# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这篇论文刚刚中稿 NeurIPS Oral(64/15671 =0.4%),作者分别来自澳门大学、德克萨斯大学奥斯汀分校以及剑桥大学。其中,第一作者田春霖是澳门大学计算机系的三年级博士生,研究方向涉及 MLSys 和高效大语言模型。师从栗力、须成忠教授。
大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。为了缓解这一问题,业界提出了多种参数高效微调(PEFT)方法,例如 LoRA。然而,LoRA 在面对复杂数据集时,总是难以与全参数微调的表现相媲美,尤其当任务之间充满多样性时,效果更是大打折扣。
为了突破这一瓶颈,来自澳门大学、德克萨斯大学奥斯汀分校以及剑桥大学的研究者联合提出了一种全新的非对称 LoRA 架构 —— HydraLoRA。与传统 LoRA 需要对所有任务使用相同的参数结构不同,HydraLoRA 引入了共享的 A 矩阵和多个独立的 B 矩阵,分别处理不同的任务,从而避免任务间的干扰。九头蛇(Hydra)的每个头就像 LoRA 中的 B 矩阵一样,专注于各自的特定任务,而共享的 A 矩阵则像九头蛇的身体,统一管理和协调,确保高效和一致性。无需额外工具或人为干预,HydraLoRA 能够自主识别数据中的隐含特性,极大提升了任务适应性与性能表现。借助这种多头灵活应对的机制,HydraLoRA 实现了参数效率与模型性能的双重突破。

一句话总结:HydraLoRA 引入了一种非对称的参数微调架构,能够有效识别并适应数据中的 “内在组件”—— 即子领域或不同任务,这些组件可能难以被领域专家明确界定。其核心思想是通过共享的 A 矩阵和独立的 B 矩阵,最大限度地减少任务间的相互干扰,对每个内在组件进行优化调整。HydraLoRA 自主分配不同的 B 矩阵来捕捉特定任务的特性,而共享的 A 矩阵负责全局信息的整合,从而实现了高效的参数利用和性能提升。在复杂的多任务环境中,HydraLoRA 展现出了卓越的适应性,能够灵活处理各个内在组件,显著提升模型的准确性和效率,同时优化了资源消耗。
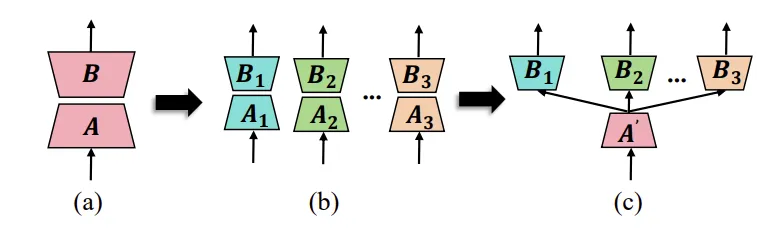
