# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有不少读者反映,静态提示词在很多AI应用中的局限性非常大,尤其是需要面对需要深度推理的复杂任务时,即使用最先进的LLMs也常常显得力不从心。这不仅暴露了当前LLMs在推理能力上的短板,也为AI研究者们提出了一个迫切需要解决的挑战:如何让LLMs能够更加灵活、高效地进行动态推理?
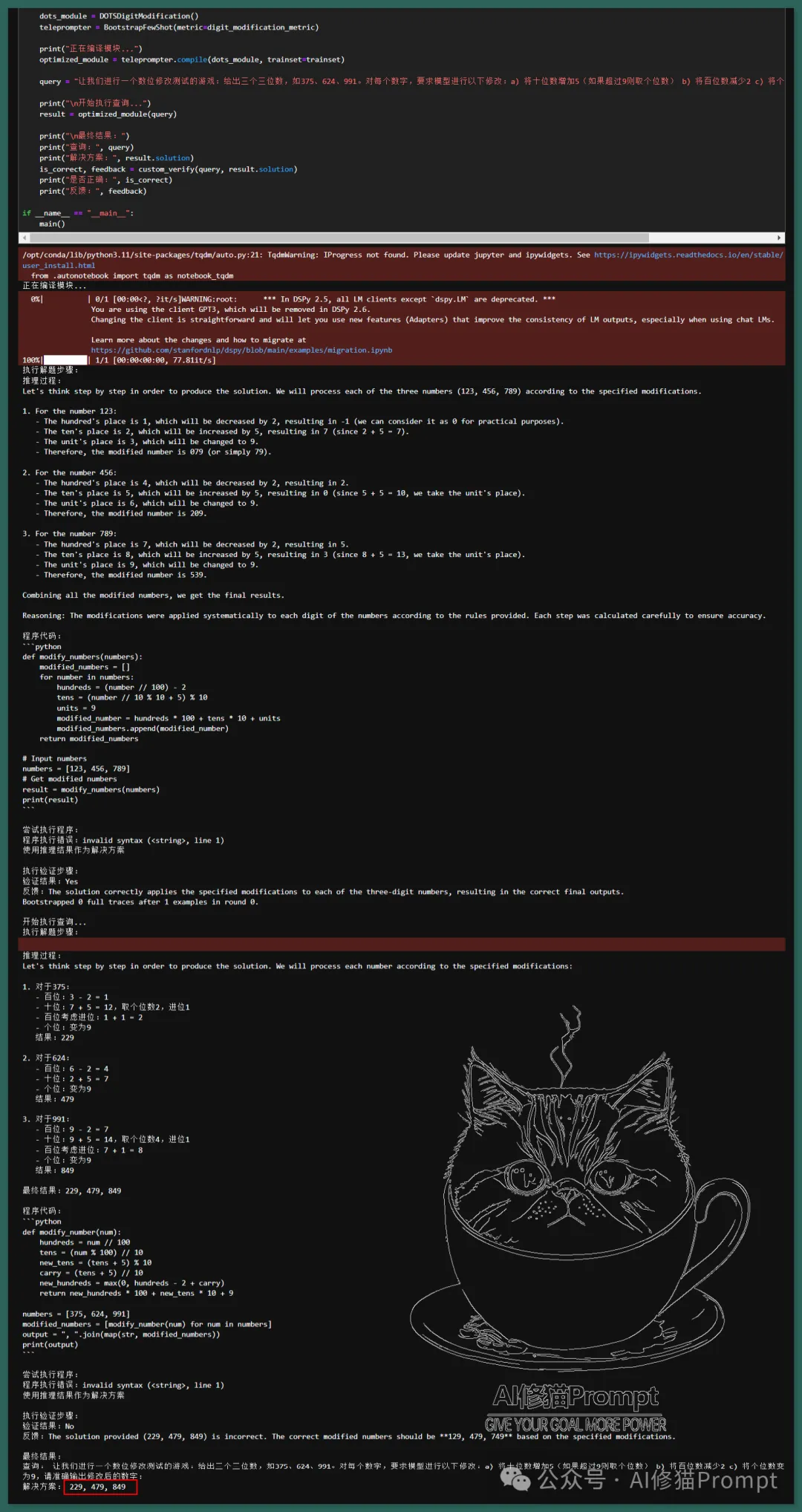
近日,来自乔治梅森大学和腾讯AI实验室的研究团队在这一领域取得了重大突破。他们提出了一种名为DOTS(Dynamic Optimal Trajectory Search)的创新方法,通过最佳推理轨迹搜索,显著提升LLMs的动态推理能力。这项研究不仅在理论上开创性地提出了动态推理的新范式,这种新的范式或许哪天也有LLM厂商捏进模型能成为新的一代O1 Advance版。作者给出了代码链接但还没有放出代码,我已经将其方法用DSPy成功解决了论文中的24Game问题和上一篇文章中《揭秘LLM数不清小数点?牛津等高校最新发现,LLM都在以10为基数对数字进行编码》看似简单的数位修改测试题,可能可以给您在AI开发中带来一些启发。另外,您也可以根据算法将其写成Prompt用于您的Agent或者扣子、元宝等Workflow的开发。您有更多问题也可以参照文末办法找我加群讨论。

DOTS方法的核心创新在于,它摒弃了传统方法中对所有问题采用统一、静态推理策略的做法,转而引入了一种动态的、自适应的推理机制。这种机制能够根据每个具体问题的特点以及任务解决LLM的固有能力,灵活选择最优的推理动作序列。

本文将深入探讨DOTS方法的原理、实现以及在实际应用中的潜力。我们将以通俗易懂的语言,结合具体的代码示例,为广大AI产品开发者和Prompt工程师们呈现这一激动人心的研究成果。让我们一起揭开DOTS的神秘面纱,探索如何让LLMs拥有真正的动态推理能力。
当LLMs面对需要多步推理、逻辑分析或数学计算的复杂任务时,它s的表现却常常不尽如人意。以数学推理为例,虽然LLMs能够理解问题描述并给出看似合理的答案,但在解决需要精确计算或多步推导的问题时,它们往往会犯错或给出不完整的解答。这种现象在符号推理、常识推理等任务中同样存在。这一现状揭示了LLMs在处理复杂推理任务时的固有局限性。
现有方法的局限性
为了提升LLMs的推理能力,研究者们提出了多种方法,其中最为人熟知的包括:
1. 思维链(Chain-of-Thought, CoT):通过提示LLM逐步思考,以改善其推理过程。
2. 程序辅助思维(Program-aided Reasoning):利用LLM生成可执行代码来解决问题。
3. 最少到最多(Least-to-Most):将复杂问题分解为多个子问题逐一解决。
4. 自我验证(Self-Verification):让LLM对自己的解答进行验证和修正。
