# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

图片来源:NVIDIA
很高兴能在华盛顿特区见到大家,这也是自2019年以来的第一次,自从那个可怕的疫情改变了我们的生活开始。
这里有一个很棒的节目,我在这个特别的讲话中所做的,就是给大家展示你们与我们共同完成的伟大工作,这实际上我们希望能帮助你们实现的工作,有点不同于我们正常的主题演讲,我们有平台公告,这真的在庆祝你们的工作,这真的在与公司和政府机构合作,帮助美国在人工智能领域领先,帮助民主化人工智能。
潮起时,每一艘船都将随之提升。我们的每一位员工都应享受到人工智能带来的红利,因为我们正站在新工业革命的曙光之中。
老实说,我已经做这个行业超过40年了,在这40多年里,我学会了通过我们的客户和合作伙伴的工作来间接体验生活,当那个关于人工智能的视频播放时,我会感动,我不知道你们是否也是,听到其有巨大潜力的消息真让人振奋。说实话,这不仅仅只是关于人工智能,而是关于你们如何使用人工智能,因此,我为那些比我聪明得多的人感到骄傲,他们使用这些工具帮助改善人类、改善我们的星球。
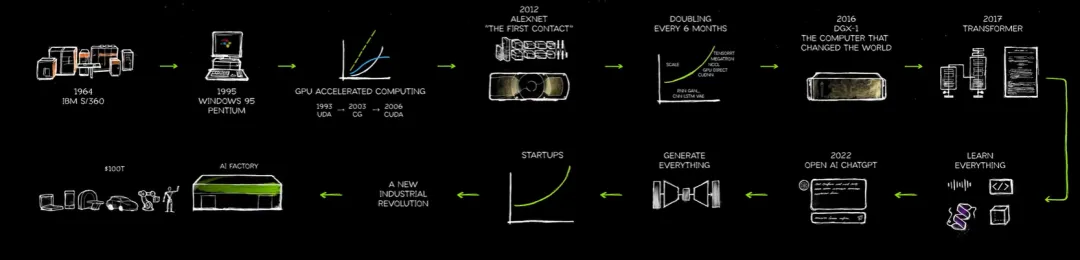
Jason画了这个,他实际上是个很好的艺术家,让我们回顾一下NVIDIA是如何走到这一时刻的,我们正处于当前时代最大的计算转型中,六十年前,IBM革新了计算,发明了CPU,他们把通用计算机放在每个公司,最终是每个家庭的手中,同样,iPhone把计算机放进了每个人的口袋,现在三星和我们的其他合作伙伴也一样,但iPhone实际上是我们第一次拥有口袋里的计算机的时刻。在过去的60年中,导致这些剧变的原因有两个力量的碰撞。一个是CPU的扩展,CPU扩展的速度无法继续维持以前的速度,摩尔定律基本上已经失效,所以,尽管我们习惯于每隔几年就获得50%的改进,但现在这种情况不再发生,这是加速计算的诞生,以便从通用计算转变。当你得到答案时,你就得到了答案,如果你和我一样长大,你会提交一堆打孔卡片,基本上打印出“Hello World”,这非常令人兴奋。
图片来源:NVIDIA
而现在我们正处于一个不同的时刻,我们正在寻找更多实时信息,更难以解决的问题,这需要加速计算,同时,CPU虽然在改善,但没有以前那么快,我们看到数据的数量在增长,不仅来自那些经常发推特的人,还有你们写的所有论文,你们执行的所有计算,我们之间往来的所有论文,所有正在进行的研究,所有这些信息智能基本上就是你们和那些数据,并且正在以指数级增长,如果你试图继续加速,但显然NVIDIA的速度也不会到达我们想象中那么快(像光速那样),如果你试图在数据指数增长的情况下进行更多计算,但你的计算基础设施无法跟上,那么你将会增加数据中心的数量,增加所需时间。而我们的一些需求在今天的世界里是更加实时的,我们只是没有足够的电力,没有足够的土地,没有足够的基础设施继续走老路。
这就是为什么NVIDIA发明了加速计算,从1993年开始,发明了用于计算机图形和游戏的芯片,当时我在硅图形公司,有一款竞争芯片,我们决定走HPC路线,将技术卖给了NVIDIA,感谢上帝,他们真的兑现了不仅仅是可视化东西的承诺,还有交互计算和可视化,计算机图形成立于1999年,我们发明了GPU并行处理器,主要用于加速计算机图形,但许多在HPC社区中的算法受益于矩阵数学、矩阵乘法、并行计算,我们在2012年第一次接触到人工智能Alexnet,那时GPU中还没有Tensor核心,研究人员发现了CUDA,并在一个人工智能用例中应用了它,在那之后,我们开始设计和思考他们需要什么来加速人工智能,加速Tensor核心,向设计中添加Tensor核心,并于2017年发布,Jason展示了首款RTX Touring处理器--首个具备图形、着色器、计算单元和Tensor核心的GPU。
其中一些可能是比你们想要的细节更多,但这些Tensor核心对加速人工智能至关重要,因为在过去的日子里,你需要64位计算来绝对确保那座建筑会建起来而不崩溃,那座桥会按预想的方式工作,那辆车的空气动力学会如预期那样运作,我们在某些情况下仍然需要,这仍然是对结构完整性和性能的良好验证。但人工智能现在不仅可以在64位下运行,还可以在32位、16位、8位、6位、4位下运行,所以Tensor核心的加入实际上让系统得到了极大的提升。
在2022年,我们迎来了ChatGPT,那是一次大爆炸,人们说,“哇,看看这能做什么,看看这能做什么。”正因为如此,我们开始思考如何改善ChatGPT的互动,如何更高效地生成那些大型语言模型,以及如何提供对这些大型语言模型的访问,这就是我们最终形成AI工厂的原因。
所以,像您在前面的幻灯片中看到的,那是一个3万亿美元的信息技术产业,这个3万亿美元的信息技术产业实际上正在推动,并且已经在推动,它将加速我们这个星球上10万亿美元产业的增长。实际上,人工智能是一个新产品,而这个产品产生的是Token,这些Token是智慧的组成部分,而智慧通常意味着金钱,你正在改善你的供应链,更快地治愈问题,优化员工生产力和员工留存率,提高客户收入,这就是一切的核心。
那么,让我们来谈谈我们是如何建立这些AI工厂的。
这实际上很久以前就开始了,当时我们在计算机图形之外研究并行化的用例,我记得自己在2009年亲自安装了第一台HPC超级计算机,在各种机架中安装了50000张PCI卡。我们这样做只是因为观察了人们试图解决的问题,开始了一项倡议,发明了CUDA来加速一些最常用的库,解决我们面临的一些最棘手的问题。我们已经在这项工作中坚持了超过20年,拥有超过900个库,4000个应用程序。
