# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本论文作者主要包括德国计算机科学家、LSTM 之父 Jürgen Schmidhuber;Meta AI 研究团队(FAIR)研究科学家总监田渊栋,他负责领导大语言模型(LLMs)在推理、规划和决策方面的研究团队,主导了 OpenGo、StreamingLLM 和 GaLore 项目,专注于提升大模型的训练和推理效率;Vikas Chandra,Meta Reality Lab AI 负责人;诸葛鸣晨,Meta 研究科学家实习生,同时在沙特阿卜杜拉国王科技大学(KAUST)攻读博士三年级,师从Jürgen Schmidhuber,GPTSwarm 第一作者,MetaGPT 共同第一作者;Zechun Li,Meta Reality Lab 研究科学家,MobileLLM 的第一作者;Yunyang Xiong,Meta Reality Lab 高级研究科学家,EfficientSAM 第一作者。
如果说去年大厂的竞争焦点是 LLM,那么今年,各大科技公司纷纷推出了各自的智能体应用。
微软发布了 Copilot,Apple 将 Apple Intelligence 接入了 OpenAI 以增强 Siri。多智能体也是 OpenAI 未来重要的研究方向之一,这家公司的最新成果 ——Swarm,一个实验性质的多智能体编排框架在开源后引起了热烈讨论,有网友表示这能帮助简化许多潜在多智能体用例的工作流程。
扎克伯格更是断言:「AI 智能体的数量可能会达到数十亿,最终甚至超过人类。」在 Meta Connect 2024大会上,Meta 推出了接入 Llama 3.2 的智能眼镜 Orion 和升级版 Quest 3S,显示出智能体正在迅速渗透进 Meta 的各个应用领域。

近日,Meta 提出了 Agent-as-a-Judge 的概念,被视为智能体优化方面的又一重要成果。传统的智能体评估方式往往只关注最终结果,忽略了执行过程中的关键细节,或依赖大量人力进行评估。为了解决这一痛点,Meta 推出了用智能体评估智能体的新方法,使评估过程更加灵活且自动化。
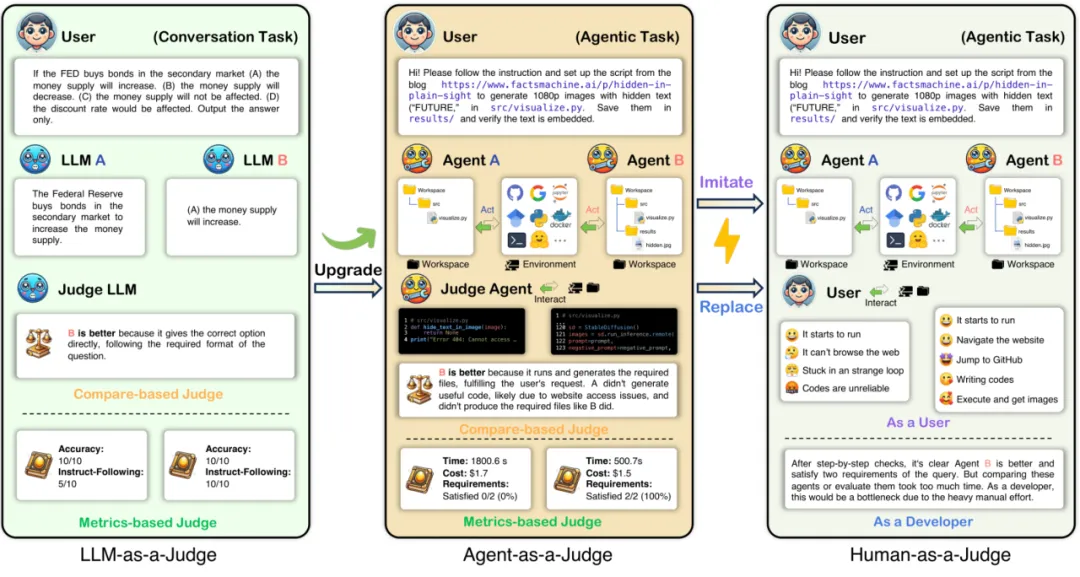
该框架在 LLM-as-a-Judge 的基础上进行了升级,增加了中间反馈功能,确保任务的每个环节都能得到精准评估与优化,同时还能有效模拟并接近人类反馈。

