# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
训练Transformer,用来解决132年的数学世纪难题!
如何判断一个动力系统(如三体问题)是否稳定?Meta和巴黎理工学院团队携手提出Symbolic Transformer,直指这一经典难题的核心:
发现新的全局李雅普诺夫函数。

从牛顿、拉格朗日到庞加莱,无数科学家倾力研究三体问题的长期稳定性,却始终无法给出一个通用的判定方法。
直到1892年,俄国数学家Aleksandr Lyapunov提出了以他名字命名的李雅普诺夫函数:
如果存在一个函数V,其在平衡点处有严格最小值,在无穷远处为无穷大,且梯度始终指向远离系统梯度的方向,则全局稳定性得到保证。
但遗憾的是,李雅普诺夫只证明了这个结论,并没有提供寻找这个函数的方法。

130多年过去了,科学界仍然不知道对于一般的系统该如何寻找李雅普诺夫函数,现有的算法只能求解非常小规模的多项式系统。
换句话说,李雅普诺夫函数的系统化构造方法,依然是一个悬而未决的数学难题。
现在,这一局面有望被AI打破。

研究团队把寻找李雅普诺夫函数构建成一种序列到序列翻译任务,问题和解决方案都表示为符号tokens序列,就能用上原本为机器翻译而生的Transformer模型了。
最终,在8张V100上训练100个GPU时左右的模型,取得了惊人的成绩:
相关论文已入选NeurIPS 2024,且刚刚在ArXiv公开。

作者Meta科学家François Charto表示,尽管Symbolic Transformer像其他AI模型一样还是一个黑盒系统,但它给出的李雅普诺夫函数是明确的符号表达式,完全可以经受数学证明的检验。
用Transformer解决数学难题,最大的困难是什么?
答案不难想到:缺少数据,特别是在这个场景中,需要动力系统与李雅普诺夫函数的配对数据。
为此,Meta和巴黎理工团队利用了正向和反向数据生成相结合的策略。
正向数据生成,也就是根据多项式系统生成对应的李雅普诺夫函数。
虽然没有通用方法,但如果一个李雅普诺夫函数能表示成多项式的平方和,就有现存工具可以计算。
最终方法分为三步:

不过这个方法有几个局限。
大多数对象是系统都不稳定,且计算平方和李雅普诺夫函数涉及复杂的搜索,系统规模的增长,对算力和内存需求会呈爆炸式增长,所以这种方法速度很慢且仅适用于小的多项式系统。
于是还需要配合反向数据生成方法,根据答案反向构造问题。
这种方法也存在几个局限,比如AI倾向于偷懒,从任务中学习更简单的子问题,因此也需要做出一些限制。
最终方法大致可以理解成,先随机生成一个满足特定条件的李雅普诺夫函数,再反向构造出与之匹配的动力系统。

最终团队生成了4个数据集:
最终试验发现,在不同数据集上训练的模型都取得了很好的准确性。
使用Beam Search方法在宽度50时能给低性能模型带来额外7%-10%的提升。

特别是在后向数据训练集中添加少量前向生成数据示例,带来显著的分布外测试性能提升。
将FBarr中的300个示例添加到BPoly中,就能把FBarr准确率从35%提高到89%。另外添加FLyap示例带来的改进较小。

与此前SOTA基线比较,在混合数据上训练的模型取得了最好的效果。
基于Transformer的模型也比SOSTOOL方法快得多。
当尝试求解具有2到5个方程的随机多项式系统时,SOSTOOL的Python版本平均需要 935.2 秒。
Transformer模型在贪婪解码时,一个系统的推理和验证平均需要2.6 秒,而Beam Search宽度为50时,平均需要13.9秒。

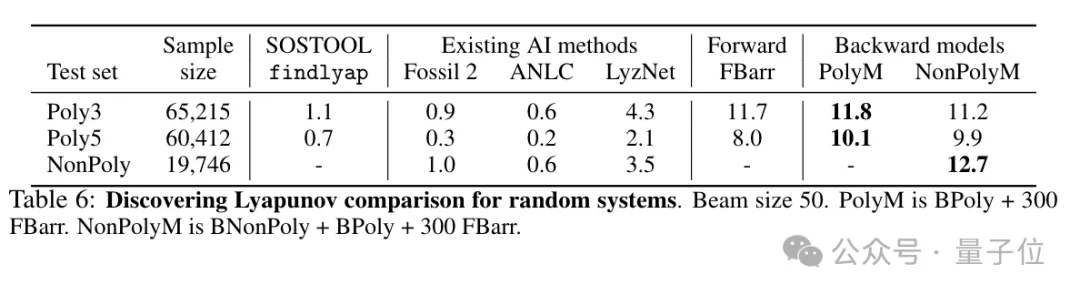
研究的最终目标是发现新的李雅普诺夫函数,在随机生成的2-3个多项式、2-5个多项式的数据集中,最佳模型发现了11.8%和10.1%的李雅普诺夫函数,是传统方法的10倍。
对于非多项式系统,模型发现了12.7%的李雅普诺夫函数。
这些结果表明,从合成数据集训练的语言模型确实可以发现未知的李雅普诺夫函数,并比此前最先进的传统算法求解器效果更好。
作者巴黎师范教授Amaury Hayat表示,几年前刚开始这个项目时,作为一个年轻而天真的数学家,他认为如果方法真的成功了,那简直可以算是黑魔法。
几年过去了,见识了AI的诸多成就,我对此已经理性得多了,但依然感觉……(不可思议)。

论文地址:
https://arxiv.org/abs/2410.08304
参考链接:
[1]https://x.com/f_charton/status/1846884416930402633
[2]https://x.com/Amaury_Hayat/status/1846889179780673853
文章来自于“量子位”,作者“梦晨”。




