# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
内存占用小,训练表现也要好……大模型训练成功实现二者兼得。
来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。

展开来说——
为了突破内存瓶颈,许多低秩训练方法应运而生,如LoRA(分解参数矩阵)和GaLore(分解梯度矩阵)。
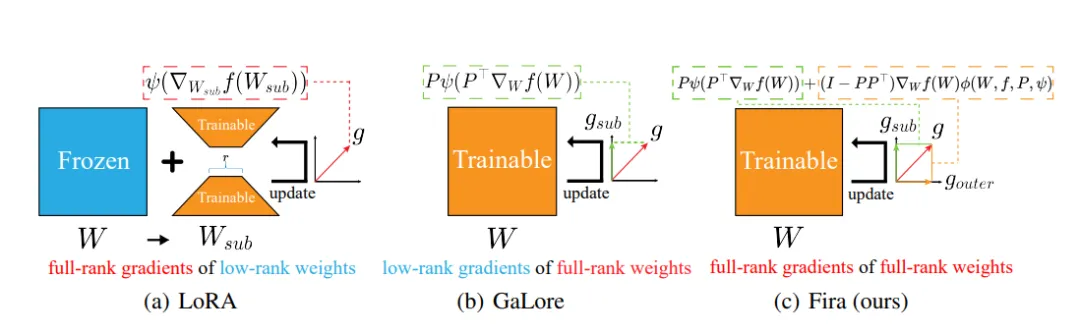 △图1:从宏观层面分析三种内存高效低秩训练方法
△图1:从宏观层面分析三种内存高效低秩训练方法
然而,如上图所示,LoRA将训练局限于参数的低秩子空间,降低了模型的表征能力,难以实现预训练;GaLore将训练局限于梯度的低秩子空间,造成了子空间外梯度的信息损失。
相较于全秩训练,这两种方法由于施加了低秩约束,会导致训练表现有所下降。
但是,若提高秩值,则会相应地增加内存占用。
因此,在实际应用中,它们需要在确保训练表现与降低内存消耗之间找到一个恰当的平衡点。
这引发了一个核心问题:
能否在维持低秩约束以确保内存高效的同时,实现全秩参数、全秩梯度的训练以提升表现?
Fira即为最新答案,它有三大亮点:
from fira import FiraAdamW, divide_params
param_groups = divide_params(model, target_modules_list = [“Linear”], rank=8)
optimizer = FiraAdamW(param_groups, lr=learning_rate)
Fira训练框架由两部分组成:
1) 基于梯度模长的缩放策略:利用了团队在大模型低秩和全秩训练中发现的共通点——自适应优化器对原始梯度的修正效应,实现了低秩约束下的全秩训练。
