# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态生成新突破,字节&华师团队打造TextHarmony,在单一模型架构中实现模态生成的统一,并入选NeurIPS 2024。
过去,视觉文字领域的大模型研究聚焦于单模态生成,虽然在个别任务上实现了模型的统一,但很难在OCR领域的多数任务上做到全面整合。
例如,Monkey等视觉语言模型(VLM)擅长文字检测、识别和视觉问答(VQA)等文本模态生成任务,却无法胜任文字图像的生成、抹除和编辑等图像模态生成任务。反之,以 AnyText 为代表的基于扩散模型的图像生成模型则专注于图像创建。因此,OCR领域亟需一个能够统一多模态生成的大模型。

为解决这一难题,字节跳动与华东师范大学的联合研究团队提出了创新性的多模态生成模型TextHarmony,不仅精通视觉文本的感知、理解和生成,还在单一模型架构中实现了视觉与语言模态生成的和谐统一。
目前论文已经上传arXiv,代码也即将开源,链接可在文末领取。

TextHarmony的核心优势在于其成功整合了视觉文本的理解和生成能力。传统研究中,这两类任务通常由独立模型处理。TextHarmony 通过融合这两大类生成模型,实现了视觉文字理解和生成的同步进行,从而统筹了 OCR 领域的多数任务。
研究表明,视觉理解和生成之间存在显著差异,直接整合可能导致严重的模态不一致问题。具体而言,多模态生成模型在文本生成(视觉感知、理解)和图像生成方面,相较于专门的单模态模型,性能出现明显退化。

数据显示,多模态生成模型在文本生成任务上较单模态模型效果降低 5%,图像生成任务上最高降低8%。而 TextHarmony 成功缓解了这一问题,其在两类任务上的表现均接近单模态专家模型水平。
TextHarmony 采用了 ViT、MLLM 和 Diffusion Model 的组合架构:
这种结构实现了多模态内容的全面理解与生成。
Slide-LoRA:解决方案
为克服训练过程中的模态不一致问题,研究者提出了 Slide-LoRA 技术。该方法通过动态整合模态特定和模态无关的 LoRA(Low-Rank Adaptation)专家,在单一模型中实现了图像和文本生成空间的部分解耦。
Slide-LoRA 包含一个动态门控网络和三个低秩分解模块:

DetailedTextCaps-100K: 高质量数据集
为提升视觉文本生成性能,研究团队开发了 DetailedTextCaps-100K 数据集。该集利用闭源 MLLM(Gemini Pro)生成详尽的图像描述,为模型提供了更丰富、更聚焦于视觉和文本元素的训练资源。

TextHarmony 采用两阶段训练方法:
研究者对 TextHarmony 在视觉文本场景下进行了全面评估,涵盖理解、感知、生成与编辑四个维度:
视觉文本理解:TextHarmony 显著优于多模态生成模型,性能接近 Monkey 等专业文字理解模型。
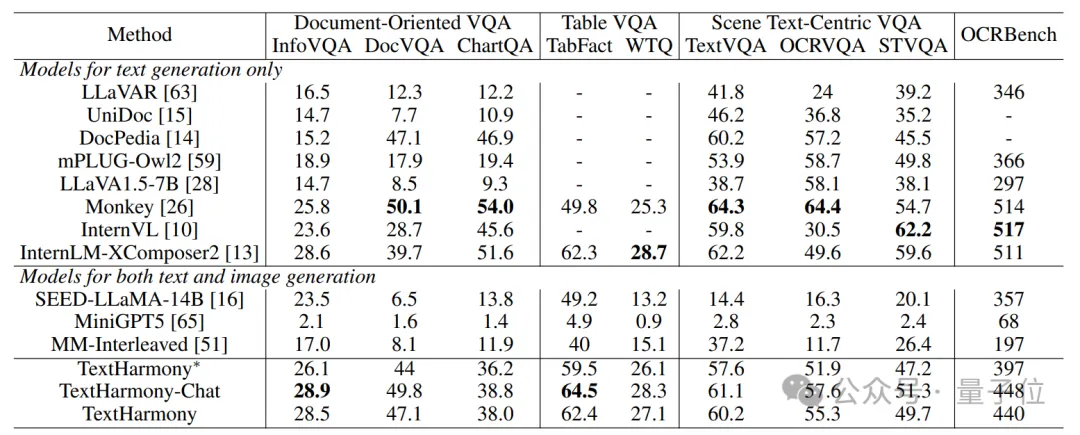
视觉文本感知:在OCR定位任务上,TextHarmony超过了TGDoc、DocOwl1.5等知名模型。

