# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
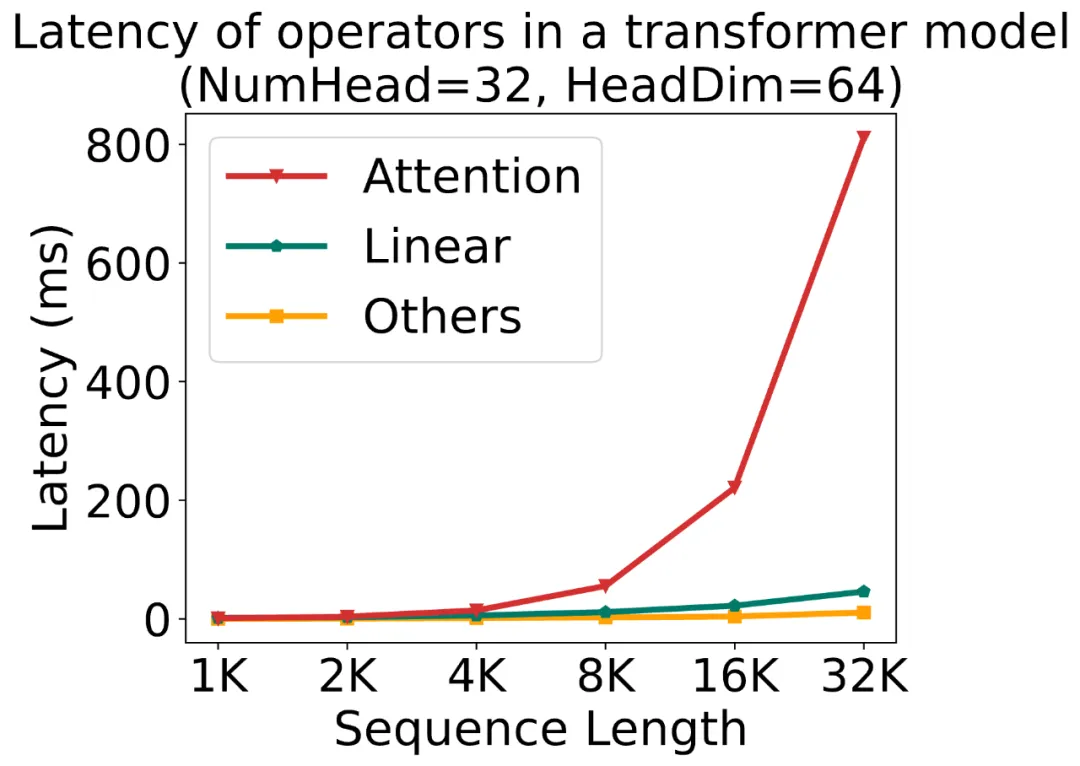
大模型中,线性层的低比特量化(例如 INT8, INT4)已经逐步落地;对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。然而,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为网络优化的主要瓶颈。