如果我们没有在2006年开始进行CUDA的工作,可能不会出现人工智能的那次大爆炸,AlexNet早在那之前就开始了CUDA的应用,这让我们感到惊讶,不仅是因为NVIDIA提供的工具,更是因为你们如何使用它,看到这些我们认为无法加速的CUDA加速算法,真是令人惊叹,现在我们能够以10倍、20倍、40倍的速度进行加速。
随着我们加速这些库,我们吸引了更多的开发者,没有人会去开发一项没有回报的东西,对吧?我们证明了加速某些痛点是有回报的,这些痛点在药物发现和新设备制造中是非常真实的,这吸引了大量新开发者和新应用,从而又吸引了大量新用户,我们继续让这些新开发者改善性能,扩大规模。当达到某个临界点时,想要使用的人数会吸引一个生态系统,吸引OEM,吸引CSP,而因为这个开放平台的广泛可用性而开始的工作形成了一个非常广泛的生态系统,你会得到更大更快的加速,我稍后会谈到这些。所以CUDA确实实现了我们所称的这种良性循环,它不仅推动了性能,也推动了智能的理解和经济的发展。
今天,正如你们所看到的,我们有超过500万开发者,且数量还在增长,你们中很多人在这个房间里,都是CUDA的用户,或者在你们的组织或机构中有CUDA,我们将继续在每个行业中看到更大的加速。我们想从你们身上学习的一个重要内容是,我们还能做些什么?最大的痛点是什么?在行业和机构中,需要解决的最重要问题是什么?这是一个非常广泛的生态系统,20年的工作,我们不会停止,我们是在为大家做这些,所以我们需要你们的反馈。我们应该更努力地去做什么?如果我们仅仅从这次会议上得到了这个,那对于我们NVIDIA所有人来说,都是好消息,能指引我们研究的方向。
如果没有我们的CUDA用户,Andys和Autom,我们不会处于这个新时代、新计算范式的黎明,因此,CUDA加速时,我们必须关注能源问题,必须关注气候,它不仅关乎加速,还证明了这是减少能源消耗的最有效方式之一。你们在这里看到的就是一个典型的CPU通用计算的例子,数据中心中有一排排的CPU,通过与CPU和GPU加速计算的这种连接,我们得到了显著的加速,正如我之前提到的。所以,把T作为某个时间元素,取它为一秒,也可以是一年,随便哪个时间元素,我们一次又一次地证明,在CPU环境下运行100个单位的时间,而在CUDA环境下平均只需一个单位的时间,提升20倍,是的,有时甚至达到200倍,但在同一单位时间内,性能提升达100倍。

图片来源:NVIDIA
你可能会认为,如果将性能提高100倍,功耗也可能会增加100倍,这是合乎逻辑的,对吧?这就是我们以前对CPU的做法,不断提升时钟频率,进行其他设计变更,但事实证明,功耗只提高了3倍,每瓦性能节省30倍,如果你能在同样的时间内完成100倍的工作,或者以千分之一的基础设施完成工作,就节省了能源。这对气候是有益的。
你可能会问,这会降低GPU的功耗吗?人们问过这个问题,那也会降低我们帮助你治愈癌症、理解飓风海伦真正影响的期望,我们不能停止寻找改善我们星球和人类的方式。性能需要继续提升,我只是想告诉你们,我们在设计系统时,不仅考虑性能,还考虑能源效率,这意味着我们将需要理解这种加速计算基础设施的数据中心,这意味着我们要从芯片层面出发,更要从全栈层面来考虑,但我们在芯片上所做的,以最大化性能和能源消耗,同时我们如何应用软件堆栈来做到这一点。
有一个例子,全球前500强绿色超级计算机中有70%是NVIDIA的计算机,它们会消耗电力吗?绝对会,但如果它们不高效,就不会在绿色名单上,它们之所以高效,是因为你们在我身后看到的那些库,这些Kodiak库对帮助提高能源效率、在同样的功率下完成更多工作至关重要。我们在每个行业中都在努力,这些是我们一些最受欢迎和使用的Kux库。
如果你是数据科学家,你要么在使用QDF来加速Spark,或者在加速Pandas、加速Polars,如果你还没有使用,这是零代码更改,真的只需添加一行代码,指明你正在进行Spark、Polars、Pandas的加速,如果你正在使用RAG,即检索增强生成,CBS是全球首个加速的语义搜索,能够加速RAG工作流150倍,我不会详细讨论检索增强生成,我知道你们中的许多人了解它,它将成为这波AI从云端转向本地制造的关键部分。
我们正在努力将制造业,特别是半导体制造,Coup Litho加速了计算光刻,应用于半导体制造,Coup Litho的运行提升了45倍,这些只是平均值,所有这些行业都一次又一次地实现了显著的改进,我们想知道缺少什么,下一个小组应该是更多的Coup,它们都致力于提高能源效率,提高获得洞察的速度,获得智能的速度。因为我们不仅在优化芯片,不再仅仅优化GPU,而是在优化整个系统,从全栈的角度来看待系统的运行、该系统运行的环境,以及运行在系统上的软件堆栈,考虑到这一点,这就是我们花费多年开发Blackwell平台的原因,所以让我们来看看Blackwell。
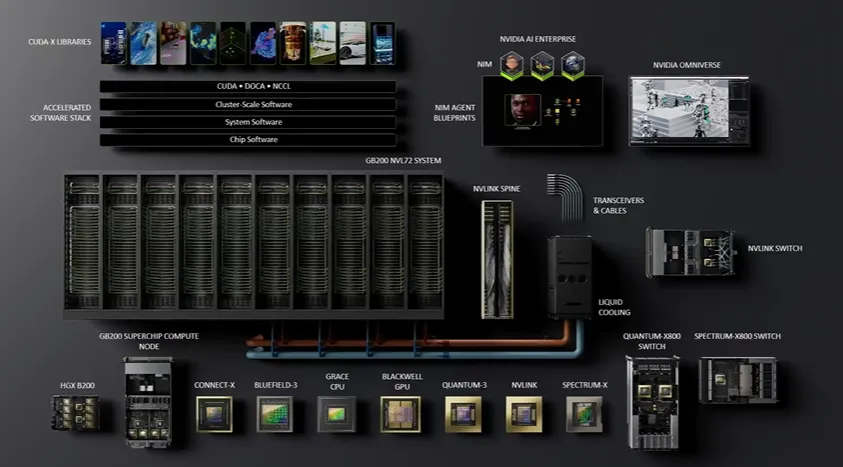
图片来源:NVIDIA
在这里的技术中,我们省略了机壳,七个不同的芯片,从GPU到CPU,再到NIS,快速连接GPU的Envy Link,专为AI计算而设计的Spectrum Max AI网络,并整合了液体冷却技术的Quantum 3。
我曾经在SDI工作,SDI收购了Cray,那时使用的不是液体,而是氟内尔特液体,必须非常小心如何冷却系统,标准液体进来的温度是45℃,退出时是65℃,65℃的热水可以用来加热散热器,供暖,所有这一切都是为了循环利用。这里的技术量真是工程奇迹,所有这些组件,我们有意建造这些计算托盘架,确保这些计算托盘架能够协同工作,而在我提到的全栈平台之上,这不是AI超级集群平台,Rail平台添加了Kodiak库,我们的软件加速库,然后为了进一步推进AI和物理AI的发展,我们有两个主要平台。
