# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在正是「文本生视频」赛道百花齐放的时代,而且其应用场景非常多,比如生成创意视频内容、创建游戏场景、制作动画和电影。甚至有研究表明还能将视频生成用作真实世界的模拟器,比如 OpenAI 今年初就发布过一份将视频生成模型作为世界模拟器的技术报告,参阅机器之心报道《我在模拟世界!OpenAI 刚刚公布 Sora 技术细节:是数据驱动物理引擎》。
文本生视频模型的这些近期应用既有望实现互联网规模级别的知识迁移(比如从生成人类视频到生成机器人视频),也有望打通实现通用智能体的道路(比如用单个策略控制不同环境中不同形态的机器人来执行多种多样的任务)。
然而,现实情况是,文本生视频模型的下游应用还很有限,原因包括幻觉问题以及生成的视频内容不符合现实物理机制等。
虽然理论上可以通过扩大数据集和模型大小来有效减轻这些问题,但对视频生成模型来说,这会很困难。
部分原因是标注和整理视频的人力成本很高。另外,视频生成方面还没有一个非常适合大规模扩展的架构。
除了扩大规模,LLM 领域的另一个重要突破是能整合外部反馈来提升生成质量。那文本生视频模型也能受益于这一思路吗?
为了解答这一问题,一个多所机构的研究团队探索了视频生成模型能自然获得的两种反馈类型,即来自视觉 - 语言模型(VLM)的 AI 反馈和将生成的视频转换成运动控制时得到的真实世界执行反馈。
为了利用这些反馈来实现视频生成模型的自我提升,该团队提出了 VideoAgent,即视频智能体。该研究有三位共一作者:Achint Soni、Sreyas Venkataraman 和 Abhranil Chandra。其他参与者包括滑铁卢大学 Sebastian Fischmeister 教授、斯坦福大学基础模型研究中心(CRFM)主任 Percy Liang 以及 DeepMind 的 Bo Dai 和 Sherry Yang(杨梦娇)。

不同于将生成的视频直接转换成运动控制的策略,VideoAgent 的训练目标是使用来自预训练 VLM 的反馈来迭代式地优化生成的视频规划。
在推理阶段,VideoAgent 会查询 VLM 以选择最佳的改进版视频规划,然后在环境中执行该规划。
在在线执行过程中,VideoAgent 会观察任务是否已成功完成,并根据来自环境的执行反馈和从环境收集的其它数据进一步改进视频生成模型。
生成的视频规划获得了两方面的改进:
图 1 是 VideoAgent 的直观图示。