为了提高注意力运算的效率,清华大学陈键飞团队提出了 8Bit 的 Attention(SageAttention)。实现了 2 倍以及 2.7 倍相比于 FlashAttention2 和 xformers 的即插即用的推理加速,且在视频、图像、文本生成等大模型上均没有端到端的精度损失。

SageAttention 可以一行代码轻松替换掉 torch 中当前最优的 Attention 接口(scaled_dot_product_attention),实现即插即用的推理加速。

具体来说,SageAttention 的使用非常方便,使用 pip install sageattention 后,
只需要在模型的推理脚本前加入以下三行代码即可:

效果上,以开源视频生成模型 CogvideoX 为例,使用 SageAttention 可以端到端加速 35%,且生成的视频无损:

全精度 Attention

SageAttention
接下来,将从背景与挑战,技术方案,以及实验效果介绍 SageAttention。
随着大模型需要处理的序列长度越来越长(比如 Llama3.1 支持 128K 的序列长度),Attention 的速度优化变得越来越重要。下图展示了一个标准的 Transformer 模型中各运算随着序列长度变化的时间占比:
为了方便指代注意力元算中包含的矩阵,我们先回顾一下注意力的计算公式:
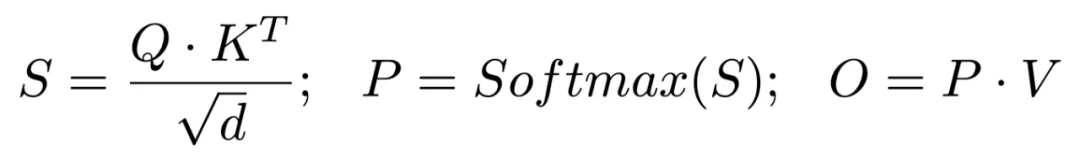
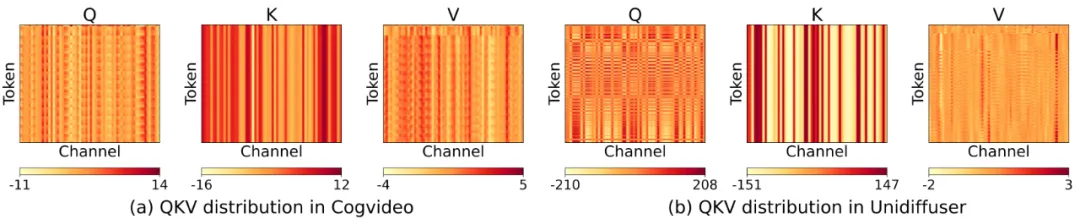
将神经网络中各运算的数值类型从高比特量化至低比特是一种有效提升计算和访存效率的方法。然而,研究团队发现直接将注意力运算中的 Q, K, P, V 从 FP16 量化为 INT8 或者 FP8 后将会导致在几乎所有模型和任务上都会得到极差的结果,例如,在 Unidiffuser 文生图模型中,会得到一张完全模糊的图像;在 Llama2-7B 进行四选一选择题任务上得到 25.5% 的准确率。