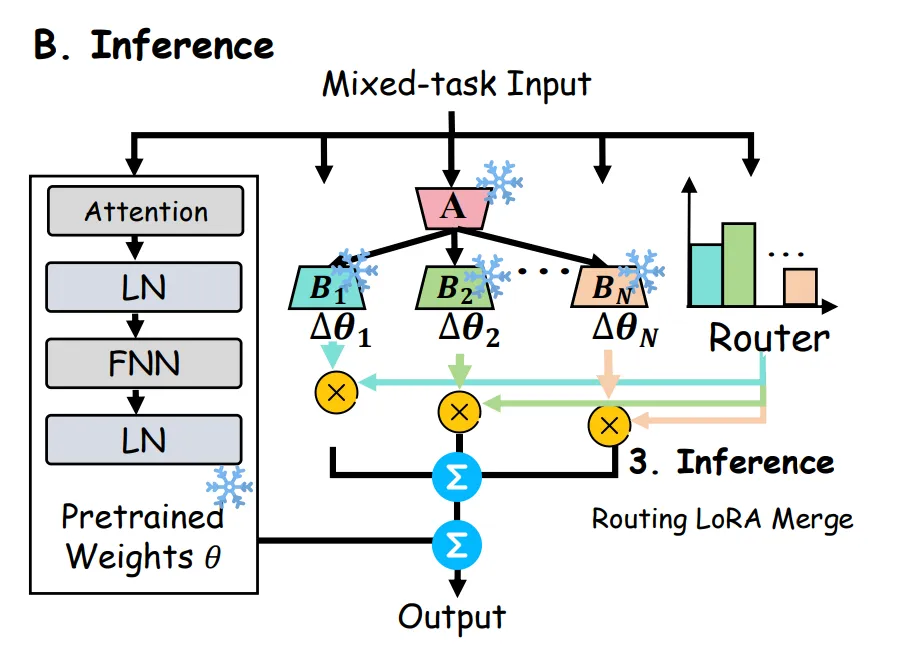
HydraLoRA 中 LoRA 架构变化示意图
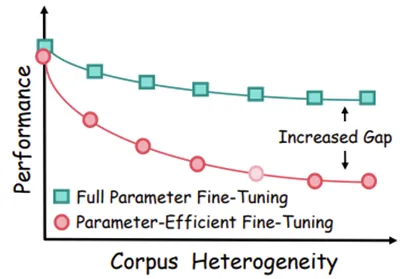
LoRA 的现实困境:参数高效微调(PEFT)技术与全参数微调(FFT)之间存在显著的性能差距,尤其在处理更多样化或异质的训练语料库时,这一差距会进一步扩大。语料库的异质性意味着数据集的多样性,由于内容和风格各异,往往会引入干扰。PEFT 方法对此尤为敏感,在异构情况下性能损失更为严重。
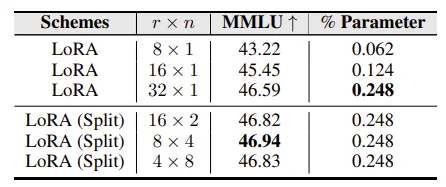
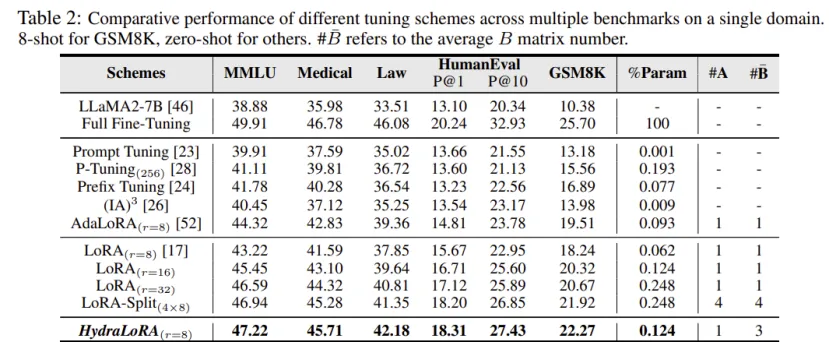
LoRA 的分析观察 1:在参数数量相同的情况下,与其对整个域数据集使用单个 LoRA,不如部署多个较小的 LoRA 模块,每个模块专注于特定的下游任务。如下表所示,对于 LoRA (Split),该研究将高秩的 LoRA 模块分解为多个较小且等效的低秩组件(r×n),其中 n 表示 LoRA 的数量,r 代表每个 LoRA 的秩。这表明任务之间的干扰可能对训练过程产生负面影响。
此外,研究团队认为这种干扰并不限于显式的多任务训练场景。在任何训练设置中,这种干扰都有可能发生,因为所有数据集本质上都包含多个隐含的内在组件,例如子领域或域内的任务,这些组件甚至连领域专家也未必能够明确区分。
LoRA 的分析观察 2:当多个 LoRA 模块在不同数据上独立训练时,不同头的矩阵 A 参数趋于一致,而矩阵 B 的参数则明显可区分。下图展示了 LoRA 模块的分解分析,通过 t-SNE 比较。各个头部的 A 矩阵参数高度相似,导致在图中重叠。相比之下,不同头部的 B 矩阵参数则明显不同,易于区分。研究团队认为这种不对称现象主要源于 A 矩阵和 B 矩阵的初始化方式不同。A 矩阵倾向于捕捉跨领域的共性,而 B 矩阵则适应领域特定的差异。A 和 B 矩阵之间的区别为提升参数效率和有效性提供了重要见解。从效率角度来看,该研究假设 A 矩阵的参数可以在多个头部之间共享,从而减少冗余。就有效性而言,由于不同头部的 B 矩阵参数分散,说明使用单一头部来适应多个领域的效果可能不如为每个领域使用独立头部更为有效,因为这能最大程度地减少领域之间的干扰。