为了克服现有基准存在的问题,并为 Agent-as-a-Judge 提供一个概念验证测试平台,研究者还提出了 DevAI,一个包含 55 项现实自动人工智能开发任务的新基准。它包括丰富的手动注释,如总共 365 个分层用户需求。

Agent-as-a-Judge 框架最大的亮点在于其与人类评估者的高度一致性。在实验中,该框架的评估结果与人类专家的对齐率高达 90.44%,远超 LLM-as-a-Judge 的 70.76%。这一结果表明,智能体在处理复杂任务时,能够像人类一样精确地判断并修复问题,极大地减少了对人工评估的依赖,同时显著提高了效率。
显著的效率提升。实验表明,Agent-as-a-Judge 在效率上也具有明显优势。与人类评估者耗费 86.5 小时相比,Agent-as-a-Judge 仅需 118.43 分钟就能完成相同任务,大幅节省了时间和成本。评估 55 个任务的总成本仅为 30.58 美元,平均每个任务的评估费用仅为 0.55 美元,显示了极高的性价比和工作效率。
填补评估中的反馈空白。当前,智能体评估方法普遍缺乏中间反馈机制,只关注最终结果,忽视了任务执行中的关键步骤。智能体在解决复杂问题时,通常像人类一样,逐步思考并解决问题。因此,评估不仅应该关注结果,还需考察每个步骤的思维过程和行为轨迹。Agent-as-a-Judge 通过提供中间反馈,填补了这一空白,标志着智能体评估进入了一个新的阶段。
数据集挑战与系统表现。实验还揭示,即使是表现较好的智能体系统(如 GPT-Pilot 和 OpenHands)也仅能满足 DevAI 数据集中约 29% 的任务需求,任务完成率有限,凸显了该数据集的挑战性。在与人类专家评估的对比中,Agent-as-a-Judge 表现出色,达到了 90% 的对齐率,而 LLM-as-a-Judge 仅为 70%。更值得注意的是,Agent-as-a-Judge 的表现甚至优于单个专家评估者,意味着在某些情况下,该框架不仅能够替代人类评估,还可能更加有效。
高性价比与潜力。通过节省 97.72% 的时间和 97.64% 的成本,Agent-as-a-Judge 展示了其在 AI 评估中的巨大潜力。它为智能体技术的发展提供了强有力的支持,标志着 AI 评估工具迈向了更高效和低成本的新纪元。