这些方法在特定任务中确实取得了显著成效。然而,它们都存在一个共同的局限性:对所有问题采用预定义的、静态的推理策略。这种"一刀切"的方法忽视了不同问题的特殊性,也没有考虑到不同LLMs在处理各类问题时的固有能力差异。
正是基于对现有方法局限性的深刻认识,研究团队提出了DOTS方法。DOTS的核心思想是:让LLM能够根据问题的具体特征和自身的能力,动态选择最优的推理策略。这种方法的提出基于以下几个关键洞察:
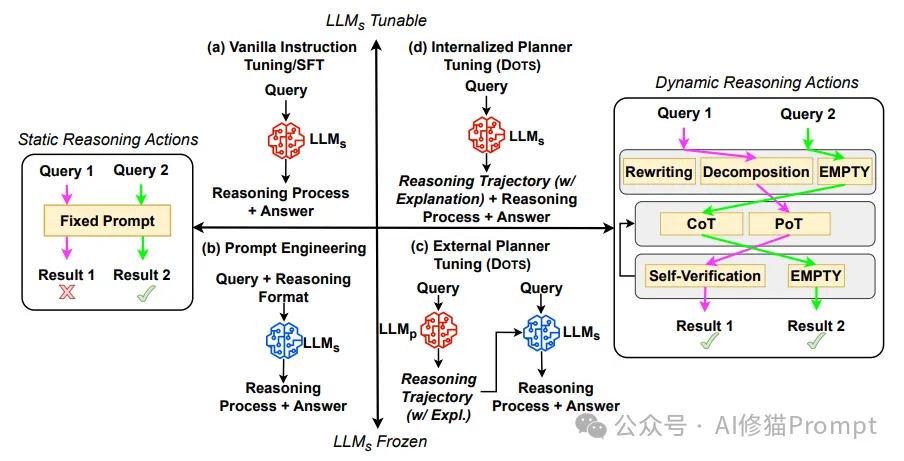
1. 问题多样性:不同类型的问题可能需要不同的推理策略。例如,某些数学问题可能更适合使用程序化方法解决,而某些常识推理问题可能更适合使用思维链方法。
2. 模型能力差异:不同的LLMs可能在处理特定类型的问题时表现各异。例如,一些经过代码训练的模型可能在程序化解决方案上表现更好。
3. 动态适应性:理想的推理系统应该能够根据问题的复杂度动态调整其推理深度和策略。
4. 效率考量:不是所有问题都需要复杂的推理过程。对于简单问题,直接回答可能更为高效。可以看下《DeepMind最新:发布说话者-推理者架构实现Agents快慢思考 | 融合系统1+系统2》这篇说的更清楚。
基于这些考虑,DOTS方法创建了一个能够自动为每个问题选择最佳推理轨迹的系统。这不仅能提高LLMs在各类推理任务中的表现,还能在保证解决质量的同时优化计算效率。具体可以看一下研究者给出的算法:

DOTS方法的核心在于通过动态选择最优推理轨迹来增强LLMs的推理能力。这一方法包含三个关键步骤:定义原子推理动作模块、搜索最优推理轨迹、以及训练LLM的动态规划能力。
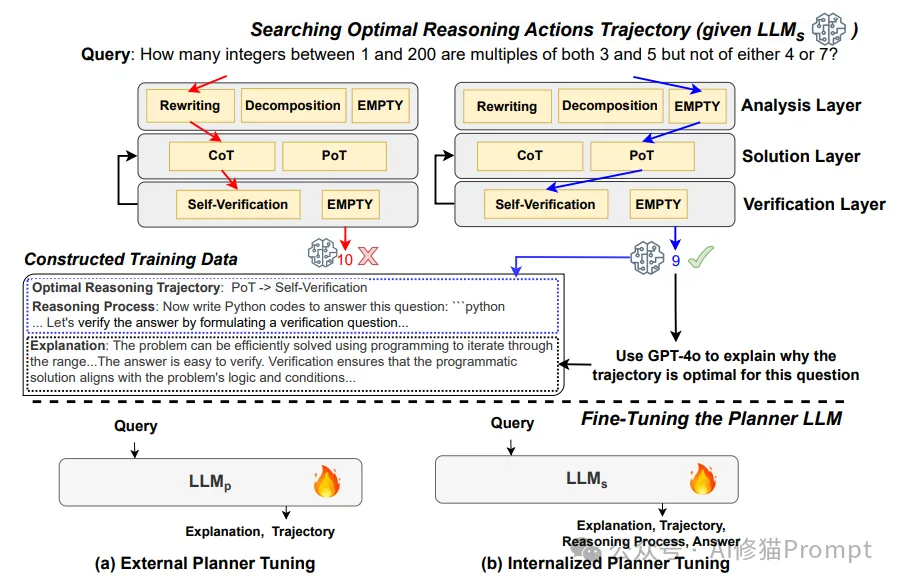
3.1 原子推理动作模块定义
DOTS方法首先定义了一系列原子推理动作模块,这些模块代表了不同的推理策略和步骤。这些模块被分为三个层次:
1. 分析层(Analysis Layer)
- 查询重写(Query Rewriting):重新表述原始问题以增强理解。
- 查询分解(Query Decomposition):将复杂问题分解为多个简单子问题。
2. 解决层(Solution Layer)
- 思维链(Chain-of-Thought, CoT):使用自然语言进行逐步推理。
- 程序思维(Program-of-Thought, PoT):通过编写和执行代码来解决问题。
关于这个部分请您有兴趣可以看下之前的文章《用这条Prompt构建CoT+PoT验证器评估LLM输出,显著提高LLM推理准确性和一致性》,在DSPy框架中,这些模块可以通过定义不同的Signature类来实现。例如:
class QueryRewrite(dspy.Signature):
"""重写查询以增强理解"""
query = dspy.InputField()
rewritten_query = dspy.OutputField()
