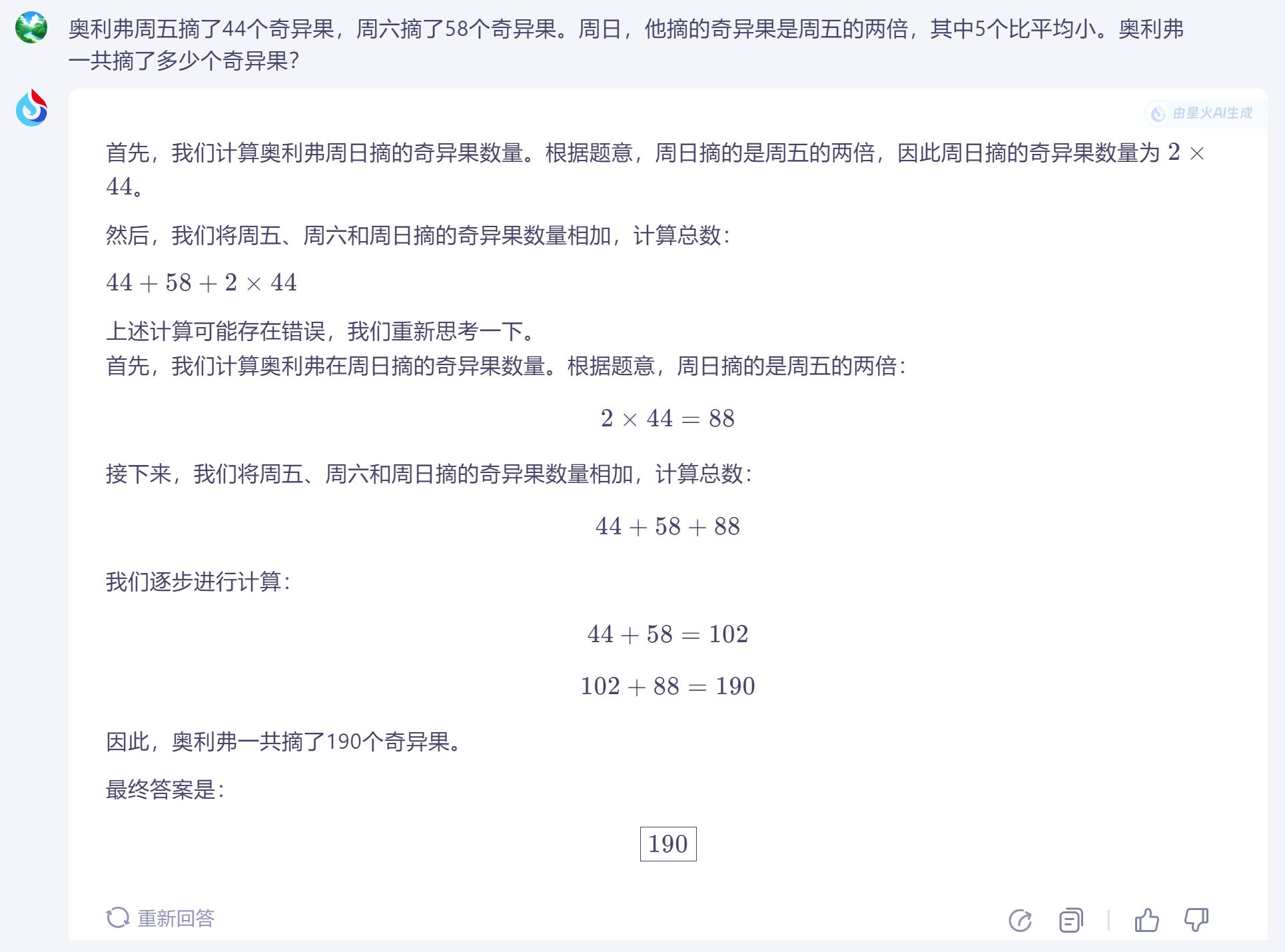
(图源:讯飞星火截图)

(图源:豆包截图)

(图源:Kimi截图)

苹果研究员的论文,提到了GPT-4o mini计算该问题时出错,切换至该模型后,小雷又计算了一遍这道题,果不其然,GPT-4o mini也给出了错误答案。(图源:文心一言截图)

(图源:GPT-4o mini截图)
难道大语言模型计算数学题的准确性,与其参数量呈正相关?GPT-4o mini属于小模型,更追求低成本和快速响应,参数量远不能与GPT-4o相比,在推理数学问题时,参数量的差距导致GPT-4o与GPT-4o mini计算结果不同。
文心大模型同样如此,尽管没有官方数据,但4.0版本的推理成本相较于3.5版本预计提高了8-10倍,3.5版的参数量之小可想而知。
本轮测试的题目是一道行测数学题,具体内容为:
由于国庆节的到来,某旅游城市的游客数量大幅上涨,公交公司决定简化公交车的线路,缩短单程时间。现有1、2、3路公交车,于上午7点同时从车站发车,三辆公交车再次回到车站所用时间分别为30分钟、45分钟、60分钟。这三辆公交车中间不休息,请问第二次它们同时到达车站将是几点?(正确答案:13点)
这轮测试所得出的结果,让小雷惊掉了下巴。在测试中,小雷连续测试四款大模型,结果全部计算错误,当时唯一没有出错的大语言模型就是文心3.5。
鉴于文心3.5在第一轮的表现,小雷没有对文心3.5抱有任何期待,但我不看好它的时候,文心3.5偏偏就争气了,并成为唯一解出正确答案的大语言模型。后续小模型GPT-4o mini在测试中,也没能给出正确答案。

(图源:GPT截图)

(图源:讯飞星火截图)