他们首先考虑的是基于第一帧和语言的视频生成,即根据语言描述找到从初始图像开始的一个图像帧序列。通常来说,当某个样本来自一个视频生成模型时,其中一部分更真实(开始部分),另一部分则充满幻觉(结尾部分)。
也就是说,虽然生成的视频规划可能无法完全完成指定的任务,但它能提供有意义的信息,以帮助进一步改进以实现正确的规划。
为了利用这样的部分进展,该团队使用了一个视频一致性模型,即基于之前的自我生成的样本为 ground truth 视频执行扩散,这样模型就可以学会保留视频的真实部分,同时优化其中的幻觉部分。
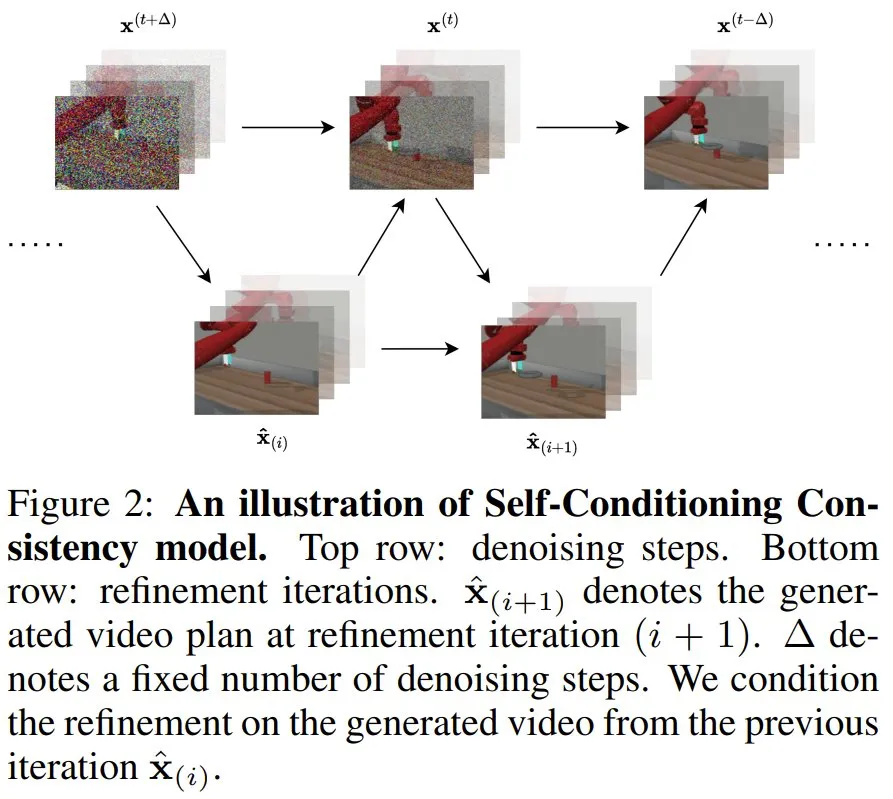
此外,除了基于之前生成的样本来优化视频,该团队还纳入了反馈,包括来自人类的反馈和来自 VLM 的反馈。这被称为反馈引导的自我调节一致性。
这里我们仅描述了其大概方法,详细过程和形式化描述请参阅原论文。
在训练了视频生成模型和视频优化模型之后,可采样视频生成模型然后迭代式地使用优化模型来实现视频优化。
具体来说,VideoAgent 首先会基于第一帧和语言的视频生成来「猜测」视频规划。
接下来,迭代地使用优化模型来执行优化,这里会使用 VLM 来提供反馈。
算法 1 展示了使用 VLM 反馈的视频生成和优化模型。

算法 2 则给出了在推理时间生成、优化和选择视频规划(重新规划)的方式。

除了上面描述的基于自我调节一致性的视频优化,该团队还进一步将视频生成和视频细化的组合描述为一种策略,该策略可以通过在线交互期间从环境中收集的额外真实数据进行训练,从而实现改进。
有多种强化学习技术可以满足这一需求,算法 3 描述了其细节。

