# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让 AI 与人类价值观对齐一直都是 AI 领域的一大重要且热门的研究课题,甚至很可能是 OpenAI 高层分裂的一大重要原因 ——CEO 萨姆・奥特曼似乎更倾向于更快实现 AI 商业化,而以伊尔亚・苏茨克维(Ilya Sutskever)为代表的一些研究者则更倾向于先保证 AI 安全。
但人类真的能让 AI 与自己对齐吗?近日,来自麻省理工学院、加州大学伯克利分校、伦敦大学学院、剑桥大学的一个四人团队研究发现,人类尚且难以对齐,也就更难以让 AI 与自己对齐了。他们批判性地审视了当前 AI 对齐研究的缺陷,另外他们也展示了一些替代方案。

这篇论文的一作 Tan Zhi-Xuan 在 X 上称这项研究耗时近 2 年时间,其表示这既是一份批判性评论,也是一份研究议程。「在其中,我们根据 4 个偏好论题描述了偏好在 AI 对齐中的作用。然后,我们强调了它们的局限性,并提出了值得进一步研究的替代方案。」

哲学家 Nora Belrose 总结了这篇论文中一些有趣的结论:

该团队首先提出,「人类价值观」这个术语其实没有清晰明确的定义,因此就很难对其进行量化,从而让机器对齐。
目前,定义「价值」的一种主要方法是基于人类偏好,这种方法源自利用理性选择理论、统计决策理论的传统及其对人工智能中的自动决策和强化学习的影响。
无论是明确采用,还是以「奖励」或「效用」的形式隐含地假设,这种基于偏好的方法已经成为人工智能对齐的理论和实践的主导方法。
但是,就连该方法的支持者也指出,在对齐 AI 与人类偏好方面存在诸多技术和哲学难题,包括社会选择、反社会偏好、偏好变化以及难以从人类行为中推断偏好。
这项研究认为,要想真正解决这些难题,就不能仅仅基于本体论、认识论或规范性理论来看待人类偏好。借用福利哲学中的一个术语,该团队将这些对 AI 对齐的描述形式表述成了一种范围宽广用于 AI 对齐的偏好主义(preferentist)方法。之后,基于偏好在决策中的作用,他们又将这些方法分成了四类:
这些论点都只是观点,而非一个统一的 AI 对齐理论。尽管如此,它们表达的思想是紧密关联的,并且大多数 AI 对齐方法都采用了其中 2 个或更多论点。比如逆向强化学习、基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)全都假定可通过一个奖励或效用函数来很好地建模人类偏好,并且该函数还可被进一步优化。
当然,偏好主义也有批评者。多年来人们一直在争论上述论点是否合理。即便如此,偏好主义仍旧是实践中的主导方法。
因此,该团队表示:「我们相信有必要确定偏好主义方法的描述性和规范性承诺,明确说明其局限性,并描述可供进一步研究的概念和技术替代方案。」
下面我们将简要总结该论文梳理的观点和替代方案,详细描述请参阅原论文。
理性选择理论的核心原则是:假设人类的行为是为了尽可能地满足自己的偏好,并且个体和总体人类行为都可以用这些术语来理解。就理论前提而言,这一假设非常成功,并且还构成了现代经济学这门学科的基石,还影响了与人类行为分析有关的许多领域,包括社会学、法学和认知科学。
将揭示型偏好及其表征用作效用函数。理性选择理论最标准的形式是假设人类偏好可以表示为一个标量值的效用函数,而人类选择就可建模成选取的动作,其目标是最大化该函数的预期值。这种方法希望可以直接从人类的选择中得出其偏好,并且还可以将他们的偏好程度表示为标量值。这样的偏好被称为揭示型偏好(revealed preferences),因为它们会在人类选择过程中逐步揭示出来。这些方法有众多定理支持。这些定理表明,任何遵循某些「理性公理」的结果偏好排序都可以用效用函数来表示,例如著名的冯・诺依曼 - 摩根斯坦(VNM)效用定理。