经过仔细分析后,研究团队发现主要是两个原因导致了量化注意力的不准确:
为了解决上述的两个关键问题,研究团队提出了对应的解决办法。

SageAttention 的流程图及算法如下所示:
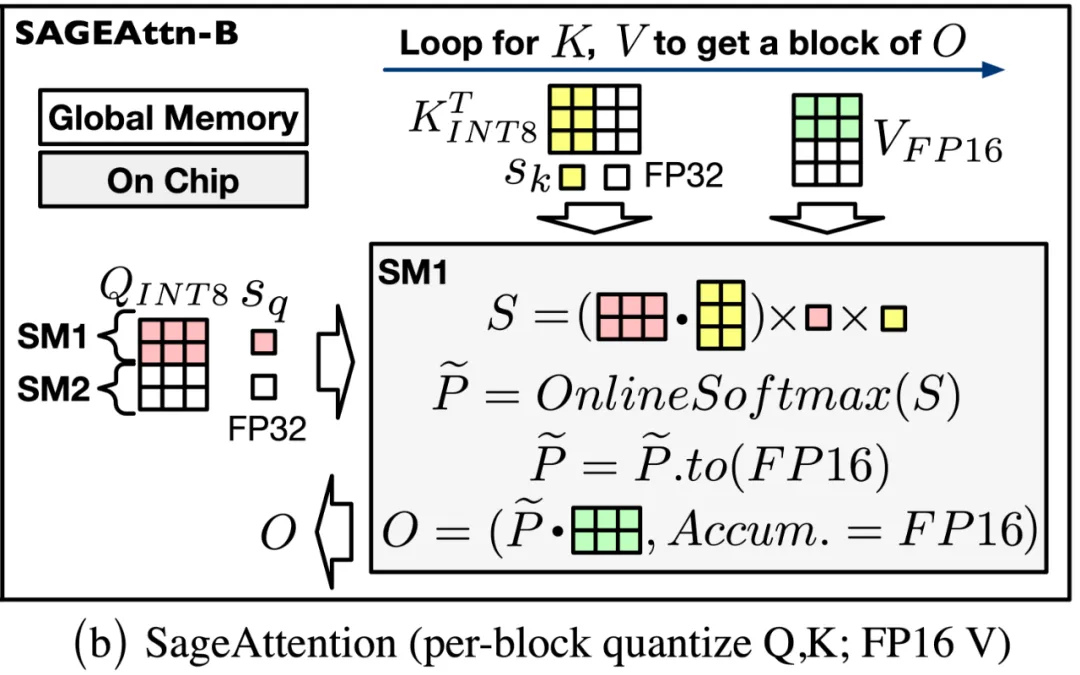

SageAttention 实现了底层的 GPU Kernel,在算子速度以及各个模型的端到端精度上都有十分不错的表现。
具体来说,算子速度相比于 FlashAttention2 和 xformers 有 2.1 以及 2.7 倍的加速。以下 4 张图展示了在 RTX4090 上,不同的序列长度下 SageAttention 的各种 Kernel 与其他方法的速度比较。