视觉文本编辑与生成:TextHarmony 大幅领先于现有多模态生成模型,且与 TextDiffuser2 等专业模型相当。
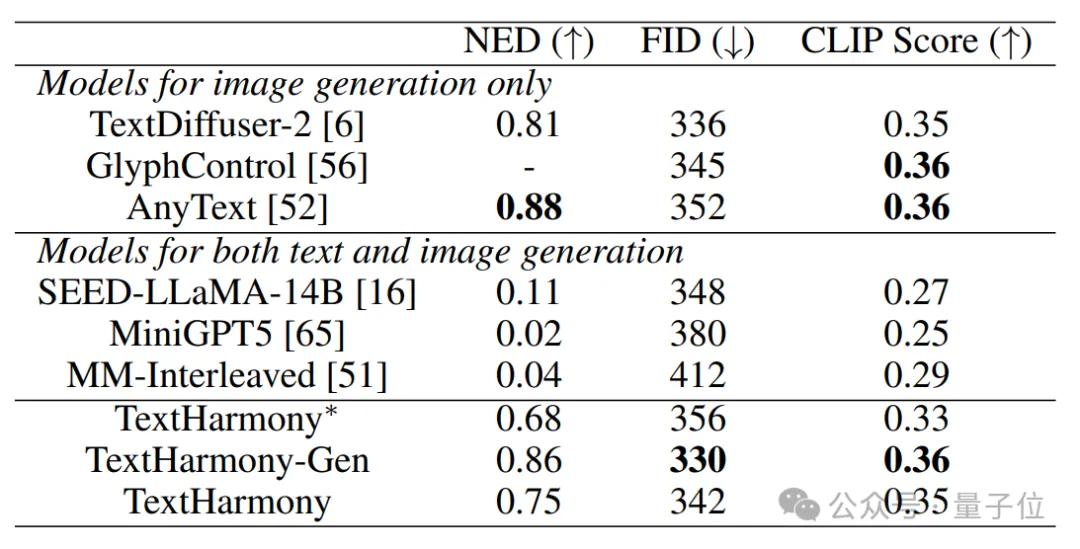


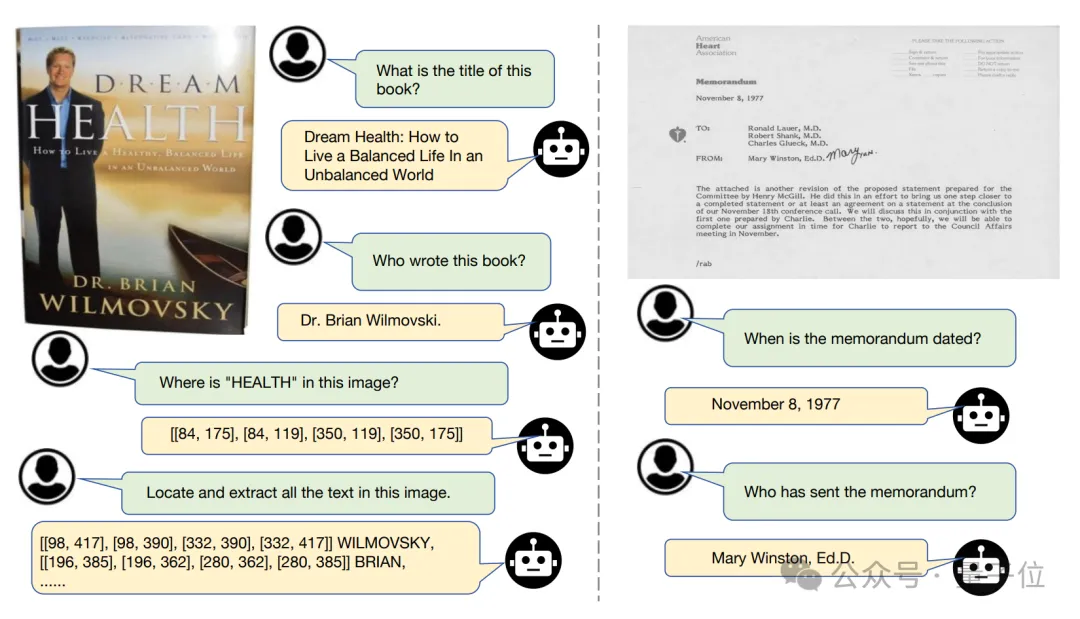
TextHarmony 作为 OCR 领域的多功能多模态生成模型,成功统一了视觉文本理解和生成任务。通过创新的 Slide-LoRA 技术,它有效解决了多模态生成中的模态不一致问题,在单一模型中实现了视觉与语言模态的和谐统一。TextHarmony 在视觉文字感知、理解、生成和编辑方面展现出卓越性能,为复杂的视觉文本交互任务开辟了新的可能性。
这项研究不仅推动了 OCR 技术的进步,也为人工智能在理解和创造方面的发展提供了重要参考。未来,TextHarmony 有望在自动文档处理、智能内容创作、教育辅助等多个领域发挥重要作用,进一步推动人工智能的应用。
论文链接: https://arxiv.org/abs/2407.16364
代码开源: https://github.com/bytedance/TextHarmony(即将开源)
文章来自于微信公众号“量子位”,作者“TextHarmony团队”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