机器学习中的理性选择理论。根据理性选择理论,许多机器学习和 AI 系统还假设人类偏好可以或多或少直接地基于人类选择得出,并且进一步用标量效用或奖励来表示这些偏好。逆向强化学习和基于人类反馈的强化学习领域尤其如此,它们假设人类的行为可以描述为(近似地)最大化随时间推移的标量奖励总和,然后尝试推断出一个能解释所观察到的行为的奖励函数。推荐系统领域也可以找到类似的假设。
带噪理性选择(noisily-rational choice)的玻尔兹曼模型。虽然这些基于偏好的人类行为模型基于理性选择理论,但值得注意的是,它们比仅仅「最大化预期效用」可能要更复杂一些。因为人类其实很复杂,并不总是在最大化效用,因此模型必然带有噪声,只能算是近似的理性选择。在机器学习和 AI 对齐领域,这种选择模型的最常见形式是玻尔兹曼理性(得名于统计力学中的玻尔兹曼分布),它假设选择 c 的概率正比于做出该选择的预期效用的指数: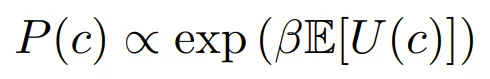 。
。
玻尔兹曼理性的论证和扩展。这种选择模型在实践和理论上都很有用。比如,通过调整「理性参数」 β(在 0 到无穷大之间),可以在完全随机选择和确定性最优选择之间调整玻尔兹曼理性。理论上,玻尔兹曼理性可作为卢斯(Luce)选择公理的一个实例,也可作为热力学启发的有限理性模型。此外,玻尔兹曼理性已扩展到建模人类行为的其它方面,除了目标导向动作之外,还包括选项之间的直接比较、显式陈述的奖励函数、整体行为策略和语言表达,从而允许从多种形式的人类反馈中推断出偏好。
玻尔兹曼理性的局限性。尽管玻尔兹曼理性可能很有用,但寻求替代方案也很重要。首先,它不是唯一直观合理的噪声理性选择模型:随机效用模型是将选择建模成最大化随机扰动效用值的结果,并被广泛用于市场营销研究。更重要的是,带噪理性不足以解释人类未能采取最佳行动的全部方式。为了准确地从人类行为中推断出人类的偏好和价值观,必需更丰富的有限理性模型。最根本的是,人类动机不能完全归结为单纯的偏好或效用函数。我们需要更丰富的人类理性模型。
这一节讨论并扩展的议题包括:
现在,问题来了:对于人类和机器行为来说,效用最大化是预期的规范标准吗?也就是说,智能体是否应该将最大化满足其偏好作为完美理性的条件,而不论其实际做得如何。
EUT(预期效用理论)的一致性论据。关于这种规范性标准的可行性,一直存在争议。支持 EUT 的论据包括前面提到的效用表示定理。该定理基于这一公理:偏好算作理性;然后证明任何遵循偏好行事的智能体的行为都必定像是在最大化预期效用。在 AI 对齐文献中,这些结果通常被视为关于理性智能体的「一致性定理(coherence theorems)」。
将 AI 对齐视为对齐预期效用最大化。基于这些论据,AI 对齐研究者传统上认为:先进 AI 系统的行为就像是在最大化预期效用。因此,很多人将对齐 AI 的问题表述为如何让预期效用最大化算法对齐的问题,并且各种提议方案都侧重于如何规避效用最大化的危险或准确学习正确的效用函数。毕竟,如果先进的 AI 系统必定遵守 EUT,那么对齐此类系统的唯一希望就是留在其范围内。此外,如果预期效用最大化是理性所需的 —— 如果智能意味着理性 —— 那么任何基于人类价值观行事的足够智能的智能体最终都必须将这些价值观整合为一个效用函数。
这一节讨论并扩展的议题包括:
如果理性选择理论不能充分描述人类的行为和价值观,而预期效用理论不能令人满意地解释理性决策,那么这对 AI 对齐的实践意味着什么?