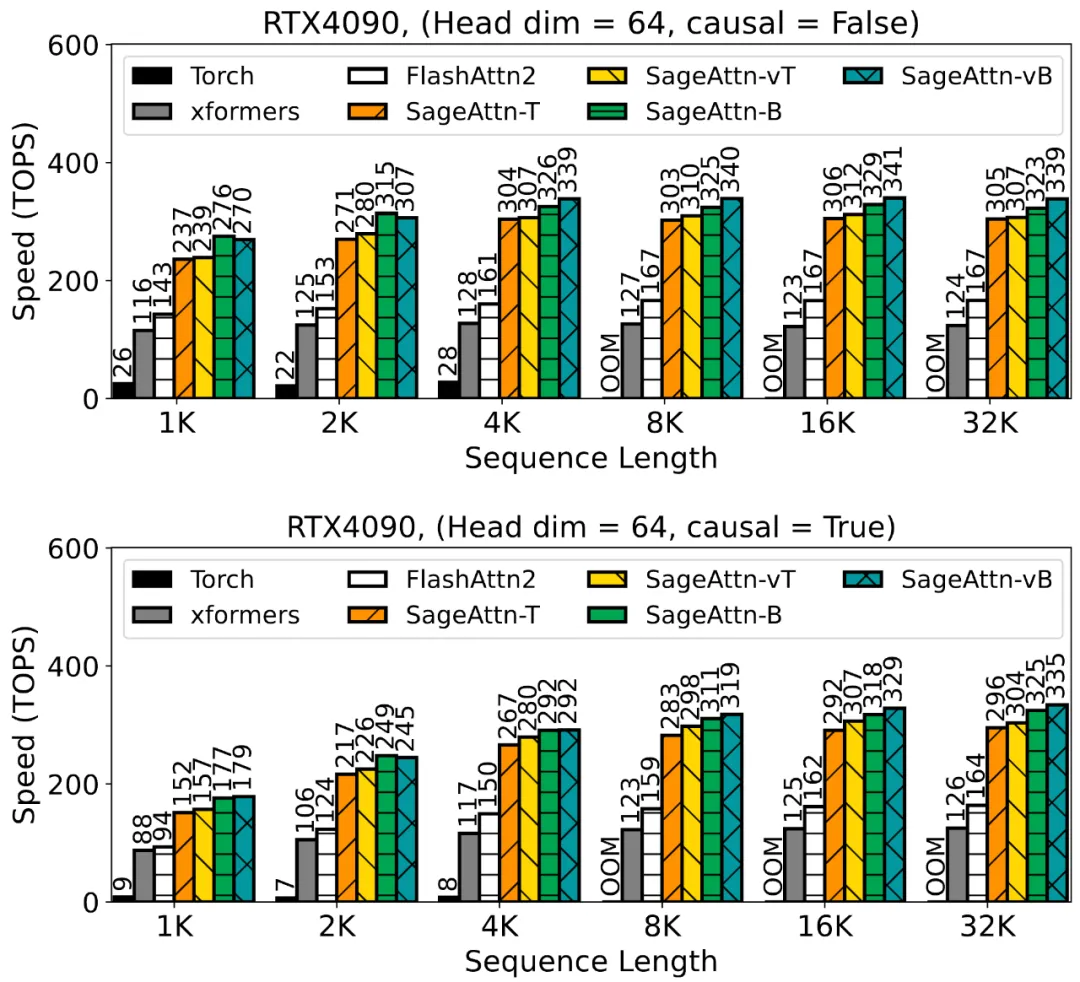
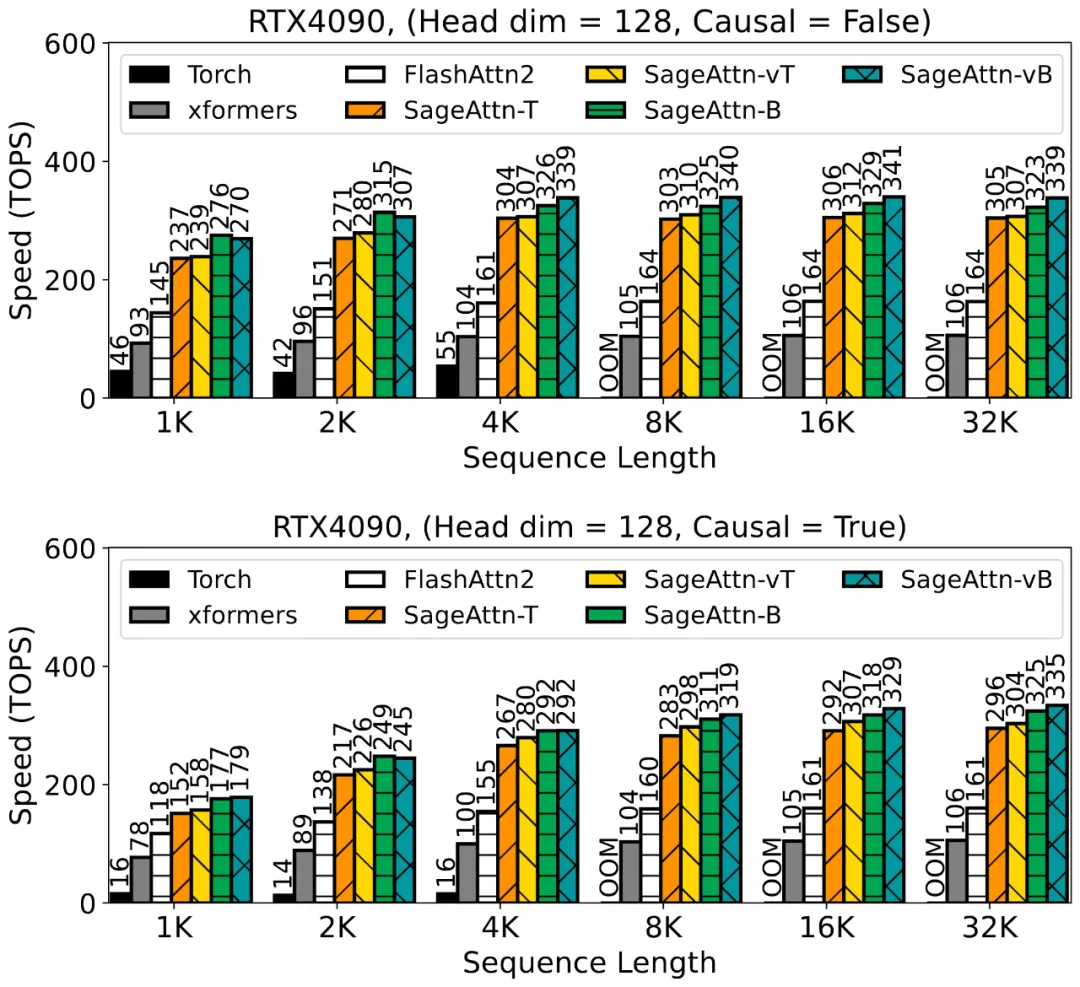
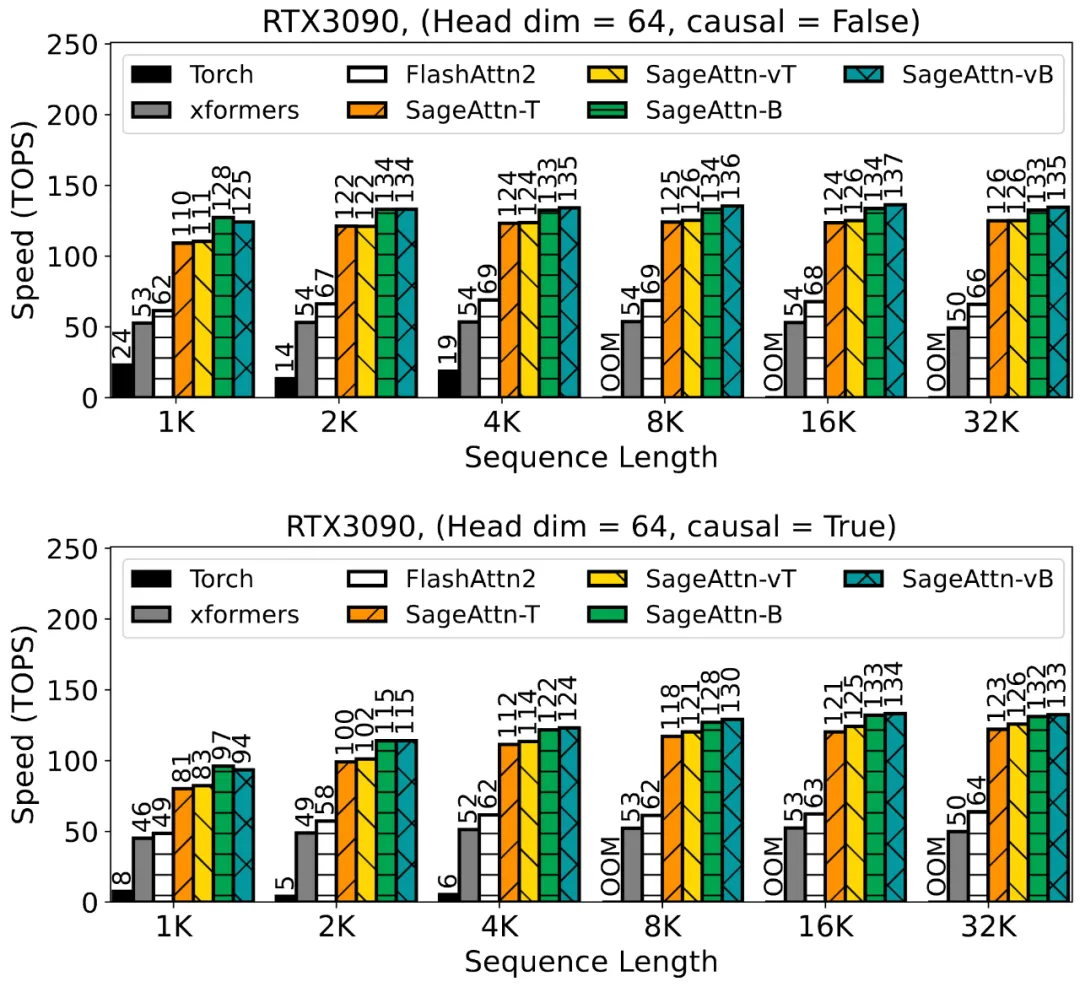
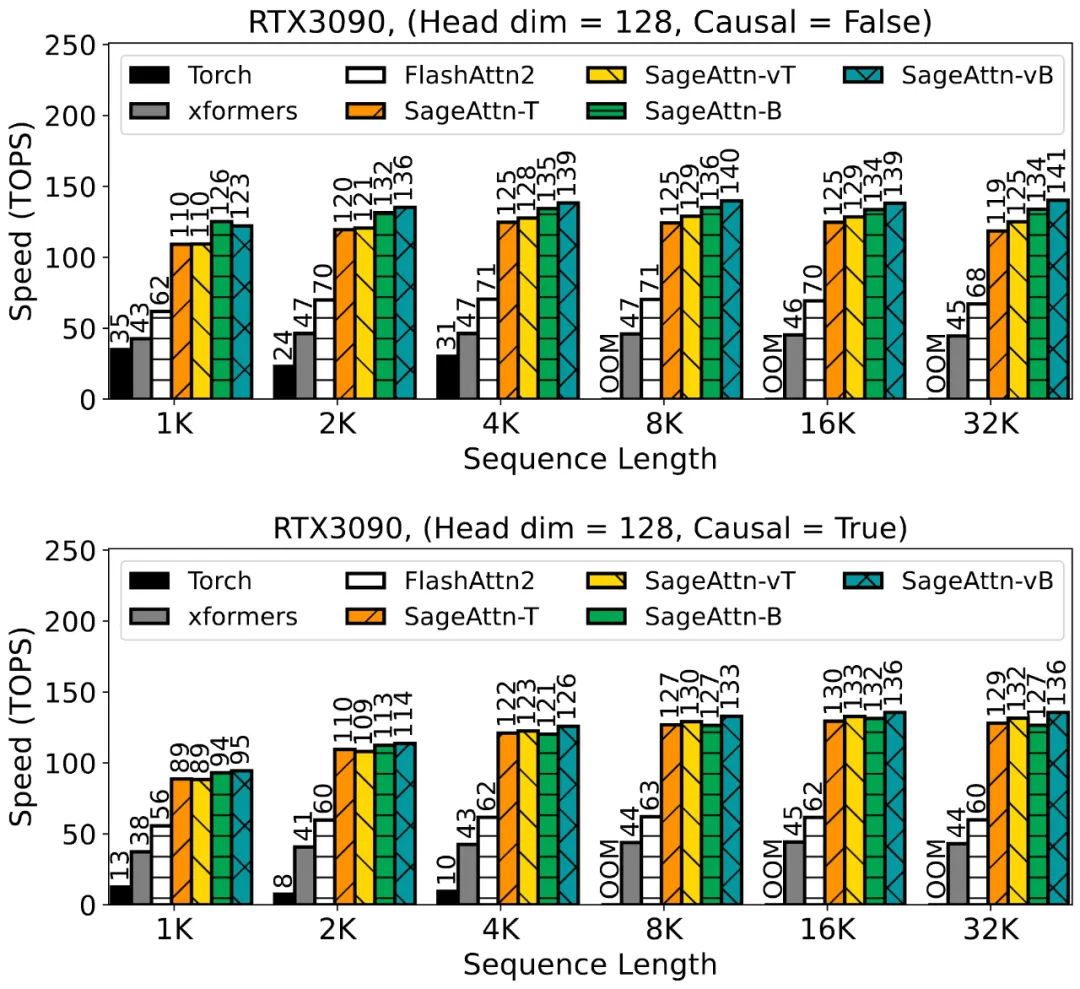
以下 4 张图展示了在 RTX3090 上,不同的序列长度下 SageAttention 的各种 Kernel 与其他方法的速度比较。
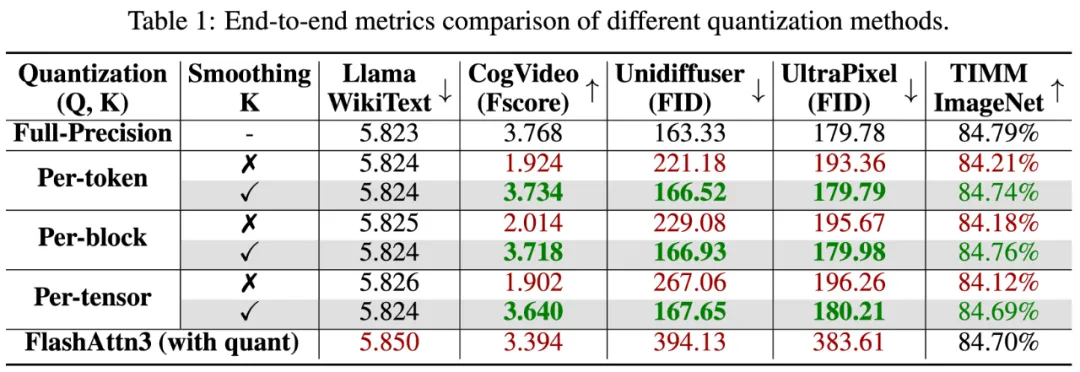