为了评估 VideoAgent,该团队进行了多个实验,包括该模型的端到端成功率、不同组件的效果以及能否提升真实机器人视频的质量。
实验中,该团队考虑了三个数据集:
实验过程就不过多赘述了,直接来看结果。
首先,表 1 给出了在 Meta-World 上的端到端任务成功率。
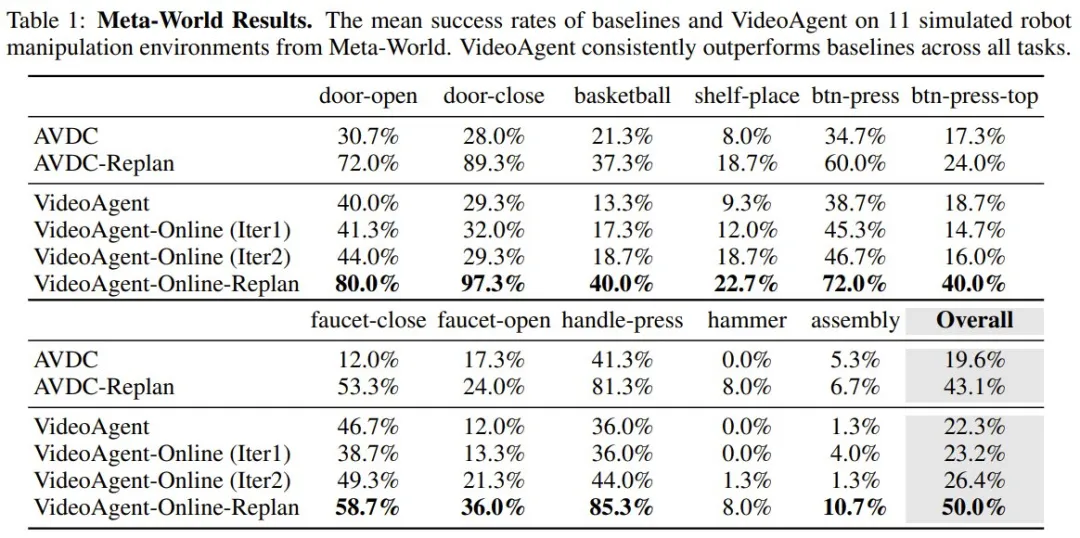
可以看到,自我调节一致性已经能让 VideoAgent 的总体成功率超越基线(19.6% 到 22.3%),其中一些任务更是大幅提升,比如在关闭水龙头(faucet-close)任务上的成功率从 12% 猛增至 46.7%。
而如果再进一步引入在线微调,成功率还能进一步提升,并且多迭代一次都会多一点提升。
引入重新规划后,VideoAgent 的优势仍然存在,并且总体任务成功率达到了 50%,达成了该设置下的当前最佳水平。
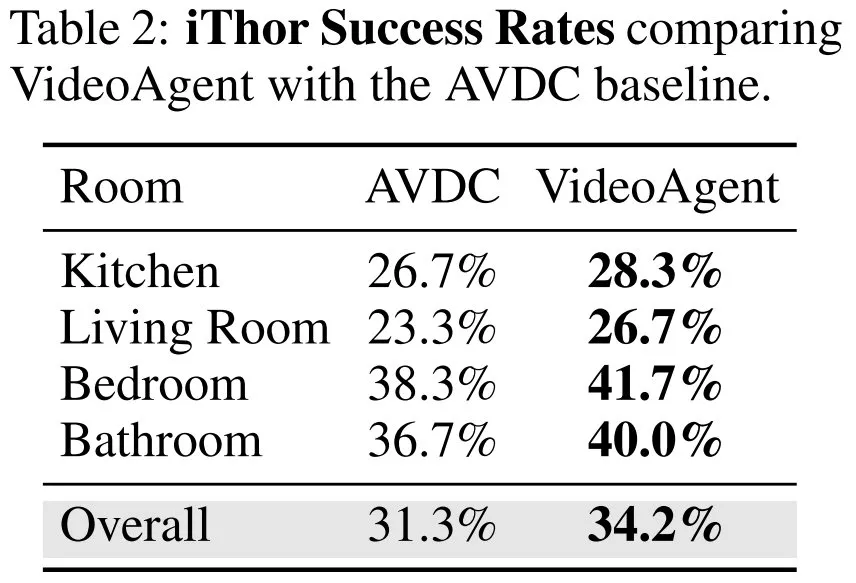
表 2 展示了在 iTHOR 上的成功率,可以看到 VideoAgent 同样全面优于基线 AVDC。
该团队也通过对比研究分析了 VideoAgent 不同组件的效果,具体包括 (1) 向优化模型提供不同类型的反馈,(2) 改变优化和在线迭代的次数,(3) 调整 VLM 反馈的质量。
表 3 展示了不同 VLM 反馈的效果(基于 Meta-World)。可以看到,不管是二元反馈还是描述性反馈,都比没有反馈好,更比基线 AVDC 好得多。
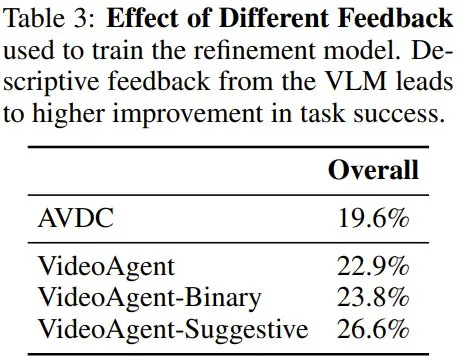
图 3 和 4 分别展示了优化和在线迭代的次数的影响。整体来看,增多迭代次数有助于提升模型,并且效果很显著。
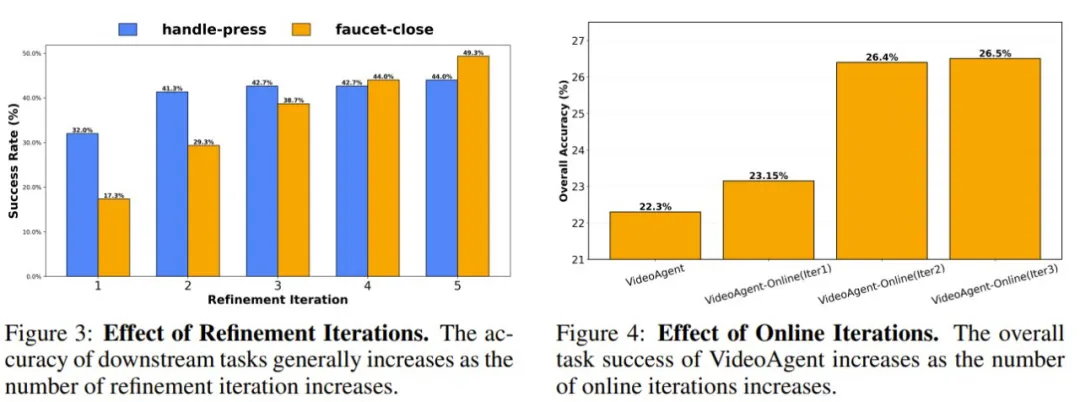
由于这项研究是首批利用 VLM 为视频生成提供反馈的研究之一,因此一个重要的研究课题是:了解 VLM 是否真的可以为视频生成提供足够准确的反馈。
表 4 给出了 VLM 反馈的各项性能指标,这里使用了人工标注作为 ground truth 来进行评估。