NVIDIA AI企业版,结合我们的微服务、大型语言模型,以及Omniverse,我们的数字双胞胎,在虚拟世界中改善物理世界,这就是一切的核心,培训我们的AI在物理世界中更好地存在。因此,当我们查看这些元素时,我们将继续寻找机会,不仅提升性能,还提升能源效率,因为这就是我们设计Blackwell的方式,不仅在AI上实现前所未有的性能提升,还考虑能源效率。
如果你看看这张图表,回顾过去10年,从我们的Kepler GPU到Blackwell AI超级集群,我们在过去10年中实现了能源消耗减少10万倍,这在推理方面是10万倍,而在训练方面,我们减少了2000倍的能源消耗,以此来说明100倍的提升。

图片来源:NVIDIA
你可以开一辆车开300年,每80年,你可能需要换个司机,但你可以用一箱油开那辆车300年,如果这些车设计得像我们在架构中所做的那样具有相同的能效提升,那将是一个惊人的统计数据,这个数据令人难以置信,但它是真实的,更令人难以置信的是,当我们提高能效时,如果你镜像这条曲线并查看性能增益,你会发现它超出了屏幕,因为在效率上获得100000倍的提升,导致了125000倍的性能提升,以更少的能量完成更多的工作。
人们对可持续计算的理解不够,这不仅仅关乎CUDA,也不仅仅是我们设计的方式,更关乎液体冷却,这将是我们必须帮助美国建设和重新利用的数据中心的重要组成部分,这是我们需要生产真正能够帮助美国在许多不同用例中引领AI的AI,以造福我们的公民和人类,因此,这真的是一个惊人的工程成就。
我是一个图形专家,我们以前有个叫做真实或渲染的东西,我们将不同的图片并排放置,问人们,它是实拍的还是渲染的?这不是渲染,这些都是全球各地正在搭建的Blackwell系统的真实照片。

图片来源:NVIDIA
目前有8个合作伙伴正在搭建Blackwell,我们仍计划在今年第四季度进入量产阶段,我们能做到这一点的原因是,在开发这些复杂架构的同时,团队负责建立参考设计,也就是如何将这些组件组合在一起的配方和验证点,这些参考设计使我们能够帮助所有这些合作伙伴同时搭建这些系统,这样这8个合作伙伴就能同时进入市场,你们有选择权,可以选择从哪里购买这些系统,其中许多也供应你可能会购买的其他公司,但Blackwell正在到来,已经进入生产阶段,我们的一些最大和最佳的系统将在下个季度发货。
我们不仅将继续朝着开发新GPU的方向前进,还会开发整个平台,向你展示它有多复杂,当你在这个规模上开发时,GPU很重要,CPU很重要,存储很重要,软件极为重要,但网络变得越来越重要。在AI训练中,这一点也许没那么重要。你会进行许多数据检查点,并运行数月之久,并不期望实时得到答案,但如果你有一个客户服务Agent,需要告诉某人为什么他们遇到困难,或者需要给员工一个建议,帮助改善他们在维护培训中工作的系统,那么数据访问很重要,不仅是访问的方式,还包括如何将这种访问重新打包,使AI能够做出推荐。因此,网络是这个AI工厂中最重要的元素之一,如果这些元素都是独立运作的,你只会有一堆优秀的AI任务在一起运行,但你无法轻松地将它们结合起来解决一个问题。
因此,我们将维持年度的平台节奏,在数据中心规模上进行开发,更新各种组件,包括CPU,有时是时钟修订,有时是新的CPU,GPU也是如此,NIS也是如此,但我们的承诺是继续突破极限,继续推动这一领域的发展在计算的每一个方面,我们将同时更新所有内容,我们将以一种聪明的方式进行,基于我们所看到的痛点。
这一切的美妙之处在于,你在2022年发明的软件依然可以运行,它是兼容的,向后兼容的,架构上也是兼容的,它可以正常运行,这就是为什么加速计算发展得如此之快,因为即使你获得了新的GPU或新的CPU,你也不需要重新架构,即使你获得了FPGA或不同的加速器,因此,兼容性是其核心,但我们正在构建的这个AI工厂需要新的软件堆栈,从基于指令的计算转向基于意图的计算,我告诉系统它想告诉我的或我想知道的东西,但你已经有了偏见,因为你是根据你认为想知道的内容进行编程的。因此,你所暴露的内容,你允许访问的内容都是基于指令的,对吧?我们正在从指令式计算转向基于意图的计算,这种软件必须是新的,我们必须能够与计算机交谈,提出问题。这是将推动这场工业革命的第二个部分,可能是最重要的部分。我们在这里积累了多年的技能和大量的能量,NVIDIA的开发人员中软件人员比硬件人员还要多,这正是出于这个原因,计算机不再是你用来完成任务的工具,而是现在能够生成智能、生成技能,以服务于这些行业。
有一个统计数据,到本十年末,这种加速计算AI、生成AI的方法将对已有的100万亿美元产业产生约20万亿美元的影响,因此,尽快完成这一目标至关重要,这个影响将来自于生产力提升、业务流程自动化,它将来自消费者对新AI的需求,来自于劳动力的增强和提高生产力的能力,也将来自能够以极快的速度提供解决方案的能力。
现在让我们深入了解一下我们谈论的软件,我们正处于下一次工业革命的中间,我们也正处于一个生成性AI的时代,那么,什么是生成性AI?如果我们有DHS或FBI在这里,这些不是AI Agent,而是帮助我们更好地完成工作的AI Agent。第一波AI确实围绕着这些基础模型展开,你在云中运行这些模型,运行几天几个月,基本上可以得到一个庞大的模型,回馈我们所有人故意或无意中放在互联网上的有用信息,非常有用,第一波LOMS的使用变得越来越好,越来越能够精细调整为更有用的案例。
但这始终是关于你必须知道你想问的问题,你进行提示,然后得到一个回答,而你提问的方式决定了答案的呈现方式,但如果你不知道要问什么问题呢?或者问题太宽泛,比如,我如何将客户留存率提高10%?我如何将员工的培训得分提高50%?我如何将新药、新疫苗的研发速度提升200%?