class ChainOfThought(dspy.Signature):
"""使用自然语言进行逐步推理"""
query = dspy.InputField()
reasoning = dspy.OutputField()
solution = dspy.OutputField()
class SelfVerification(dspy.Signature):
"""验证解决方案的正确性"""
query = dspy.InputField()
solution = dspy.InputField()
is_correct = dspy.OutputField()
feedback = dspy.OutputField()
关于DSPy您可以看之前的文章,有很多篇介绍这个LLM框架。
3. 验证层(Verification Layer)
- 自我验证(Self-Verification):检查解决方案的正确性。
在DSPy框架中,这些模块可以通过定义不同的`Signature`类来实现。例如:
这种模块化的设计允许系统灵活组合不同的推理动作,从而构建出适应不同问题的推理轨迹。
3.2 最优推理轨迹搜索
DOTS方法的核心创新在于其搜索最优推理轨迹的能力。这一过程通过迭代探索和评估来实现,具体步骤如下:
1. 生成候选轨迹:系统首先生成所有可能的推理动作组合。
2. 评估轨迹:对每个候选轨迹进行多次评估,计算其成功率和所需的计算步骤。
3. 筛选和迭代:根据评估结果,保留表现最好的轨迹,并在下一轮迭代中继续优化。
4. 确定最优轨迹:经过多轮迭代后,选择成功率最高且计算步骤最少的轨迹作为最优解。
这一搜索过程可以通过以下Python代码概括:
def search_optimal_trajectory(query, ground_truth, max_iterations=2):
trajectories = generate_initial_trajectories()
for iteration in range(max_iterations):
for trajectory in trajectories:
success_rate = evaluate_trajectory(trajectory, query, ground_truth)
trajectory.score = calculate_score(success_rate, trajectory.length)
trajectories = select_top_trajectories(trajectories)
return get_best_trajectory(trajectories)
这种搜索方法确保了系统能够为每个特定问题和LLM找到最适合的推理策略。
3.3 动态规划能力训练
一旦确定了最优推理轨迹,DOTS方法就会使用这些数据来训练LLM,使其能够自主规划推理过程。这一训练过程有两种实现方式:
1. 外部规划器训练:
