# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让大模型依靠群体的智能。
在我们的自然界,蚂蚁、蜜蜂、蝗虫都是非常简单的生物,单独行动的它们也非常脆弱。但一旦它们组成群体,就会涌现出远超个体简单相加的力量,比如几只蚂蚁凑到一起可以往洞穴搬运食物,一群蜜蜂可以建造精密的蜂巢。这种群居性生物表现出来的智能行为被称为群体智能。

从宏观上说,人类社会的不断发展和演化也是一种群体智能现象。因此,计算机科学家们就想到,为什么不在人工智能的研究中借鉴这种思路呢?说不定,这能比 OpenAI 等公司所追求的「超级智能个体」更接近 AGI 呢?
随着大模型变得越来越聪明,越来越多的研究团队开始挖掘这一方向的潜力,比如机器之心前段时间报道的国内创业公司 RockAI(参见《与其造神,不如依靠群体的力量:这家公司走出了一条不同于 OpenAI 的 AGI 路线》)。
最近,来自谷歌、华盛顿大学的研究团队也公布了一项研究,让「群体智能」走入了更多 AI 研究者的视野。

在这篇论文中,作者提出了一种协同搜索算法 ——MODEL SWARMS,该算法通过群体智能来适应和优化大型语言模型(LLM)。具体来说,MODEL SWARMS 从一组 LLM 专家和一个效用函数开始。在跨模型找到的最佳检查点的引导下,多样化的 LLM 专家通过协作在权重空间中移动,并优化表示模型适应目标的效用函数。