这些问题不仅需要在Ass系统中进行提示,还需要Agent。
AI Agent是NIMS的结晶。它们能够感知、推理、学习和采取行动。我们现在屏幕上有几个例子。这些AI Agent非常擅长收集大量数据,综合这些数据,从许多不同来源总结数据。更重要的是,它们能够相互协作。
让我们举一个制造车间的例子,你可能有一个库存AI Agent,持续监控你的库存,它注意到你有多余的产能,但你的车间没有充分利用这些产能,它们正在制定一个计划来生产今天的X数量的小部件,这个AI Agent可以与车间Agent进行沟通,车间Agent可以帮助加快生产,而不是提前让人们下班或其他继续生产,这又与采购AI Agent沟通,以适当的速度补充材料。你可以在几分钟内完成过去需要几天才能完成的工作,在一周的开始,你会弄清楚你真正能完成多少,然后再补充供应,弄清楚你能做多少,你可以加快每个手表、每辆车、每架飞机、每列火车、每辆汽车的制造速度。
因此,生成性AI的时代确实会改变许多不同行业。
我们已经看到一些横向应用的例子,比如数字化身用于改善我们与客户的沟通,提高员工的生产力,我们在内容生成方面也看到了一些很好的例子,无论是文本、图像还是视频。现在很多出色的工作,产品研发,不仅在医疗保健领域,我们可以使用这个AI Agent,因为它是主动的,而不是等待你提示它是否存在问题,我们可以利用这个AI Agent让你知道你有一个问题,你有一个漏洞,可能被黑客入侵,我厌倦了收到告诉我个人数据有多少在暗网的邮件,真让人难以置信,我锁定了我的信用报告已经快10年了。
关于这些AI Agent再多说一点,要记住的是,它们真的建立在我们已经研发了一段时间的软件上,这些Agent的核心是NVIDIA的Nims,这些Nims理解许多不同的模型和多种模态,包括语音、视觉、文本图像,并将这些组合成一个AI Agent,我们与多个合作伙伴合作,以确保我们整合了所有这些不同的模态和模型。
你不必使用NVIDIA的模型,你可以从Hugging Face下载,可以自己构建,或者从Meta下载,看看级别较低的公司,我们的美妙之处在于有一个Nim工厂,因此我们正在与Meta合作,我们将采用Llama 3,对其进行优化,在Nim工厂中看到的情况是,我们将每周一发布新的Nims,看到的改进是,你获得的效果比仅仅下载Llama 3.2要好2到5倍。这对Meta来说可能是有益的,但至少,有很多人正在努力确保我们提供的模型完全调优,想想过去几年我们开发的支持Tensor核心的GPU数量,这些GPU在工作站格式、服务器格式中具有不同的内存配置,连接NVLink和不连接NVLink的1、2、4、8个GPU。这不仅仅关乎模型,还关乎模型的运行方式和运行环境,这正是Nim工厂的真正意义所在,我们在多种系统上进行测试,以确保你始终获得最先进的性能,这些Nims在企业实施生产力变革中是一个不可或缺的部分。
为什么每个角落都有摄像头?就像试图躲避一个又一个摄像头,这些Nims的集合包括Nemo、Vid和Nebo,大型语言模型以及利用Nemo微调这些Nims的能力,是我们所称的AI飞轮的组成部分,改变企业为Agent、教育机构或任何你想要的形式。但Nims在我们努力优化它们的同时,也保留了它们创建时的数据,对吧?我们希望使你能够整合自己的数据,因为你不会仅仅依靠ChatGPT来优化你的供应链。你可能会使用一个更小的模型,对其进行微调,可能针对你所在的特定行业,对特定公司进行微调,因为你们有不同的语义、不同的行话。
训练AI,确保让它接触到你的公司或组织能够解释的方式,这可以减少幻觉,使其量身定制,但你仍然不能止步于此,不要回头去训练它,你必须持续让它接触新的数据、新的智能。那些数据就是智能,企业、个人,都是智能,他们撰写的论文、发送的邮件、获得的客户反馈、供应链数据库。
这应该是一个不断运行的循环,这个飞轮将继续令你惊叹于它能够预测和生成的能力,因为你并不是停留在某一时刻,你不是在询问一个几年前构建的大型语言模型的ChatGPT问题,你在询问你自己的模型,那个模型是在一夜之间优化的,你提出的问题和给出的答案有助于反馈并为下一组问题提供信息。因此,这个基于Nims的AI飞轮概念,由我们所有的合作伙伴提供,既可以在本地也可以在云端,适用于多个行业。你可能不需要记住Nims,也不需要记住Nemo,但请记住AI飞轮,记住持续改进AI的必要性,这就是我们学习的方式。
我们不会因为孩子们在5年级时学会了拼写和阅读就停止对他们的教育。我们不断地在培训他们,而且我们需要更好地培训他们。我们需要更好地在我们的教育系统和劳动力中实施这个飞轮机制,因为工具会改变,流程也会改变。因此,这段内容中最重要的一个观点是:飞轮机制是让你的AI Agents和AI模型持续更新的方式。我们已经与许多不同的软件开发人员合作,他们喜欢NIMs的概念,也理解飞轮机制以及持续用新数据来充实它的理念,但他们希望得到更多。
所以,我们很高兴地发布NIM agent blueprints。这是一种将你的数据飞轮与多个不同参考工作流连接的方式。我们不是一家应用公司,CUDA也不是一个应用,blueprints也不是应用程序。我们只是提供基于客户最常见需求的参考示例,这些需求包括客户向我们提出的最大痛点,以及我们最关心的痛点。提高客户满意度、员工满意度,推出更智能、更好、更安全的产品,帮助公司攻克一些极其可怕的疾病,保护我们的政府IP(知识产权)和个人IP,建立一个强大的AI生态系统来引领世界。
我们已经推出了用于客户服务的数字化虚拟人,这显然是一个垂直的NIM,还有产品设计。但要明确的是,这些都不是应用程序,它们是工作流。可以把它们看作是比“食谱”更丰富的东西。我甚至没有时间去做HelloFresh这样的事情,但它们有点像HelloFresh——你得到了一份食谱,拿到了原材料,如果你按照正确的步骤做了,你就能做出一顿不错的饭。但你可以加入自己的创意,比如加更多的调料,或者改变一些食材。
而且我们的意图正是让你去做这些改变,去调整这些“食材”。我们不是在告诉人们如何设计汽车,如何进行药物设计......我们只是提供一个起点,一个让他们可以根据自己的主要痛点来构建自己的AI Agents和blueprints的起点。其中一个blueprint是James。作为一个专注于真实与渲染图像的图形专家,他看起来像真人,但他并不是真实的。不过,James这个在build.nvidia.com上可用的blueprint,将向我们介绍更多关于我们所有blueprint的内容。

图片来源:NVIDIA
[播放视频]
James:你好,我是James,一个虚拟数字人。可以随时向我询问有关NVIDIA及其产品的任何问题。
用户:嗨,James,告诉我关于NVIDIA NIM agent blueprints的事情。
James:NVIDIA NIM agent blueprint提供了可定制的模板,用于将AI模型投入生产,从而简化开发者和企业的部署流程。
用户:NVIDIA AI如何提升网络安全?