对于闭源或计算成本高的LLM,DOTS训练一个较小的外部LLM作为规划器,为主要的任务解决LLM预测最优推理动作。
2. 内部规划器训练:
对于开源和小型LLM,DOTS直接训练任务解决LLM,使其在解决问题之前能够自主规划推理动作。
这两种方法都使用监督式微调来训练LLM预测最优推理轨迹。在DSPy中,这可以通过`BootstrapFewShot`等技术实现:
teleprompter = BootstrapFewShot(metric=trajectory_metric)
optimized_module = teleprompter.compile(dots_module, trainset=trainset)
通过这种训练,LLM不仅学会了如何解决问题,还学会了如何为每个问题选择最佳的推理策略。这大大增强了LLM的动态推理能力和问题解决效率。
为了验证DOTS方法的有效性,研究团队设计了一系列全面的实验,涵盖了多个推理任务和不同的评估场景。这些实验不仅展示了DOTS方法的强大性能,还揭示了其在各种复杂推理任务中的适应性和灵活性。
4.1 实验设置
实验涉及的主要内容包括:
1. 评估数据集:
- 领域内(In-Distribution):MATH数据集
- 少量样本(Few-shot):BBH(Big-Bench Hard)、Game of 24、TheoremQA
- 领域外(Out-of-Distribution):DeepMind Math、MMLU-pro、StrategyQA、DROP
2. 评估设置:
- 领域内:评估模型在类似于训练数据的问题上的表现
- 少量样本:测试模型从少量标记数据中学习的能力
- 领域外:评估模型在未见过的任务类型上的泛化能力
3. 基线方法:
- 思维链(CoT)
- 最少到最多(LTM)
- PromptAgent(PA)
- 程序思维(PoT)
- 自我完善(Self-refine)
- 传统监督微调(Vanilla SFT)
4. 实验模型:
- GPT-4o-mini
- Llama-3-70B-Instruct
- Llama-3-8B-Instruct
4.2 实验结果

4.2.1 领域内任务表现
在MATH数据集上,DOTS方法显著优于所有基线方法:
- 使用Llama-3-70B-Instruct时,DOTS达到57.7%的准确率,比最好的基线方法提高了1.8个百分点。
- 使用GPT-4o-mini时,DOTS达到75.4%的准确率,比最好的基线方法提高了1.7个百分点。
这些结果表明,DOTS方法能够有效地利用训练数据,学习到更优的推理策略,从而在领域内任务中取得显著的性能提升。
4.2.2 少量样本学习表现
在少量样本学习场景中,DOTS同样展现出了卓越的性能:
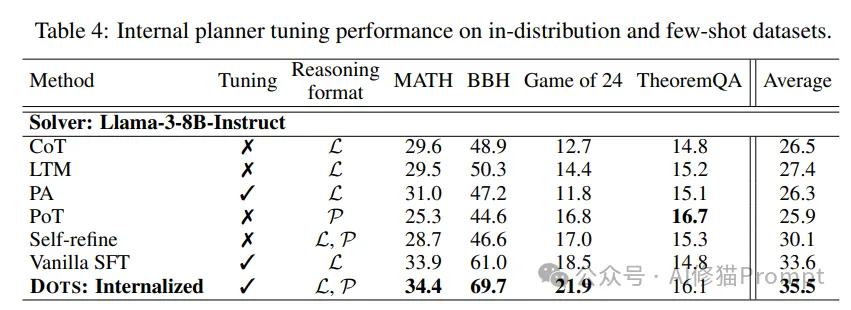
- 在BBH数据集上,DOTS使用Llama-3-70B-Instruct和GPT-4o-mini分别达到77.3%和84.2%的准确率,相比最佳基线方法分别提升了3.5和3.1个百分点。