行业趋势与 Cognition AI。值得注意的是,近期获得融资的 Cognition AI 也采取了类似思路,即使用智能体来评估智能体,这显示出这一概念正在成为业界的一个重要趋势(更多信息请参见:https://www.cognition.ai/blog/evaluating-coding-agents)。

综上,Agent-as-a-Judge 的提出有如下价值:
(1)智能体自我改进的中间反馈机制
Agent-as-a-Judge 的一个核心优势在于其提供的中间反馈,这对于实现智能体的高效优化至关重要。尽管在本研究中这一潜力尚未被充分发掘,但它的作用已经初见端倪。通过学习辅助奖励函数,能够解决强化学习中的稀疏奖励问题,提供关键的中间反馈。Agent-as-a-Judge 框架的亮点在于,它使智能体在处理复杂、多阶段问题时,能够实时发现并修复解决方案中的问题,而传统的延迟反馈机制难以做到这一点。引入 Agent-as-a-Judge 后,为构建智能体版本的过程监督奖励模型(PRM)打开了大门,从而进一步提升智能体的优化效率。
(2)由 Agent-as-a-Judge 驱动的飞轮效应
Agent-as-a-Judge 和被评估智能体之间的相互改进,通过不断的迭代反馈逐步演进,这一循环展示了广阔的发展前景。通过将 Agent-as-a-Judge 作为核心机制,或许能够催生出一种智能体自我博弈系统。随着 Agent-as-a-Judge 与被评估智能体的持续交互,这种过程可能会产生飞轮效应 —— 每次改进相互强化,从而不断推动性能的提升。这种迭代不仅能增强智能体系统的能力,还可能成为 LLM 推理数据的重要补充,有助于将智能体的能力更好地嵌入基础模型中,进一步拓展智能体系统的潜力。
DevAI:从用户角度出发的 AI 自动化数据集
过去一年中,LLM 智能体系统的能力显著提升,从解决简单的「玩具问题」逐步扩展到处理复杂的实际任务。然而,大多数现有的评估方法和数据集仍然基于为基础模型设计的标准,难以全面反映智能体在现实任务中的表现和挑战。以 HumanEval 和 MBPP 等数据集为例,尽管它们在评估基础模型的算法能力方面有效,但在代码生成等领域,现有方法过于依赖最终结果,无法捕捉开发者在现实任务中遇到的复杂性和动态过程。
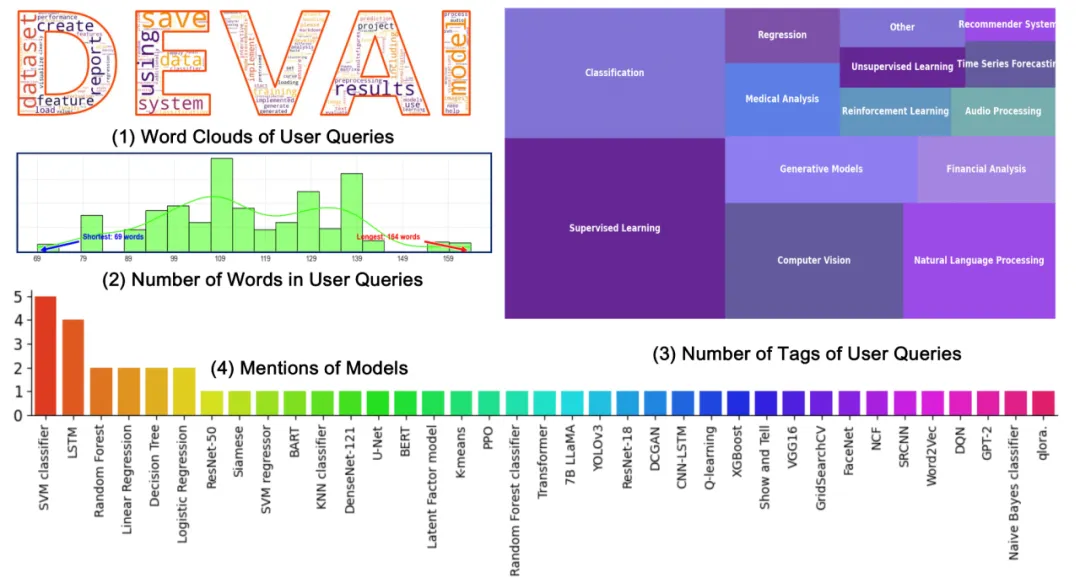
尽管 SWE-Bench 尝试引入更接近现实的评估标准,但它依然主要依赖「解决率」(resolve rate),这一指标未能提供开发过程中每个阶段的具体反馈,也难以捕捉智能体系统的动态表现。因此,这类评估标准无法准确反映智能体在实际任务中的真实能力。