与现有的模型组合方法相比,MODEL SWARMS 提供了无需微调的模型适应,可以在数据量低至 200 个样本的情况下工作,并且不需要对群体中的特定专家或它们应该如何组合做出假设。
大量实验表明,MODEL SWARMS 可以灵活地使 LLM 专家适应单一任务、多任务领域、奖励模型以及不同的人类兴趣,在不同任务和上下文中,它将超过 12 个模型组合基线提高了 21.0%。
除了努力训练一个单一的、通用的大型语言模型(LLM),在所有语言和任务中共享参数之外,最近的工作越来越多地认识到通过多 LLM 协作的模块化的重要性,其中不同的模型以各种方式相互作用和互补。例如,混合专家(MoE)依赖于将查询路由到各种神经子组件,利用一个模型的专门知识。路由到特定领域的专家这种方法显示了巨大的潜力,但在 MoE 过程中没有产生新的模型 / 专家。然而,具有挑战性的现实世界任务通常需要灵活的组合和适应新的领域的能力,超出了现有专家的范围。
有两种研究工作旨在将多 LLM 合作扩展到路由之外,以组成和产生新的适应模型:
1、Learn-to-fuse 设计可训练的组件,将专家「粘合」在一起,形成一个合并的模型,然后使用监督目标对模型进行微调,以产生组合专家。这些方法通常依赖于大型训练集从头开始微调可学习部分,并且很难提供无缝添加 / 移除专家的模块化。