James:NVIDIA AI通过加速威胁检测、改进事件响应以及实现实时威胁分析来提升网络安全
[关闭视频]
谢谢你,James。我想稍微谈一下James提到的网络安全blueprint。但首先,你可能注意到,James在思考时有两到三秒的延迟,其实比我跟很多人交流时的反应快多了。这个延迟时间对于他被问到的问题来说非常合适。你会觉得,我会这么回答X...Y...Z...不过在很多场景中,延迟时间很重要。现在你可以知道,James是经过通用训练来回答问题的。人们可以使用这些虚拟人来输入更多关于他们产品的信息,包括现有的bug、已知的问题和主要的客户投诉,这样响应时间可以缩短到毫秒级。你不会再需要在电话或电脑上等待回应。这是一种提升客户满意度和客户留存率的方式。
James也提到了网络安全。所以我非常兴奋地介绍我们最新的container。在全球交付软件的过程中,我们所有人都需要担心软件不匹配的问题。软件不匹配可能会留下一扇后门,带来漏洞。所以我们在网络安全方面使用了它,但它也可以用于软件的发布,这些发布可能会引发网络安全事件。不过,这些发布也可能只是导致蓝屏,或某些功能无法运行。所以,所有公司在软件发布过程中必须担心的问题之前可能需要分析师或人类花费数小时甚至数天去处理,而这个blueprint实现了自动化。
它包括四个不同的LLMs还有NIM,经过精细调整,将这数小时或数天的工作缩短为几分钟,确保你即将发布的软件能在目标设备上正常运行。我们也很高兴宣布,德勤已经将此blueprint纳入其“网络空间安全服务平台”。他们对开源软件进行Agent分析,专门应对我刚刚提到的问题,即在软件发布更新前,识别威胁和漏洞,在从沙盒环境转向生产环境之前做好防范。因此,一定要与德勤联系,他们在识别这些漏洞和CVE方面实现了显著的缩短时间。接下来我们可以来更详细地了解这个blueprint的实际应用。
[播放视频]
NIM agent的container security blueprint将漏洞分类处理时间从几天缩短到几秒。在人工需要手动检索、整合并分析数百个细节的情况下,Agent系统能够访问工具,并通过完整的推理链条提供即时的一键评估。这极大地提高了生产力,使安全分析师能够专注于最关键的任务,让AI处理繁重的分析工作,提供快速且可操作的洞察。
[关闭视频]
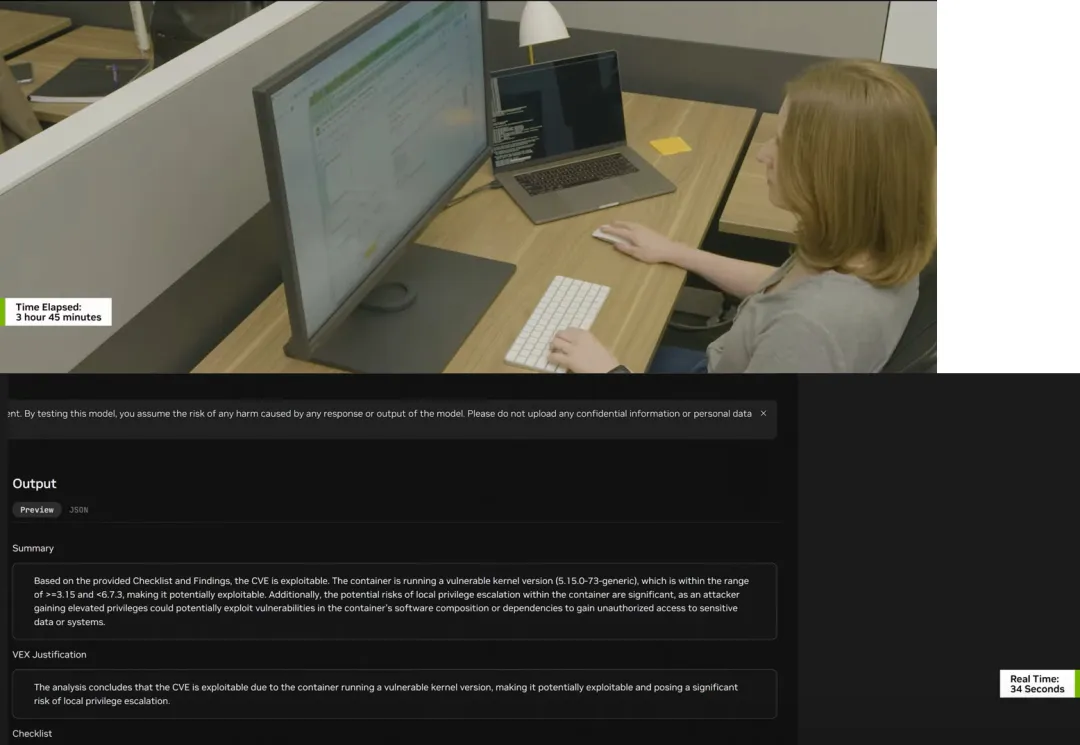
图片来源:NVIDIA
我不知道你是否注意到了,但左侧的计数器和右侧的计数器之间有两个数量级的差距,这大大加快了分析速度。你可能不需要将软件交付速度提升两个数量级,但确实有大量软件需要你以更快的速度进行分析。而这就是这个blueprint的价值所在。我鼓励你去找德勤了解,或到展台来与我们讨论这个软件和blueprint能为你带来的帮助。不过,这实际上只是你所见的更广泛生态系统的一部分。NVIDIA对网络安全进行了巨大投资,这对于公共部门来说非常重要。而我们不仅仅停留在NIM和blueprint的层面,因为这是一个全栈问题。
因此,我们在网络安全和硬件方面也进行了工作,我们通过DOCA平台实现了运行时安全,当然也包括了NIM和NeMo。最重要的功能之一是确保静态数据是加密的。当你传输数据时,它也是加密的。但LLM是纯文本的——当你训练一个LLM或一个SLM时,它是以纯文本形式存在的。你说的一切都是以纯文本形式保存的,那些知识也以纯文本形式存储。NVIDIA是唯一一家通过机密计算来保护这些LLM的供应商。这是唯一能够保护你的核心资产并提供安全和可信AI的方法。
人们可能试图攻击数据传输中的加密代码,但读取一个Word文件比读取一个加密文件要容易得多,无论加密的级别如何。NVIDIA是唯一一个在硬件中实现机密计算的平台,用来保护LLM的完整性。我们正与许多合作伙伴一起实施这些“零信任”解决方案。我们不信任任何人。我的家人可能在看,他们会想,“天哪,他们连我都不信任”。抱歉,我知道我不该说的,但我还是说了。接下来,在这样的场合,这个一个小时的特别演讲中,我们不会深入探讨细节。因此,请来展台与我们讨论,和我们的安全专家聊聊我们在网络安全方面的工作。
接下来,我只会简要提几个行业,而不是我们所有涉足的行业,我们来谈下一个行业——医疗保健行业。对我们整个人类文明来说,我想不出比这更重要的关注领域了。改善每个孩子、每个人的生活,改善残障人士的生活。帮助公司有朝一日治愈癌症。开发针对我们预知将会发生的新疾病的新疫苗。我们为此准备已久,就像我们为许多行业准备一样。我们在制造业、电信、网络安全,尤其是在医疗保健领域建立了深厚的专业知识,因为我们一直在为全球的医疗公司提供技术,其中一些公司就在那边展示。
如果你为了新牙冠做过牙齿扫描,这是由NVIDIA的GPU支持的。MRI扫描也是NVIDIA的技术。我们真正致力于改善医疗结果。虽然我们不是直接影响结果的那一方,但我们与公司合作,帮助改善这些结果。一部分工作是通过改进早期检测,另一部分则是通过改进我们为科研提供的工具。我们有像MNI这样的工具,你在屏幕上可以看到,它是AI微服务的目录,还有BioNeMo,它是一个为药物发现而设计的生成式AI平台。Parabricks用于基因组分析。全球九成的基因组学公司使用Parabricks。我们利用Inception计划来支持初创公司。那些通过Inception计划与大公司合作的初创公司,已经获得了200多项国家资助。200项来自NIH(美国国立卫生研究院)、NCI(美国国家癌症研究所)和NSF(美国国家科学基金会)。总资助金额接近3亿美元。
我们的目标是让这些公司共同进步。这不仅关乎劳动力,还关乎小企业、初创公司。这就是创新。你看到所有的船只同时上升。你不会浪费时间去把人从水里拉出来,而是推动一切一起进步。在展会上,你会看到很多医疗保健领域的工作。我们也在继续创新,并扩展这个全栈解决方案。我们还发布了两个新的NIMs,AlphaFold2-Multimer和RFdiffusion。可能你们中90%的人跟我一样,会想:“那是什么?”你可以在build.NVIDIA.com上看到这些内容。它们现在已经公开发布。
在药物发现方面,这些工具帮助确定蛋白质如何与其靶点结合。这帮助我们确定不同疾病的治疗方法。通过AlphaFold,我们能够在几分钟内准确预测这些蛋白质的结构,帮助科学家不再需要通过反复试验进入实验室。通过RFdiffusion NIM,我们能够更准确并加速设计全新的蛋白质,了解哪些结合剂是有效的,哪些药物和疫苗最有潜力。这些东西在过去几年中尤为相关。