尽管人们越来越意识到这些偏好假设的局限性,但大多数应用的 AI 对齐方法仍将对齐视为偏好匹配问题:给定一个 AI 系统,目标是确保其行为符合人类用户或开发者的偏好。
通过基于偏好匹配的奖励学习来实现对齐。目前,这类方法中最著名的莫过于 RLHF。基于用户陈述其偏好的数据集,RLHF 会学习估计用户假设存在的奖励函数(奖励模型)。然后,AI 系统会学习继续优化学习得到的奖励模型,目标是得到更符合用户偏好的行为。RLHF 最早是为经典控制问题开发的,但现在已经被用于训练越来越复杂的 AI 系统,包括用于机器人控制的深度神经网络和大型语言模型(LLM)。其中后者更是凭借其强大的能力和通用性为 RLHF 吸睛无数。
奖励学习的根本局限性。RLHF 尽管成功,但仍面临着许多技术难题,包括偏好引出问题和可扩展监督问题、过度优化问题、稳定训练问题。不仅 RLHF ,所以奖励学习方法都存在问题,包括前述的表征限制问题和采用预期效用理论的问题。
奖励学习和偏好匹配的范围有限。为了解决这些局限性,还需要怎样的 AI 对齐研究?该团队表示:「我们并不是说基于奖励的模型永远不合适。相反,我们认为基于奖励的对齐(以及更广义的偏好匹配)仅适用于有足够本地用途和范围的 AI 系统。」也就是说,它仅适用于价值对齐问题的最狭隘和最简化版本,其中的价值和范式可以总结为特定于该系统范围的奖励函数。AI 对齐还需要更多:AI 系统必须了解每个人的偏好是如何动态构建的,并与产生这些偏好的底层价值观保持一致。
这一节讨论并扩展的议题包括:
在批评了基于偏好的单主体对齐概念之后,现在转向多主体对齐的问题:考虑到人类如此之多,持有的价值观也非常多,那么 AI 系统应当与其中哪些对齐呢?
偏好聚合的理论论证。这个问题的传统答案是,AI 系统应该与人类的总体偏好对齐。为什么会这样?部分原因可能是偏好效用主义伦理具有规范性的吸引力。但是,在 AI 对齐文献中,偏好聚合的论证通常更具技术性,会使用 Harsanyi 的社会聚合定理作为依据。进一步假设所有人类也都这样做,这样每个个体 i 的偏好都可以表示成对结果 x 的偏好 U_i (x)。最后,假设一致性是理性社会选择的最低要求 —— 如果所有人类都偏好某个(概率性)结果 x 而非 y,则该 AI 系统也应该更偏好 x 而非 y。那么,Harsanyi 定理表明 AI 系统的效用函数 U (x) 必定是单个效用函数的加权聚合:
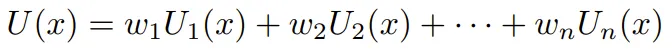
对齐实践中的偏好聚合。但是,无论这个理论观点如何具有说服力,AI 对齐实践中还是经常出现偏好聚合。RLHF 就是一个显著例证:尽管 RLHF 原本是为单个人类上下文设计的,但实践中,RLHF 总是用于从多个人类标注者收集的偏好数据集。近期有研究表明,这种实践等价于 Borda 计数投票规则。在效果上,每位标注者的选择都会根据其在一组可能替代方案中的排名进行加权。
偏好聚合的实践、政策和基础限制。这一节将从实践、政策和基础层面对 AI 对齐中的偏好聚合进行批判性的审视。在实践层面上,该团队表示偏好聚合常常被错误解读和错误应用,这样一来,即使人们接受 Harsanyi 风格的效用聚合作为规范性理想方法,在实践中使用各种非效用聚合规则的效果通常更好。在政策层面上,该团队批评了聚合主义方法的理想化性质,他们认为,由于我们这个社会存在多样化且互有争议的价值观,因此基于协商和社会契约理论的方法在政策层面上更可行。在基础层面上,基于前面对 EUT 和偏好匹配的批评,该团队将其阐述成了对效用注意聚合的规范性的批评。
这一节讨论并扩展的议题包括:
参考链接:https://x.com/xuanalogue/status/1831044533779669136
文章来自于微信公众号“机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