(图源:豆包截图)

(图源:Kimi截图)

(图源:文心一言截图)

(图源:GPT-4o mini截图)
思来想去,小雷认为唯一的解释就是,百度作为国内首屈一指的搜索引擎,对于中国人的语言与思维习惯更加了解,因而才能准确理解“到达”这个词的含义。其他大模型都将始发停靠在汽车站当做第一次到达车站,未能正确理解“到达”的含义。
相较于数学,本题对于中文理解能力的考验可能更高,但这几款大语言模型的表现也从侧面说明,AI大模型对于人类逻辑的理解能力有待提升。考虑到文心3.5的获胜证明实力的同时,也有取巧的可能,因此小通还准备了地狱级难度的第三轮测试。
第三道题同样是一道行测数学题,但与以上问题不同的是,这道题没有任何干扰信息,纯粹考验大语言模型的计算能力。题目为:
某班有39名同学参加短跑、跳远、投掷三项体育比赛,人数分别为23人、18人、21人,其中三项比赛全部参加的有5人,仅参加跳远的有3人,仅参加投掷的有9人,请问仅参加短跑的有多少人?(正确答案:9人)
遗憾的是,五款大模型与一款小模型在本轮测试中全部失败,而且大语言模型给出的答案各不相同,解题思路也存在许多问题。

(图源:GPT截图)

(图源:讯飞星火截图)

(图源:豆包截图)

(图源:Kimi截图)

(图源:文心一言截图)

(图源:GPT-4o mini截图)
最后,小雷只好使用付费版的OpenAI o1-preview大模型进行计算,结果不负众望,给出了正确答案。

(图源:GPT-4o o1-preview截图)
同样是OpenAI旗下的大模型,免费版GPT-4o和付费版o1-preview得出了不同答案,原因可能在于免费用户所能调用的资源更少,导致大模型计算能力不如付费版。
以上参与三轮测试的五款大模型和一款小模型中,表现最差的无疑是小模型GPT-4o mini,三轮测试中均给出了错误答案。
我们可以得出以下结论:
GPT-4o mini的表现证明,当需要处理难度较高的推理问题时,小模型参数量少、资源少更容易出错。尽管百度、OpenAI、谷歌、微软等企业都致力于研究小模型,但它们可能只是日常使用时回答基础问题“勉强能用”的平替版,毕竟成本可以大幅降低,这就跟企业雇佣一个小学生和一个博士生一样,智力是一分钱一分货。
据研究机构Epoch AI计算,训练尖端大模型所需的算力,每隔6-10个月就会翻一倍。庞大的算力需求,给AI公司带来了极高的经济压力,哪怕是谷歌、微软这种行业巨头,也会倍感吃力。正因如此,小模型现阶段虽表现逊色于大模型,但AI公司不会放弃开发小模型,而是会通过长时间的调校与打磨,不断提升小模型的能力。

(图源:豆包AI生成)
几款大模型的免费版表现相差不大,能够解决一些存在干扰条件的数学问题,但遇到了文字可能存在歧义,或过于复杂的数学问题,表现则相对较差。好在,面对雷科技设定的地狱级难题,付费版的o1-preview大模型最终给出了正确答案,为大语言模型挽回了颜面,唯有付费用户才能体验到最好的大模型。
结合文心3.5能够在第二项测试中力压群雄可知,大语言模型依赖大量数据运算,但每个国家或地区的数据量和获取难易程度不同,因语言和生活习惯的差异,综合表现更出色的大模型,未必能在特定场景中获胜,大语言模型也需要本地化适配。
在资本驱动下,很多媒体、自媒体、创业公司甚至企业家大佬都在鼓吹“AI威胁论”,甚至豪言AI水平已超越人类,他们往往会用一些个案来证明AI大模型已具备博士生甚至超越博士生水平。然而,当我们找一些常见的数学题,抑或是一些常见的工作任务来“考考”大模型时,大模型也很容易被难住。
大模型以及AI当然会有许多安全威胁,比如自动驾驶汽车失控给城市交通乃至人类生命安全带来的威胁。但要说AI智力可以逼近人类甚至取代人类,那就纯属忽悠了。
综合来看,苹果研究员的观点对错参半,当前AI的逻辑推理能力不足,面对复杂的数学问题时,显得有些力不从心,但AI并非完全没有逻辑推理能力。哪怕是相对而言版本较为落后的文心3.5,在第二轮测试中也展现出了对文字和数学的解读与推理能力。
第一代GPT发布于2018年,仅有1.17亿参数,到了2020年,GPT-3已拥有1750亿参数,到如今GPT的历史不过短短6年,每一代的体验提升肉眼可见。
当前大语言模型最大的问题依然在于参数量太少、算力太低,资源相对丰富的o1-preview,面对其他大模型束手无策的数学难题时,依然给出了正确答案。随着大模型不断优化、参数量增加、算力提升,大语言模型的推理能力自然会水涨船高。
进军新能源汽车时,苹果血亏百亿美元最终放弃,如今进入生成式AI领域,苹果研究员又站出来贬低大语言模型,不禁令人怀疑苹果的生成式AI项目进展不顺利。对于苹果而言,与其贬低其他AI大模型,不如增加AI研发投入,加速布局生成式AI,毕竟AI的烧钱能力更甚于新能源汽车。
若失去了研发和布局生成式AI最好的机会,等到OpenAI、谷歌、微软、xAI等企业的AI大模型瓜分了海外市场,百度、讯飞、阿里巴巴、抖音等企业的AI大模型占领了国内市场,苹果生成式AI业务有可能沦为与新能源汽车业务相同的结局。
文章来自于“雷科技”,作者“雷科技”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