可以看下虚拟筛选blueprint。我们从选择一种已知与某种特定疾病相关的氨基酸开始,挑选一种疾病。通过AlphaFold2,可以快速预测该氨基酸的三维结构。这是它的三维外观。接着,将其传递给MolMIM。MolMIM将帮助生成成千上万种可能用于该疾病的药物组合。然后把这些组合应用到另一个NIM上。这一切都通过DiffDock blueprint自动完成。DiffDock会预测这些分子与目标蛋白结合的可能性。你将看到分子的生成和与我们试图靶向的蛋白的结合。我们可以以比通常快六倍的速度完成,并且准确性更高。
过去,科学家和研究人员通过反复试验来进行筛选,现在这已经变成了一种高度集中的智能搜索,能够快速筛选出几千种可能的候选药物,淘汰掉不合适的候选者。这就是我们能够以更快的速度应对新疾病的方法。而且这不再需要曾认为的40年时间。我们了解了人类基因组,知道这些基因如何相互作用,可以利用AI进一步加速基于人类所已经加速的药物研发过程。AI将继续加速这些科学家和这些药物的开发进程。
还有我们一直在与ServiceNow紧密合作。我知道在场的一些机构使用了ServiceNow的发布的服务。他们一直在使用我们的NeMo和NIMS,利用生成式AI改进摘要、改进之前提到的一些客户服务应用。他们现在宣布了专门针对公共部门、电信和医疗保健的Now Assist解决方案。公共部门、电信和医疗保健。这些解决方案都基于我刚才展示的软件。它们将推向这些行业,并将继续拓展到其他行业。再次强调,一种模式并不适用于所有情况。你选择的模型、NIMs和你要操作的数据都是不同的。ServiceNow正在完成将这些元素打包在一起的繁重工作。然后,公共部门的使用实体会将相关数据提供给这些系统。因此,我很高兴宣布,ServiceNow现在正在深入到垂直行业的特定用例,而不仅仅是通过横向提升AI来提高生产力。
我们讨论了很多内容,而且非常快速地略过了很多内容。我们刚刚展示的所有内容以及更多的东西都可以在build.NVIDIA.com上找到。我鼓励你们去看看、去评估、去批评,甚至给我们一些苛刻的反馈。使用这些blueprint,你会在上面看到模型卡片,参考代码和文档。你会在GitHub上看到逐步的示例。这一切都是公开和开放的。NVIDIA不制作告诉你该做什么的应用程序。NVIDIA提供工具、参考架构和参考工作流,让你能够实现自己想做的事情。所以,请查看一下并告诉我们还缺什么,因为我们每天都会继续改进。
我不会举起双臂庆祝,但我们已经谈到了AI Agent的时代,我们已经讨论了很多关于NIM和NeMo的内容,那么接下来是什么呢?接下来的浪潮就是物理AI。
如前所述,大部分重点都放在基础模型上,集中在提示和回应,以及构建AI agents。我的一位朋友经常提到,我们认为AI将对物理世界产生最大的影响。我们需要更好的疫苗和药物,但同时我们也需要更安全的应用。那么如何进行建模?如何模拟机器人、自动驾驶汽车或任何自主车辆的运行呢?这就是一个巨大的机会。我们认为,到目前为止,我们主要影响的是IT产业,影响了电子领域。而接下来的目标是影响物理世界,即所谓的“质子”领域。
我们已经知道机器人可以帮助拯救生命,确保制造业员工的工作更加安全,甚至能够帮助残疾人士。我们还知道未来几年内将会创造约400万个新工作岗位,但我们不知道这些劳动力会从哪里来。部分工作或许可以通过机器人完成,还有一些我们希望能通过提升现有劳动力的技能来解决。
让我们先深入探讨一下物理AI。物理AI是一个“三台计算机问题”(ZP注:three computer problem,在开发和部署人工智能系统,特别是在机器人技术领域时,需要的三种不同类型的计算资源。一台计算机用于创建和训练,一台用于模拟和优化,最后一台用于运行和控制)。虽然“三体问题”在Netflix上是精彩的节目,但它并不是一个“三体问题”,如果你没有正确理解,糟糕的事情就会发生。
“三台计算机问题”更多的是我们需要确保这三台计算机协同工作。我们已经讨论了很多关于第一台计算机的事情,关于大型语言模型的创建、训练、推理,NIM Agent Bluprints。然后你会在第二台计算机中模拟这些。第二台计算机就是Omniverse。所以正如你面前所看到的,它基本上就是一个操作系统和一个开发平台。
它被用来构建和部署工业和物理AI模拟应用程序。在你推出AI之前,你想知道它将如何运作,它本质上是一个反馈环,让AI能够进入物理世界。这是有意义的,因为这是数字世界,这些AI就是在这里被创造的。所以我们在将它们释放到物理世界之前,在数字世界中测试它们。
假设我们有一台机器人。我想我们的展位上有Spot狗机器人,请去看看它。如果我们没有在看起来像真实世界的虚拟世界中训练Spot,Spot将无法正常运作;如果我们不得不在真实世界中训练Spot,我们将不得不飞遍世界各地,向他展示所有可能发生的事情。但如果我们能在虚拟世界中训练Spot呢?如果我们能在虚拟世界中训练一个机器人进行制造过程呢?在虚拟世界中训练它们。大规模地训练它们。
不是在物理世界中一次训练一个自动驾驶机器、一辆车或一个机器人。在虚拟世界中训练它们,训练数以百万计的它们。使用它们需要拥有的agentic AI知识来推理和学习。在第二台计算机中训练它们以模拟它们的运作,向它们抛出各种条件,好坏都有。当我们成功时,我们取下那个神经网络,我们把它放在第三台计算机中。我们把它放在汽车里,放在潜水器里,放在无人机里,放在人形机器人里。
所以Omniverse是我们测试和优化人们的设计以及生产这些物理AI的所有操作过程的方式。这是一个虚拟“试衣间”。人们正在基于像这样的数字孪生构建模拟,从它们被制造的设施开始,到工厂,再到在城市中运营的工厂,再到国家中的城市,到星球上的国家,最终将会超越这个范围,这些已经发生了几十年。
所以第二台计算机是Omniverse。我们已经进入了一个每个基础设施都是机器人的时代,包括我们所在的这座建筑,不是现在,因为我真的希望AI能意识到这些灯光有多刺眼。但每座建筑本质上都将是一个自主机器。我们真的相信这一点。再说一次,你不是只训练一次,而是要持续学习。如果我们要模拟建筑物、模拟机器、模拟机器人,我们必须不断地训练它们。我们在构建这方面一直很擅长,我们建立了很好的训练和推理系统。Omniverse是一个令人惊叹的产品。我本质上是一个可视化方面的专家。它让你大开眼界。但讽刺的是,这不仅仅是关于漂亮的图形。如果我们不看这些惊人的图形,它实际上是关于测试那些AI,但要让它们看到那些令人惊叹的图形,这样它们才能学会如何学习。