可以看到,原始提示词(Unweighted)的准确度是 69%,这说明 VLM 足以评价生成的视频。而通过重新加权来惩罚假正例(Weighted)还能大幅提升其准确度。另外值得注意的是,从提示词中移除第三个摄像头甚至还能获得更高的准确度,这说明 VLM 的准确性会受到部分可观测性的影响。
最后,该团队也评估了 VideoAgent 改进真实视频的能力。结果见表 5。
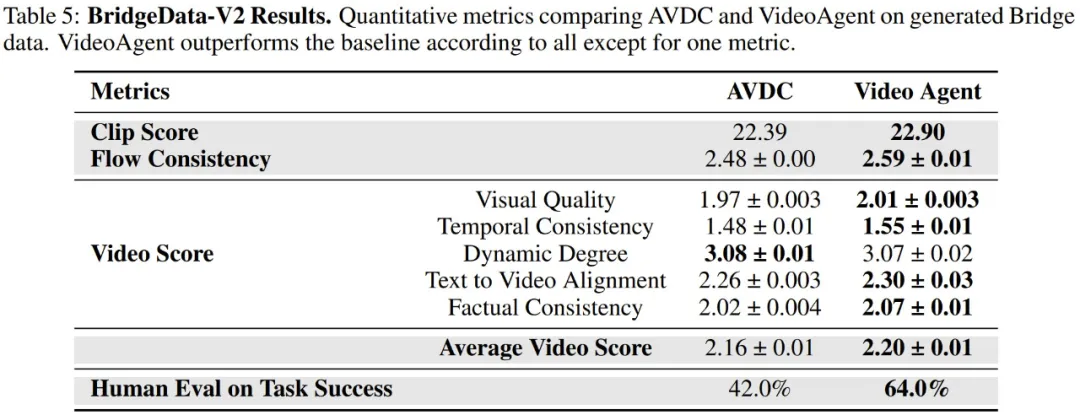
可以看到,在视频分数的 5 个子指标上,VideoAgent 在其中 4 个上表现更优,在唯一的例外「动态分数」上也与基线差距细微。此外,VideoAgent 在 CLIP 分数、流一致性和人类评估上也都更好。这表明 VideoAgent 可以生成更流畅、更符合现实世界的物理逻辑的视频。
最后,图 5 给出了一个定性评估结果。

其中,中间行是基线,可以看到其出现了幻觉(碗消失了),而 VideoAgent 很好地完成了视频生成任务。
文章来自于微信公众号“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