- 在Game of 24和TheoremQA任务上,DOTS也显示出了与最佳静态方法相当或略优的表现。
这些结果证明了DOTS方法具有强大的快速适应能力,即便只有少量训练样本,也能有效学习并应用最优推理策略。
4.2.3 领域外泛化能力
在领域外任务中,DOTS方法展现出了优秀的泛化能力:
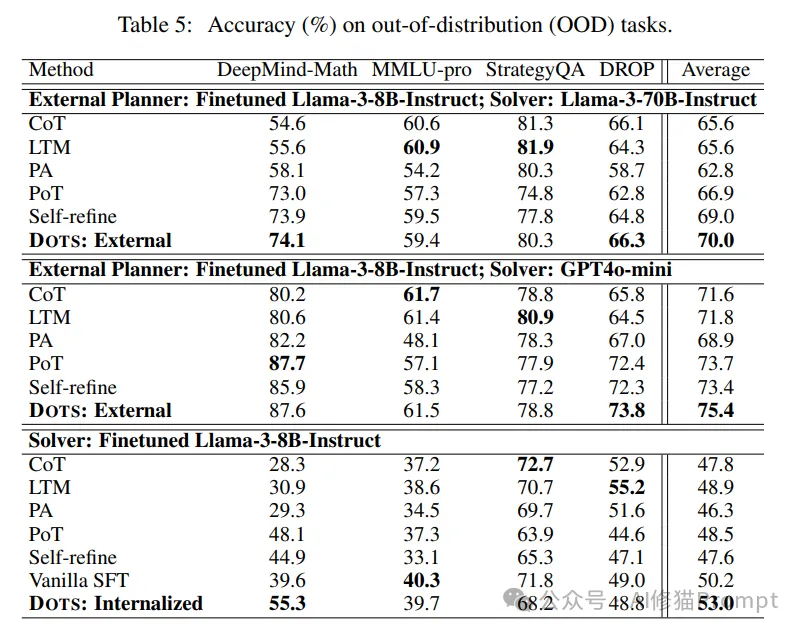
- 在DeepMind Math数据集上,DOTS使用Llama-3-70B-Instruct和GPT-4o-mini分别达到74.1%和87.6%的准确率,显著优于其他方法。
- 在MMLU-pro、StrategyQA和DROP等diverse任务上,DOTS也保持了稳定的高性能,展现出了强大的跨任务适应能力。
这些结果表明,DOTS方法学习到的动态推理能力不仅限于特定领域,还能有效地迁移到未见过的任务类型上。
4.3 与其他方法的对比分析
通过对比分析,我们可以看出DOTS方法相对于其他基线方法的优势:
1. 灵活性:与CoT、PoT等固定推理策略相比,DOTS能够根据问题特性动态选择最优推理路径。
2. 效率:相比Self-refine等方法,DOTS通过优化推理轨迹,减少了不必要的计算步骤,提高了推理效率。
3. 适应性:与PA等方法相比,DOTS不仅能适应不同的问题类型,还能根据使用的LLM模型特性调整策略。
4. 泛化能力:DOTS在领域外任务上的优秀表现,证明了其学习到的动态推理能力具有更强的泛化性。
5. 少样本学习:在少量样本场景下,DOTS仍能有效学习并应用最优推理策略,显示出强大的学习效率。
5.1 DOTS方法的优势与创新点
通过对实验结果的深入分析,我们可以总结出DOTS方法的几个关键优势和创新点:
1. 动态适应性:DOTS能够根据问题特征和模型能力动态选择最优推理策略,这是其最显著的创新。这种适应性使得DOTS在处理多样化问题时表现出色,无论是数学推理、逻辑分析还是常识推理。
2. 效率优化:通过搜索最优推理轨迹,DOTS有效减少了不必要的计算步骤。实验显示,DOTS平均消耗的输出token数少于其他高级提示方法,仅多于简单的CoT方法。
3. 强大的泛化能力:DOTS在领域外任务中的优秀表现证明了其学习到的动态推理能力具有良好的迁移性。这对于构建通用AI系统具有重要意义。
4. 灵活的实现方式:DOTS提供了外部规划器和内部规划器两种训练模式,适应不同类型的LLM和应用场景。这种灵活性使得DOTS可以广泛应用于各种AI系统中。
5. 自适应计算深度:研究发现,DOTS能够自动为更困难的问题分配更长的推理轨迹。这种自适应行为是通过探索和学习自然形成的,无需显式的专家指导。
5.2 潜在的应用场景
DOTS方法的这些优势使其在多个领域具有广阔的应用前景:
1. 教育AI:DOTS可用于开发智能辅导系统,根据学生的问题特点和难度动态调整解答策略。