我们通常很擅长在数据产生的源头放置设备,无论是在摄像头还是传感器。我们在全球范围内拥有GPU和医疗设备。真正的关键是这些设备协同工作。就像我向你们展示的企业飞轮一样,你们必须不断地加强和重新学习AI正在做什么,用你的飞轮引入新信息,模拟它,这样你就能了解它在你希望它部署的环境中将如何反应,然后真正地在边缘部署它。那个边缘可以采取多种形态。这就是我们必须完善的,这就是为什么我们说这是一个涉及三台计算机的问题。
并不是说它是一个难题,但它确实是一个需要三台计算机有效协同工作的问题或者机遇。有很多例子说明人们正在以这种方式构建数字孪生。你在幻灯片上看到的宝马公司利用这些技术来改善物流。大陆集团则利用它们来提高预测分析能力以及他们所生产产品的性能。梅赛德斯-奔驰,改善装配线。富士康是世界上最大的电子制造商。他们正在训练AI机器人臂和自主机器在真实世界情况下执行任务,这些任务需要极其精确。这是电子制造,是我们在做的最大胆创新的事情之一。为了让我们更了解一些,请允许我引入一个朋友。告诉我们关于Omniverse的情况。

来源:NVIDIA
[播放视频]
随着世界将传统数据中心现代化为生成式AI工厂,对NVIDIA加速计算的需求正在飙升。全球最大的电子制造商富士康,正通过构建使用NVIDIA Omniverse和AI的机器人工厂来满足这一需求。工厂规划者使用Omniverse整合来自行业领先应用的设施和设备数据,如西门子Teamcenter X和Autodesk Revit。
在数字孪生中,他们优化楼层布局和生产线配置,并确定最佳的摄像头位置,以便使用由NVIDIA Metropolis驱动的视觉AI监控未来操作。虚拟集成为规划者节省了物理变更订单的巨大成本。在建设期间,富士康团队使用数字孪生作为真实的来源,以沟通和验证准确的设备布局。
Omniverse数字孪生也是机器人“健身房”,富士康开发者在其中训练和测试NVIDIA Isaac AI应用程序,用于机器人感知和操纵,以及Metropolis AI应用程序,用于传感器融合。在Omniverse中,富士康在将运行时部署到Jetson计算机之前,模拟两种机器人AI。在装配线上,他们模拟Isaac操纵器库和AI模型,用于自动光学检查,进行目标识别、缺陷检测和轨迹规划。
为了将HGX系统转移到测试舱,他们模拟了由Isaac Perceptor驱动的Ferrobot AMR,因为它们感知并移动其环境,进行3D映射和重建。通过Omniverse,富士康建立了他们的机器人工厂,协调在NVIDIA Isaac上运行的机器人,建造NVIDIA AI超级计算机,这些计算机反过来训练富士康的机器人。
[视频结束]
一个很好的同时探讨数字孪生的好处和三计算机问题的例子就是那些机器人不断进化以改进物理AI。而其中最具挑战性的事情之一,至少我见过的,就是我们在机场见过送饮料的机器人,但在那种环境下,它必须是完美的。在制造汽车时,它必须是完美的。所以这种训练循环中使用Omniverse是很重要的。
我们也非常高兴地宣布与MITRE公司的合作。这是一个政府赞助的,非盈利的研究。MITRE和密歇根大学的Mcity设施,一个自动驾驶车辆测试设施,他们将开发并将物理测试AV平台与MITRE的虚拟数字孪生AV测试平台结合起来。所以,研究人员和开发者可以一次性地训练、测试和验证这些自主机器、机器人、仿人机器人的一切。我真的很高兴看到他们聚在一起,期待着惊人的结果。
接下来到数字工厂,全球运作的物理AI。我们也可以利用物理AI来分析我们的沟通方式,现实世界的无线电网络,5G、6G。我们现在使用NVIDIA Aerial RAN来改善传输、塔的位置和这些网络的存在方式的利用率。一年前或两年前,我们会谈论塔的位置,你不希望是那种“你现在能听到我吗”的情况。
这也是一个三计算机问题,无论是在塔的位置,还是在实现5G和6G承诺的能力上。我们有像爱立信这样的合作伙伴,他们正在为5G部署构建数字孪生。伟大的工作。Ansys正在模拟电磁负求解器,帮助所有这些公司弄清楚干扰效应。你在屏幕上看到的T-Mobile和SoftBank正在构建新的AI加速无线电接入网络解决方案。当你在下一个屏幕上看到RAN时,这确实是一个三计算机问题。而那个边缘计算机是实现这一点的最关键事情之一。所以,我们想发布我们的NVIDIA Aerial RAN计算机。这是第一个共同的平台,不仅仅是为了AI而做RAN,而是用AI做RAN。
大多数网络都是基于为特定目的构建的基础,它们只做一件事。它们试图加速并消除噪音,通过5G传递信号。这对我们作为一个社区很重要,但对紧急响应和保护我们公民的人来说也很重要,这确保我们没有差距。那些网络现在的利用率大约是30%。30%的利用率是因为它们基本上只关注网络的频谱效率。这是第一个再次加速RAN、为RAN提供AI、提高效率并使RAN能够传递AI的平台。它使电信公司和整个电信行业能够在边缘提供AI服务。更有趣的消费者体验,XR、VR体验,利用并准备6G,帮助我们规划6G需要是什么。
有了Aerial RAN,我们将基本上拥有这个聚合的通信网络,一个分布式网格,可以让人们容易地确定最佳的交付体验地点,无论是XR体验还是AI Agent。但我们不应低估将利用率从30%提高到更大数值的价值。那是实实在在的钱。对电信行业来说是实实在在的钱。他们都非常喜欢这个,并很高兴地宣布我们已经有很多Aerial RAN计算机的采用者,用于这个庞大的电信行业。再稍微谈谈Omniverse,然后我们就结束。我们已经从工厂和在这些工厂上运行的机器人,转到了我们世界中的沟通方式。
我们之前在其他会议上已经谈了很多关于人们如何使用Omniverse来更好地对抗野火,更好地预测气候。例如,Lockheed Martin公司的太空和地球轨道数字孪生。The Weather公司有一个全新的、非常高分辨率的、使用Omniverse的天气预测系统。所有这些都是为了让气候研究人员和公司改进服务并帮助保护我们的公民。NVIDIA自己也一直在构建一个地球的数字孪生来助力于此。Spaceverse几年前找到我们,他们要求我们帮助构建一个宇宙的数字孪生,这是可能的。我并不是在贬低太空项目的任何人,因为我想从事那个项目。
但你得从某个地方开始。你需要从事情完成的地方开始,从人们工作的地方开始,从人们的沟通方式开始,从你想要解决的问题开始、从一个星球开始,从围绕我们星球运行的事物开始,然后随着我们对我们的宇宙了解得越来越多,你就超越了这些。但是研究我们的星球,就像医疗保健一样,极其重要。
建造Earth-2的这项工作,是人类曾经承担过的最大的挑战之一——我们星球的物理精确数字孪生。今天,我们主要用它来应对气候,我们有很多例子。我不会在这里详细说明,但我会在这个很酷的视频中涵盖它们。让我们来播放这个视频。

图片来源:NVIDIA
[播放视频]