微调阶段:HydraLoRA 无需特定的领域知识即可自适应地识别并初始化 N 个内在组件。然后,它利用一个可训练的 MoE(Mixture of Experts)路由器,将每个内在组件视为专家,自动将训练样本划分到对应的组件进行微调。
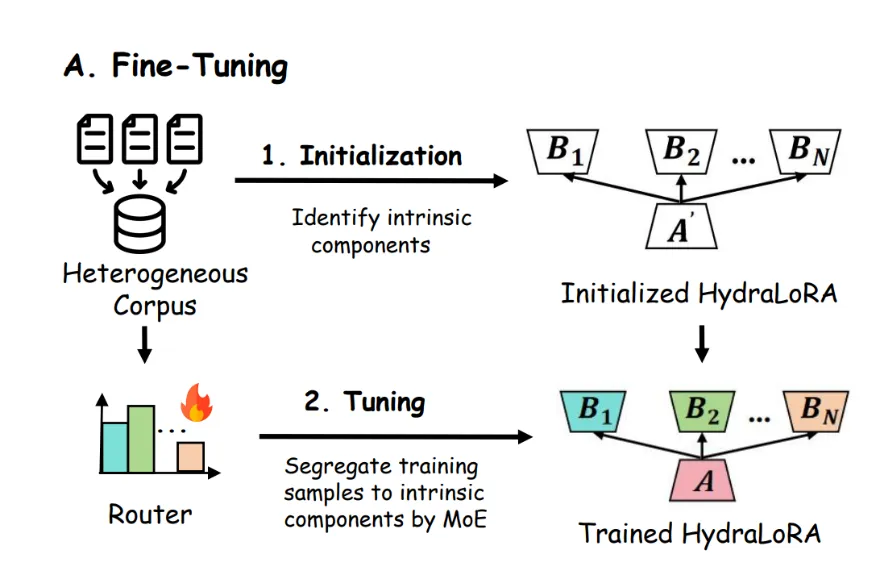
推理阶段:HydraLoRA 通过训练完成的路由器,灵活且动态地合并多个 B 矩阵,以满足不同任务和数据的需求。这样的设计使得模型能够高效地适应多样化的应用场景,提升了整体性能和资源利用效率。
该研究使用 HydraLoRA 在单任务(通用、医学、法律、数学和代码)和多任务(Flanv2)场景下进行了全面验证。
不同微调方案在单一领域多个基准中的性能比较:
在 BBH 基准上跨混合任务域的不同微调方案性能比较:

从以上两个表格可以得出以下结论:
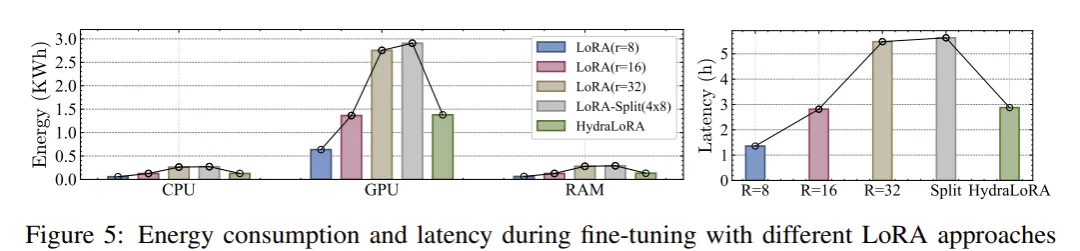
HydraLoRA 的 “Hydra” 结构如何提高系统效率,降低训练能耗和延迟?如下图所示,该研究从训练能耗和延迟两个方面评估了 HydraLoRA 的系统效率。结果显示,HydraLoRA 在系统效率上具有显著优势。首先,HydraLoRA 通过非对称结构优化了能耗和延迟,减少了训练过程中的能源消耗和时间延迟。
1. 本文提出了一种新的参数高效微调架构,HydraLoRA,通过共享 A 矩阵和多个独立的 B 矩阵,减少任务间的干扰并提高性能;
2. 本文挑战了单一 LoRA 结构的局限性,提出了一个通过分离内在组件来优化微调过程的框架,能够自动识别数据中的不同子任务或子领域,进一步增强了模型的适应性;
3. 无论是处理单任务还是多任务,HydraLoRA 都在不同的领域中表现优异,同时显著减少了参数量和计算资源的消耗。更令人振奋的是,HydraLoRA 的非对称架构摆脱了手动干预的需求,通过自动化的方式优化了任务间的学习过程。
文章来自于微信公众号“机器之心”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