2) 梯度模长限制器,通过限制梯度模长的相对增长比例,解决了大模型训练中常出现的损失尖峰问题。


为了弥补上述信息损失,最直观的方法是直接加上这一部分梯度(G????—P????R????):
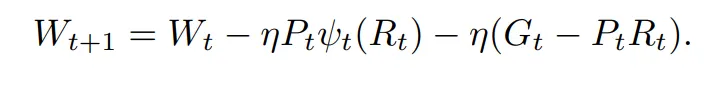
其中,W是参数矩阵, ????是学习率。
然而,如图所示,使用这种方法(Galore-add)不仅未能带来性能提升,反而可能导致训练过程更加不稳定,且结果更差。
分析原因可归结于这一部分的梯度缺乏优化器状态,直接使用会退化为单纯的SGD算法,并且可能与前面使用的Adam优化器的梯度不匹配,导致效果不佳。
为了解决上述挑战,团队提出了scaling factor概念,来描述Adam这样的自适应优化器对原始梯度的修正效应,并揭示了它在大模型的低秩训练和全秩训练之间的相似性。
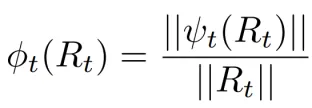
其中,???? 就是scaling factor,代表经过优化器修正过的梯度与原始梯度的模长比例。
如下图,如果根据scaling factor的平均值对参数矩阵进行排序,可以发现低秩和全秩之间的排序非常相似。
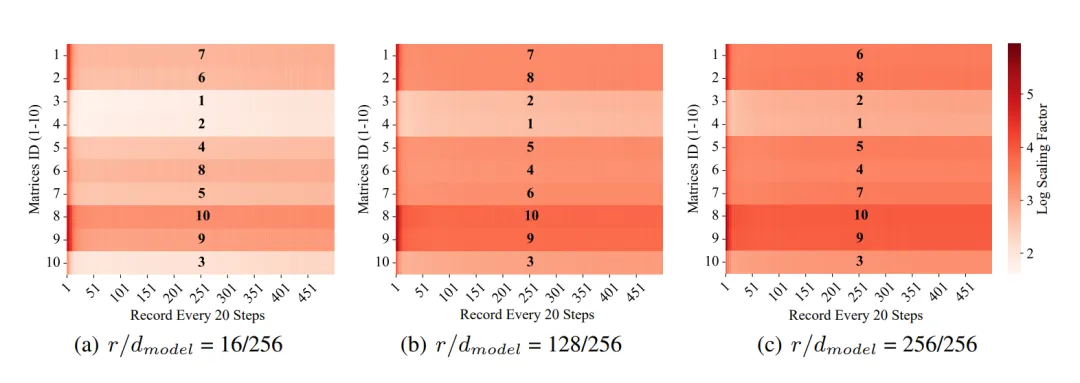
基于这个观察,团队就尝试在矩阵层面用低秩梯度R????的scaling factor,作为全秩梯度G????的scaling factor的替代,从而近似地修正(G????—P????R????),弥补其缺少的优化器状态:
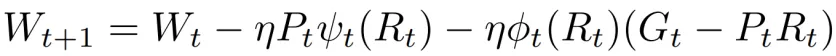
这样团队就在低秩约束下成功实现了全秩训练。
进一步来说,刚才是从矩阵层面来考虑scaling factor。
顺理成章地,团队可以从更细粒度的角度——列的层面,来考虑scaling factor,实现更加精细地修正。
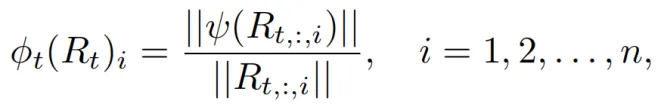