下表展示了在 RTX4090 上,各模型中的注意力模块中 SageAttention 相比于使用模型原始的注意力的加速比。

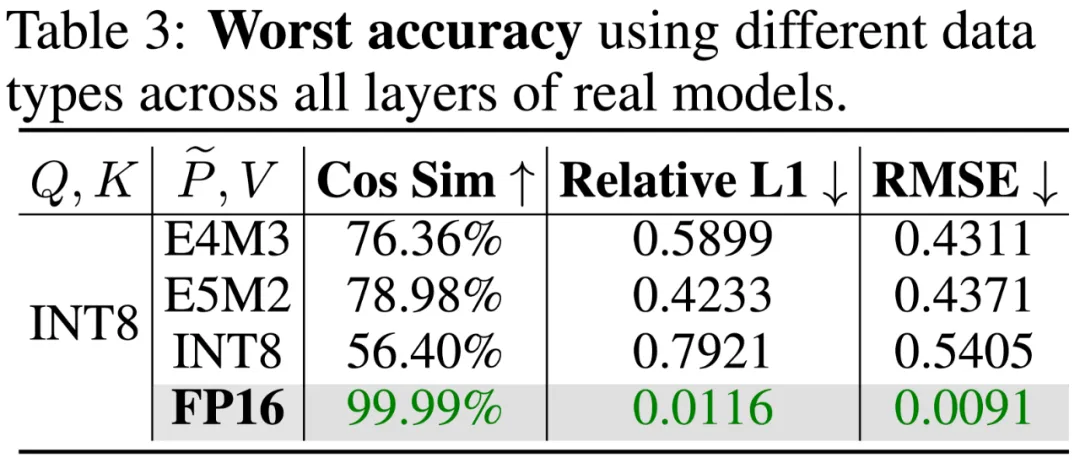
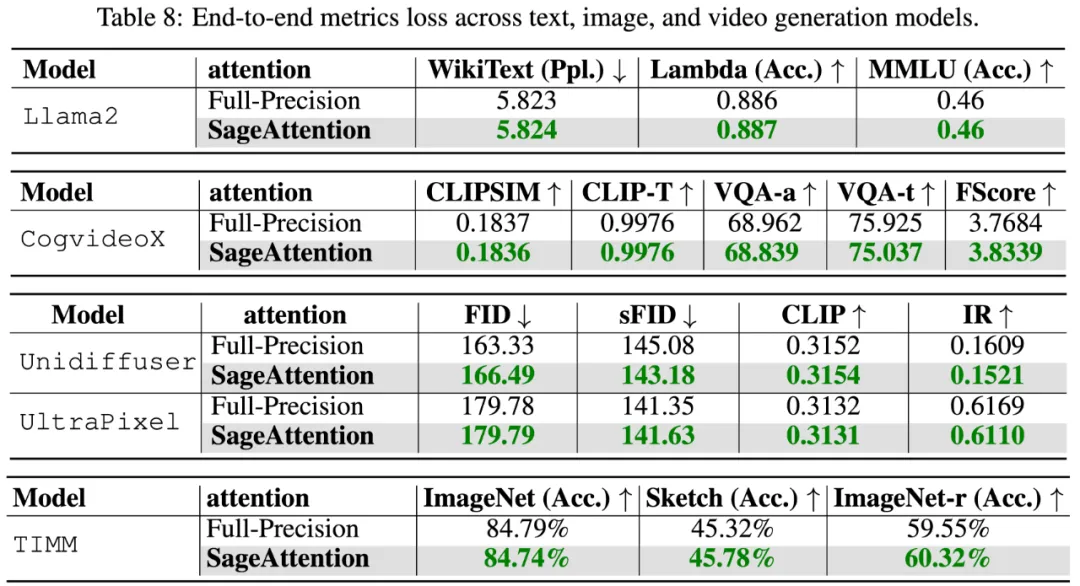
真实任务的精度上,下表展示了 SageAttention 在视频、图像、文本生成等大模型上均没有端到端的精度损失:
文章来自于“机器之心”,作者“张金涛、陈键飞”。




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