相关研究甚至表明,即使不具备智能体特性,模型也能达到 27% 的解决率。此外,激烈的竞争还引发了对 SWE-Bench 得分真实性的担忧,许多高分可能通过对独立任务的过拟合获得,无法真实反映智能体的实际能力。
鉴于此,迫切需要新的评估方法来弥补这些不足。为此,Meta 推出了专门为智能体系统设计的 DevAI 数据集。DevAI 涵盖了 55 个 AI 开发任务,涉及监督学习、强化学习、计算机视觉和自然语言处理等领域。每个任务包含用户查询、365 个任务需求和 125 个偏好标准。
与传统评估方法不同,DevAI 不仅关注任务的最终结果,还跟踪并评估任务执行过程中的每个阶段,从而提供更全面的反馈(图 4 所示)。虽然这些任务规模相对较小,但它们真实反映了开发中的实际问题,且计算成本较低,适合广泛应用。值得注意的是,DevAI 不关注「玩具」数据集(如 FashionMNIST)上的高分表现,而更注重智能体在处理现实任务中的能力。此外,DevAI 采用有向无环图(DAG)结构排列任务需求,确保评估具备层次性,不再依赖简单的成功或失败判断,而是要求智能体具备更深入的解决问题能力。未来,代码生成领域的标准评估方法可能会采用类似 DevAI 这样的数据集,提供中间反馈,以模块化提升智能体的能力;在能力提升后,使用 OpenAI 的 MLE-Bench 进一步评估智能体解决复杂问题的能力。
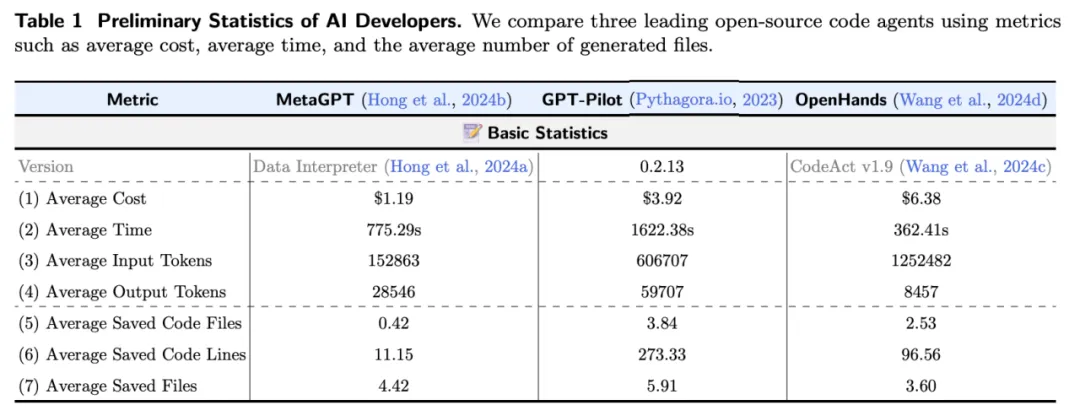
在完成基线执行结果和基本统计分析后,研究团队邀请了三位具备 5 年以上 AI 开发经验人类专家评估员(匿名为 231a、38bb 和 cn90)对 AI 开发者的基线输出进行审查,评估每项需求是否得到了满足。评估分为两轮。为了尽量捕捉人类评估中常见的偏差(模拟实际部署场景),在第一轮中,评估员讨论了基本标准。虽然允许评估员带有个人偏好,但评估过程需基于统一的标准进行。在第一轮评估完成后(总计约 58 小时),评估员再次进行讨论,进一步修正和达成一致意见,确保评估结果更加统一和一致。这一过程共耗时 28.5 小时,最终的共识作为每种方法的最终人类评估结果。
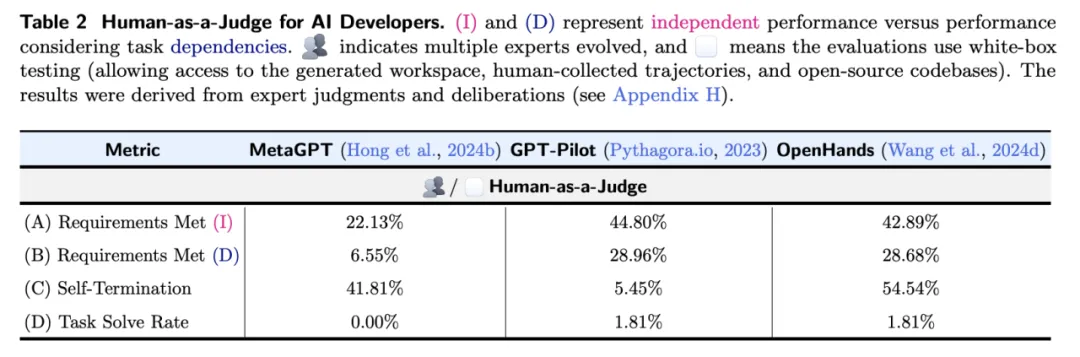