其中R????,:,???? 是低秩梯度R????的第i列, 是scaling factor的第i项。
是scaling factor的第i项。
在训练过程中,梯度常常会突然增大,导致损失函数出现尖峰,从而影响训练的表现。
经过分析,可能原因是Galore在切换投影矩阵时存在不稳定性,以及维持(G????—P????R????)这种原始梯度的方向的方式,无法像Adam这样的自适应算法,有效应对大模型训练中存在的陡峭损失景观。
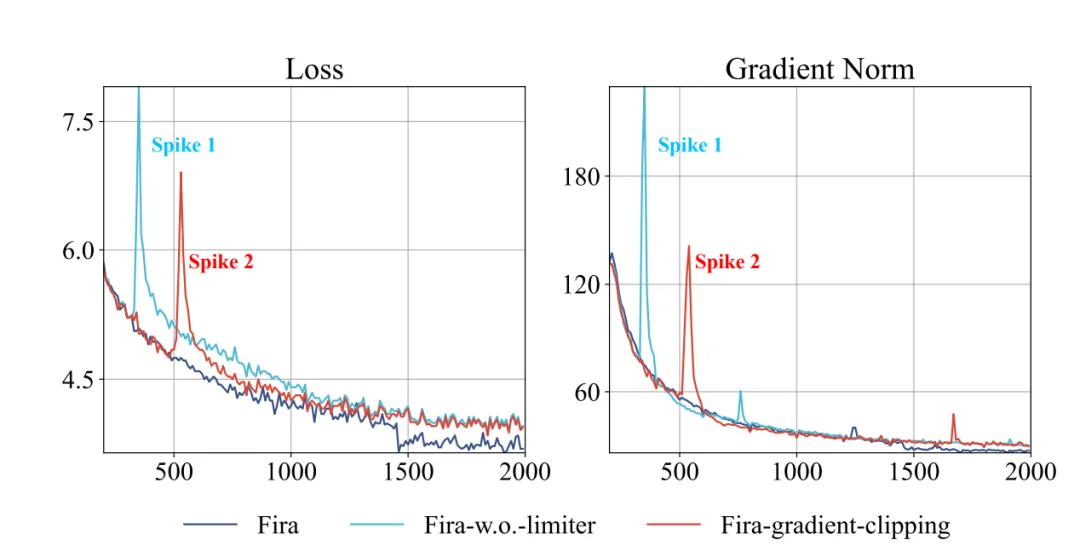
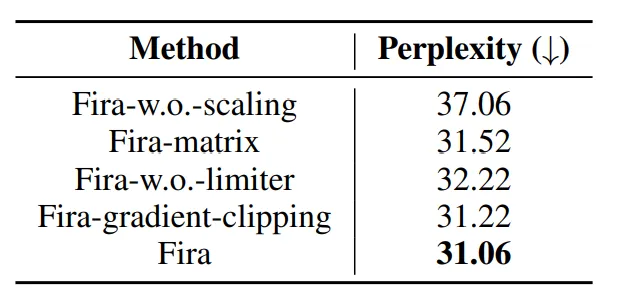
然而,常见的梯度裁剪方法(如图中的Fira-gradient-clipping)由于采用绝对裁剪,难以适应不同参数矩阵间梯度的较大差异,从而可能导致次优的训练结果。
为此,团队提出了一种新的梯度模长限制器,它通过限制梯度模长的相对增长比例,来更好地适应不同梯度的变化:
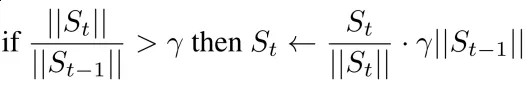
其中????是比例增长的上限,S????=????????(R????)(G????—P????R????)是原始梯度(G????—P????R????)修正后的结果。
通过提出的控制梯度相对增长比例的方法,能够将梯度的骤然增大转化为平缓的上升,从而有效稳定训练过程。
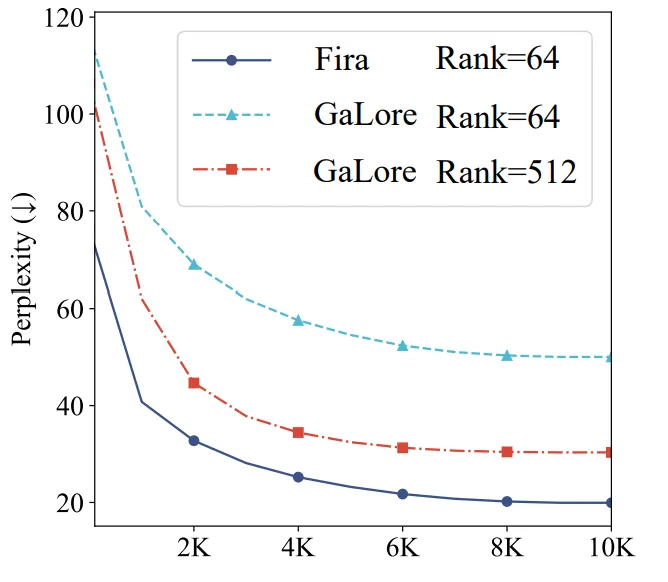
如图2和图3所示,团队的限制器成功避免了损失函数的尖峰情况,并显著提升了训练表现。
如下表所示,在预训练任务中,Fira在保持内存高效的前提下,验证集困惑度(↓)显著超过各类基线方法,甚至超越全秩方法。
具体来说,在预训练LLaMA 1B模型时,Fira节约了61.1%优化器状态所占内存,并且取得了比全秩训练更加好的结果。