2. 科学研究辅助:在复杂的科学问题解决中,DOTS可以协助研究人员选择最优的问题分解和解决路径。
3. 自动化编程:DOTS可以增强代码生成AI的能力,根据编程任务的特性选择最合适的编码策略。
4. 医疗诊断支持:在医疗AI中,DOTS可以帮助系统根据病例特点动态选择最佳的诊断推理路径。
5. 金融分析:在复杂的金融模型和风险评估中,DOTS可以提供更灵活和精确的分析策略。
6. 智能客服:DOTS可以提升智能客服系统的问题解决能力,根据用户查询的复杂度动态调整回答策略。
为了帮助AI产品开发者和Prompt工程师们快速上手DOTS方法,我为您写了一个使用DSPy框架实现DOTS的实践指南。
6.1 DSPy框架简介
DSPy是一个强大的Python库,专为开发和优化大型语言模型的提示策略而设计。它提供了一系列工具和抽象,使得实现复杂的提示工程变得简单而直观。在DOTS的实现中,DSPy扮演了关键角色,特别是在定义原子推理动作、组合这些动作、以及优化推理轨迹方面。除了以下这些,在我的公众号里搜一下DSPy
6.2 实现要点和注意事项
1. 模块化设计:使用DSPy的`Signature`和`Module`类来定义原子推理动作和DOTS模块,这样可以方便地组合和扩展不同的推理策略。
2. 动态轨迹选择:在`DOTS`类的`forward`方法中实现动态推理轨迹选择逻辑。这是DOTS方法的核心,需要根据具体任务和模型特性进行设计。
3. 轨迹优化:使用`BootstrapFewShot`来优化DOTS模块,这将自动搜索和学习最优的推理轨迹。
4. 评估指标:设计合适的评估指标(`evaluation_metric`)来指导轨迹优化过程。这个指标很灵活,应该能够平衡解决方案的正确性和推理过程的效率。
5. 错误处理:在推理过程中加入适当的错误处理机制,例如在验证失败时重新尝试其他推理路径。
6. 灵活性:保持代码的灵活性,以便轻松添加新的推理动作或修改现有动作。
7. 性能监控:在实际应用中,添加性能监控和日志记录功能,以便分析和改进DOTS的表现。
8. 资源管理:注意控制推理深度和计算资源使用,特别是在处理复杂问题时。
通过遵循这些指南和示例代码,开发者可以快速实现DOTS方法,并将其应用到各种复杂的推理任务中。随着实践经验的积累,可以进一步优化和定制DOTS,以适应特定的应用场景和需求。
DOTS方法的提出和实现标志着LLM推理能力研究的一个重要里程碑。通过动态选择最优推理轨迹,DOTS不仅提高了LLM在各类推理任务中的表现,还为构建更智能、更灵活的AI系统提供了一种可能性。DSPy也是一种非常灵活的LLM框架,在24Game的DSPy运行结果中,我输出了优化后的模块结构,您可以OCR作为一个DOTSGame24模块直接嵌入别的AI应用程序。
文章来自于微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