性能分析。实验结果显示(如表 2),表现最好的两种方法 ——GPT-Pilot 和 OpenHands—— 仅能满足约 29% 的需求(忽略前提条件后为 44%),且仅在一个任务中满足了所有要求。这表明 DevAI 为当前及未来的智能体方法设定了较高的挑战性。此外,正如第 2 节所讨论的,DevAI 不仅揭示了任务最终结果,还通过反馈揭示了智能体在任务过程中出现的问题,为评估提供了更丰富的层次。
错误分析。在实验中,评估员在初步评估后进行了深入辩论,直到他们对每个任务的需求达成一致意见。共识评估(consensus)通过这种方式模拟实际情况,减少了个体评估中的偏差。在 Human-as-a-Judge 框架下,评估员可以通过讨论和证据修正自己的判断,从而调整评估结果。这种方式也用来近似估计个体的错误率。理论上,集体讨论达成的共识应比任何个体评估更接近真实结果。
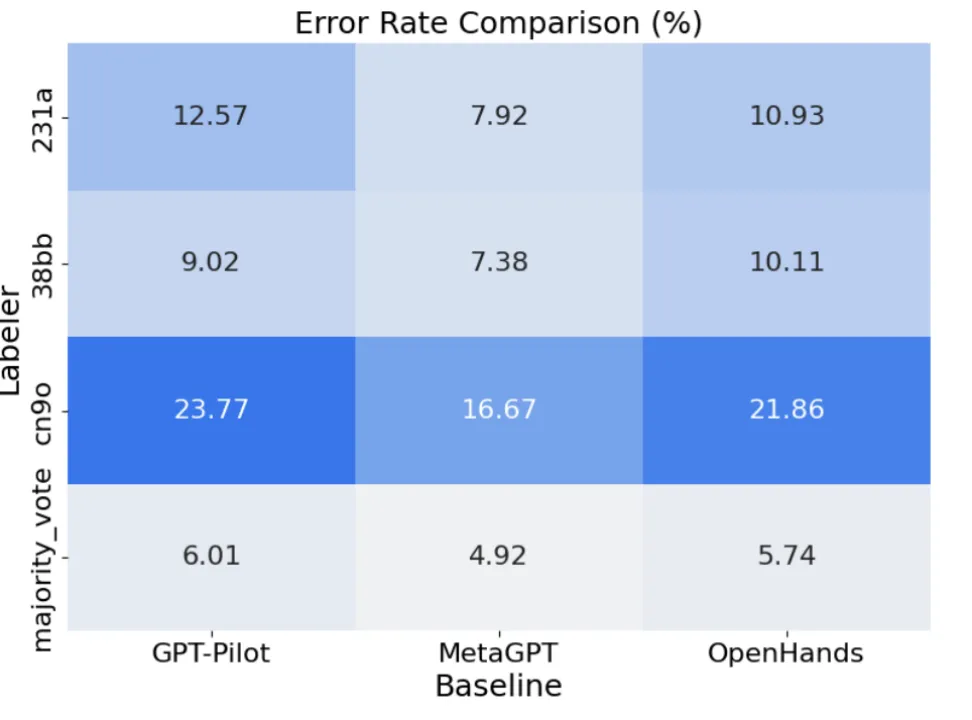
虽然共识评估可能并不完美(某些错误仍然存在),但相较于个体评估,理论上共识评估应更接近真实结果。如图 5 所示,实验结果证实了这一假设。尽管评估员之间的错误率有所不同,但多数投票有效地修正了大部分错误。例如,评估员 cn90 在评估 GPT-Pilot 时犯下了最多的错误(错误率达 23.77%)。然而,通过多数投票(majority vote),三位评估员的整体错误率降低至 6.01%,显示了多数投票在减少评估偏差方面的优势。
结论。人类评估中的错误是不可避免的。为减少这些错误,研究提出了两种策略。第一,像本研究一样,在每次评估后引入讨论环节,评估员可以根据新的证据调整他们的判断。这一方法在评估员数量较少时尤其有效,因为小组评估中的多数投票仍可能产生一定误差(如图 5 所示,相比共识评估大约有 5% 的错误率)。第二,组建更大的专家团队来提高评估的准确性。研究表明,当评估员人数超过 5 人时,评估准确性有望超过 50%。然而,由于动员更多专家的成本较高,实践中这种方法并不总是可行。因此,本研究更倾向于通过讨论和共识投票来减少评估中的偏差。
目前,作者已在 GitHub 上提供了开源代码,支持对任意工作区(workspace)进行提问,并通过 Agent-as-a-Judge 功能在 DevAI 数据集上进行自动评估。未来的开源智能体评估将进一步改进,首先利用 DevAI 对中间过程进行判断和优化,最终通过类似 MLE-Bench 的工具测试智能体的整体性能。

文章来自于微信公众号 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