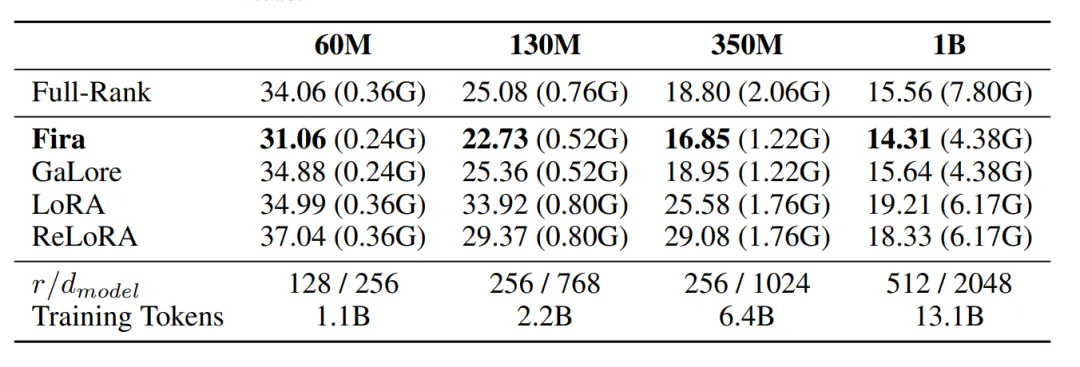
在预训练LLaMA 7B模型时,Fira在使用了比Galore小8倍的秩rank的情况下,训练表现远超Galore。
这展现了Fira在大规模大模型上的有效性,以及相较Galore更高的内存减少能力。
在八个常识推理数据集微调LLaMA 7B的任务中,相较其他基线方法,Fira在一半的数据集下表现最好,平均准确率最高的同时实现了内存高效。

另外,消融实验也显示了:
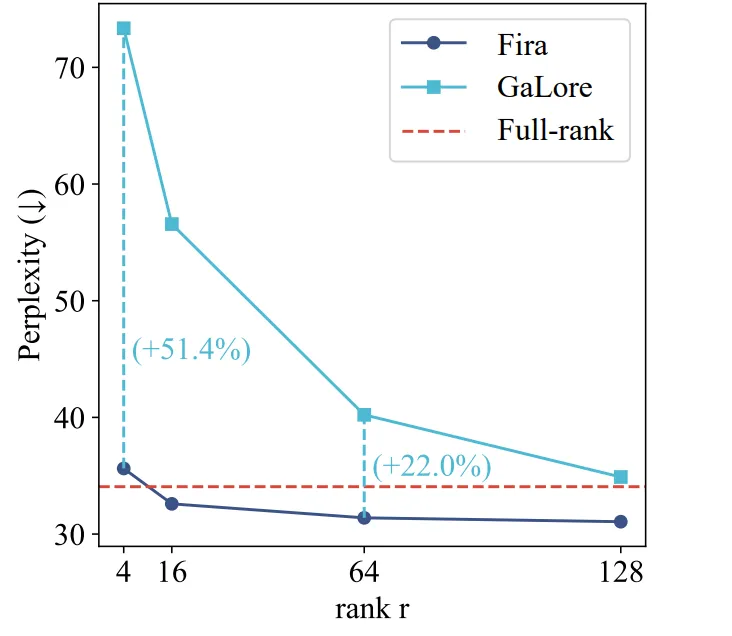
与GaLore相比,Fira的表现几乎不受秩rank值减少的影响。
在低秩的情况下(rank=16, rank=4),Fira仍然能与全秩训练相当,相较Galore更加内存高效。
最后,团队在不同模型大小,以及低秩和全秩条件下,训练10,000步,并对得到的矩阵和列级别上Scaling factor做平均。
接着,使用了斯皮尔曼(Spearman)和肯德尔(Kendall)相关系数分析了Scaling factor在矩阵和列级别上大小顺序的相关性。
其中,Coefficient中1代表完全正相关,-1代表完全负相关,而P-value越小越好(通常小于0.05为显著)。
在所有规模的LLaMA模型中,Scaling factor在矩阵和列的级别上都表现出很强的正相关关系,并且所有的P-value小于0.05,非常显著,为Fira中基于梯度模长的缩放策略提供了坚实的实验基础。

更多细节欢迎查阅原论文。
论文链接:https://arxiv.org/abs/2410.01623
代码仓库:https://github.com/xichen-fy/Fira
文章来自于微信公众号“量子位”,作者“Fira团队”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