NVIDIA Earth-2是一个气候专家可以在这里从多个来源导入数据,将它们融合在一起,使用NVIDIA Omniverse进行分析的平台。这里,NOAA GO卫星的图像显示了2024年9月21日在海湾形成的飓风海伦。在地球的另一个地方,2024年8月在希腊上空,我们可以看到如何将行星实验室的地形数据与极光科技的红外探测热信息融合在一起。这种不同类型的传感器的结合视角对于野火的探测和缓解非常有洞察力。NVIDIA Earth-2汇集了模拟、AI和可视化的力量,赋能气候技术生态系统。
[视频结束]
我想多谈谈飓风海伦。我们做得不够好。这就谈到了我们仍然需要做的工作。我们提到了能够引入多种传感器数据的能力。Earth-2可以部署来自传感器和地面传感器的各种观测数据,以及来自天气模型等人的反馈和知识。我们向你们展示的只是飓风海伦正在形成。下次我想向你们展示我们应该如何描绘它,回顾过去,看看我们的天气模型哪里出了问题,训练AI不仅要找出它们可能在哪里出了问题,不仅仅是停在海岸线上,而是要找出内陆的影响。
我们在构建这些大部分准确的天气模型方面做得非常好,但我们面临的条件正在变化。随着预测模型中变量的变化,我们需要知道它们在变化。我们可以查看世界上所有飓风的历史,但在每一个飓风中,都发生了一些微妙的差异。我们需要所有这些传感器来帮助AI告诉我们,这一个可能有所不同,这一个不是在几周前从非洲海岸线出发,这一个可能因为这些原因而走不同的路径,至少给我们更多的时间。
我们想利用Earth-2来帮助推动气候科学、气候改善,构建作为AI审问者和AI模拟器的地理空间系统,当我们引入新事物时,随着世界继续产生二氧化碳等。这是一个雄心勃勃的任务,与一些伟大的合作伙伴合作,我们很乐意在我们的展位上更多地谈论它。有很多正在进行的工作,向内看,看我们的星球,这很酷。当我还是个小孩子的时候,我想成为一名宇航员。我最终设计了飞机,所以我接近了。我想成为一名宇航员,因为我无法理解银河系在哪里结束,宇宙在哪里结束。是不是在Horton的指甲下?一定有更多的东西。
我们一直在努力弄清楚前方是什么。像NASA的Lucy项目这样的事物正在帮助人们模拟通信,以便如果我们在月球上建立操作,我们寻找盲区,我们希望不落下任何人,我们希望确保我们覆盖了月球的暗面。如果你愿意的话,我们可以在Omniverse中模拟它,以便在我们到达那里时可以构建正确的东西。我们有James Webb观测望远镜,以前天文学家需要10年时间来调查我们的银河系,我们现在可以在几天内完成,使用AI加速版本的它。
CERN正在使用它来观察我们银河系每天发生的质子碰撞。然后就是SETI。今天,我们宣布SETI发布了他们对快速射电暴的首次实时搜索。那么什么是快速射电暴?SETI的使命是致力于寻找宇宙中的生命。他们使用我们的HoloScan平台,那个第三台计算机。他们使用那第三台计算机来监听来自深空的信号。快速射电暴就是这些信号之一,但它们发生得非常快。它们发生在毫秒的分数,秒的分数。所以他们知道它们发生的唯一方式是他们回到这个存储的望远镜阵列数据。他们看到它发生了,但它已经消失了。
我们真的不知道它来自哪里。所以实时发现这些东西的能力真的加速了我们找到源头、识别源头、分析这些频率的能力。你可以假设这些频率可能是什么,但关于它们的惊人之处不在于它们是来自遥远星系的无线电频率,而在于来自这些遥远星系的能量比我们宇宙中的一些星系还要亮。毫秒的快速射电暴产生的能量超过了我们一些星系产生的能量。所以作为一个太空人,我真的很兴奋。
那又怎样?这是一个巨大的应用,帮助我们不仅了解我们的星球,还了解可能存在的东西。当我们超越火星,超越月球,超越火星,进一步向外探索时,可能存在的东西。我真的很高兴与他们的伟大合作,继续探索太空。
这是我最喜欢的幻灯片,这也可能是最无聊的幻灯片,但这是最重要的幻灯片。我们在华盛顿特区与政策制定者交谈,不是像这样进行演讲,而是与政策制定者交谈,与公司交谈,与集成商交谈。我们希望确保我们与州和地方机构合作,我们与高等教育机构合作,我们与学习社区合作,也许是明显服务不足的学习社区。如果AI只帮助少数人,我们将犯下不公正的错误。我之前说过,潮水涨起时,所有的船都会上升。我们必须提高所有的船。其中一些将因为AI将改善你们的生活,你们查找信息的便利性,你们工作的便利性,使事情更成功而发生。
但我们也希望人们从理解数据科学、理解量子计算、了解如何成为这些AI工厂的系统管理员中受益。我们正在全球范围内开展培训。我们已经培训了超过60万人。当我们现在说话时,更多的人正在培训中。这是我们能做的最重要的事情之一。如果你没有一个与我们合作的培训计划,如果你是一个市政当局,一个机构或一个高等教育机构,我会鼓励你来和我聊聊。这是我们使命的一部分。主题演讲结束后,Greg Estes将在沙龙E进行一次关于我们认为需要的工人升级和再培训的演讲,以继续推动在新的工业革命黎明时期的经济发展。非常非常重要的活动。我真的鼓励你们与我们交谈。
我们说了什么?我们谈论了CUDA的良性循环。我们谈论了加速计算如何推动了这么多事情的发展,CUDA如何成为这个巨大的开放生态系统。我们谈论了需要以不同的方式看待计算,不仅仅是在芯片层面,不仅仅是在结点层面,而是在数据规模中心层面,关于构建AI工厂,这些AI工厂生产产品。这些AI工厂生产的产品就是token。Token 代表智能,而智能可以转化为收益,这将彻底改变这个世界上的各个行业。我们在华盛顿哥伦比亚特区,因为我们希望帮助美国在AI方面领先,在AI的每一个方面。
我们需要帮助美国在AI方面领先。我们有责任确保我们的公民从AI中受益。所以,请与我们合作。请来找我们谈谈AI的民主化,就像60年前通用计算被民主化一样。请与我们合作,为我们明天的劳动力升级技能。与我们谈论接下来可能发生的事情。有这么多可能性。你们最大的痛点在哪里?我们能在哪里提供帮助?别忘了博览会,90个合作伙伴,30多个初创企业都在那里谈论通用AI、Agent AI、机器人等。顺便来我们的展位看看。别忘了Spot机器狗,来和我们的数字人James交谈,来获得Earth-2的demo。
感谢你们所有人的到来。感谢你们的倾听。
原视频:The Transformative Power of Accelerated Computing and AI
https://www.youtube.com/watch?v=isVTulzTdFs
编译:Ying Meng,Yuxin Chen
文章来自于微信公众号“Z Potentials”,作者“Bob Pette”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