2、Model arithmetic(模型算术)通过对模型权重和 / 或 token 概率进行算术运算来组合 LLM 专家。这些方法通常对可用专家和期望的适应应该如何分解有强烈的假设(例如,lion indoors = lion outdoors + (dog indoors - dog outdoors))。因此,一个不依赖于过多微调数据或对现有模型有强烈假设的灵活方法至关重要,可以让多样化的 LLM 专家适用于广泛的场景。
为了解决这一问题,作者提出了 MODEL SWARMS,在这个框架中,多个 LLM 专家通过协作在权重空间中搜索新的适应模型。受粒子群优化(Particle Swarm Optimization, PSO)的启发,MODEL SWARMS 将每个 LLM 专家视为一个「粒子」,并将 LLM 适应定义为粒子的协作移动,这种移动由表示适应目标的效用函数指导。
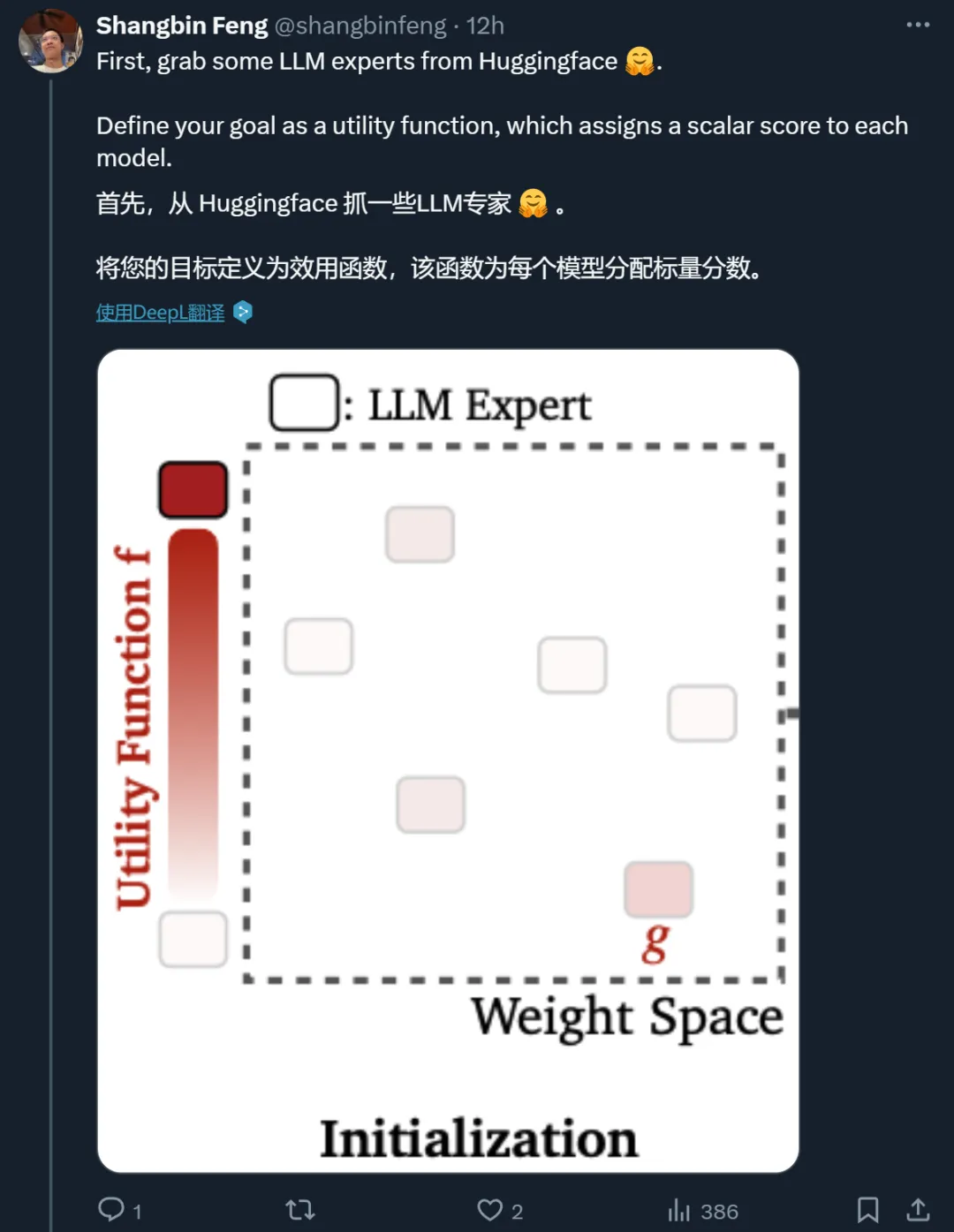
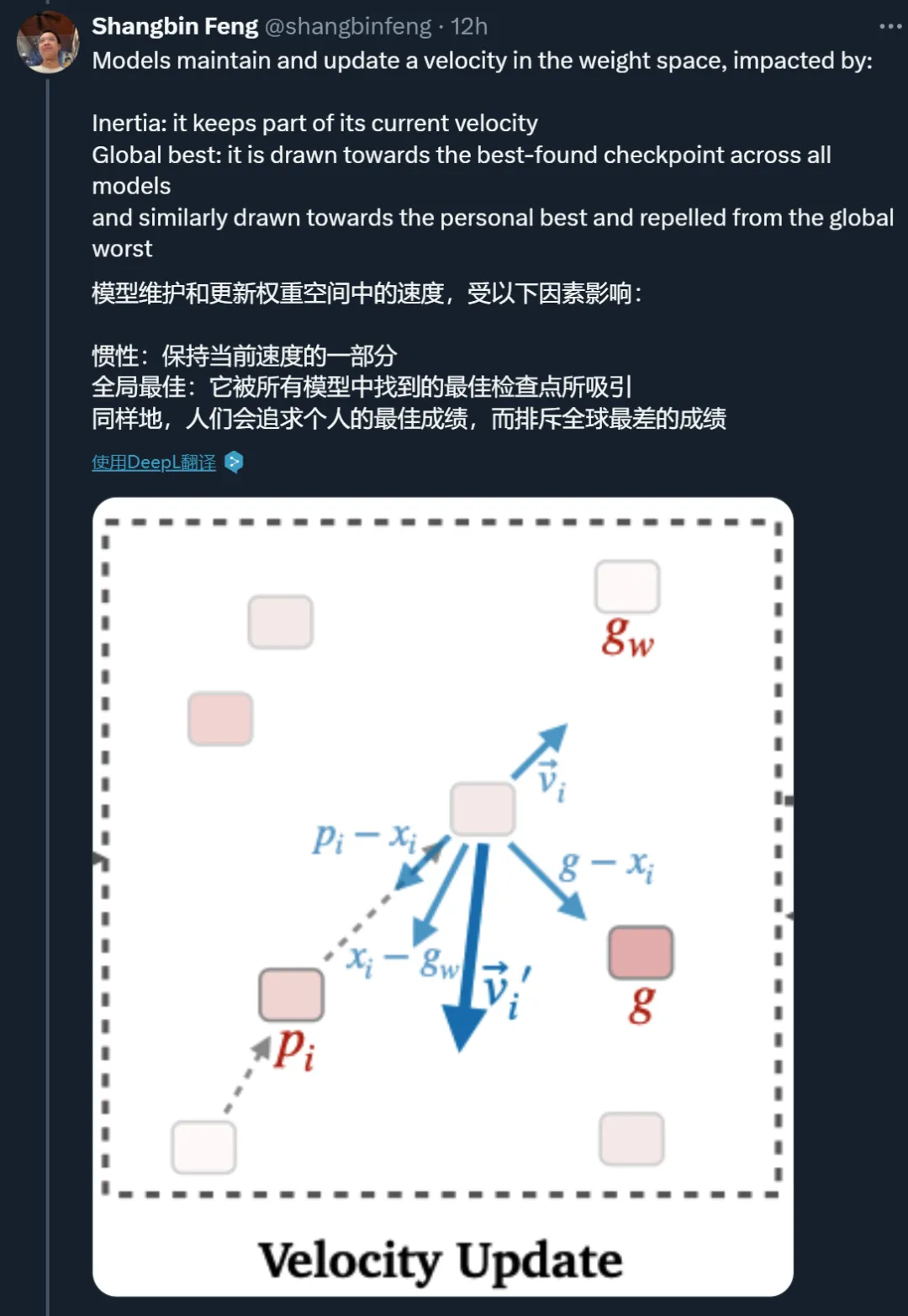
具体来说,为了建模 LLM 的主动搜索而不是被动合并,每个专家粒子都以一个位置(模型权重)和速度(权重空间中的方向)开始。速度会受到惯性(保持当前速度的倾向)、个体最佳(给定粒子找到的最佳位置)和全局最佳 / 最差(所有粒子中找到的最佳 / 最差位置)的迭代影响,而 LLM 粒子随后朝着更新的速度方向迈出一步。这些速度因素使得 LLM 粒子能够绘制出独立的搜索路径,并探索个体 / 全局最佳邻域。
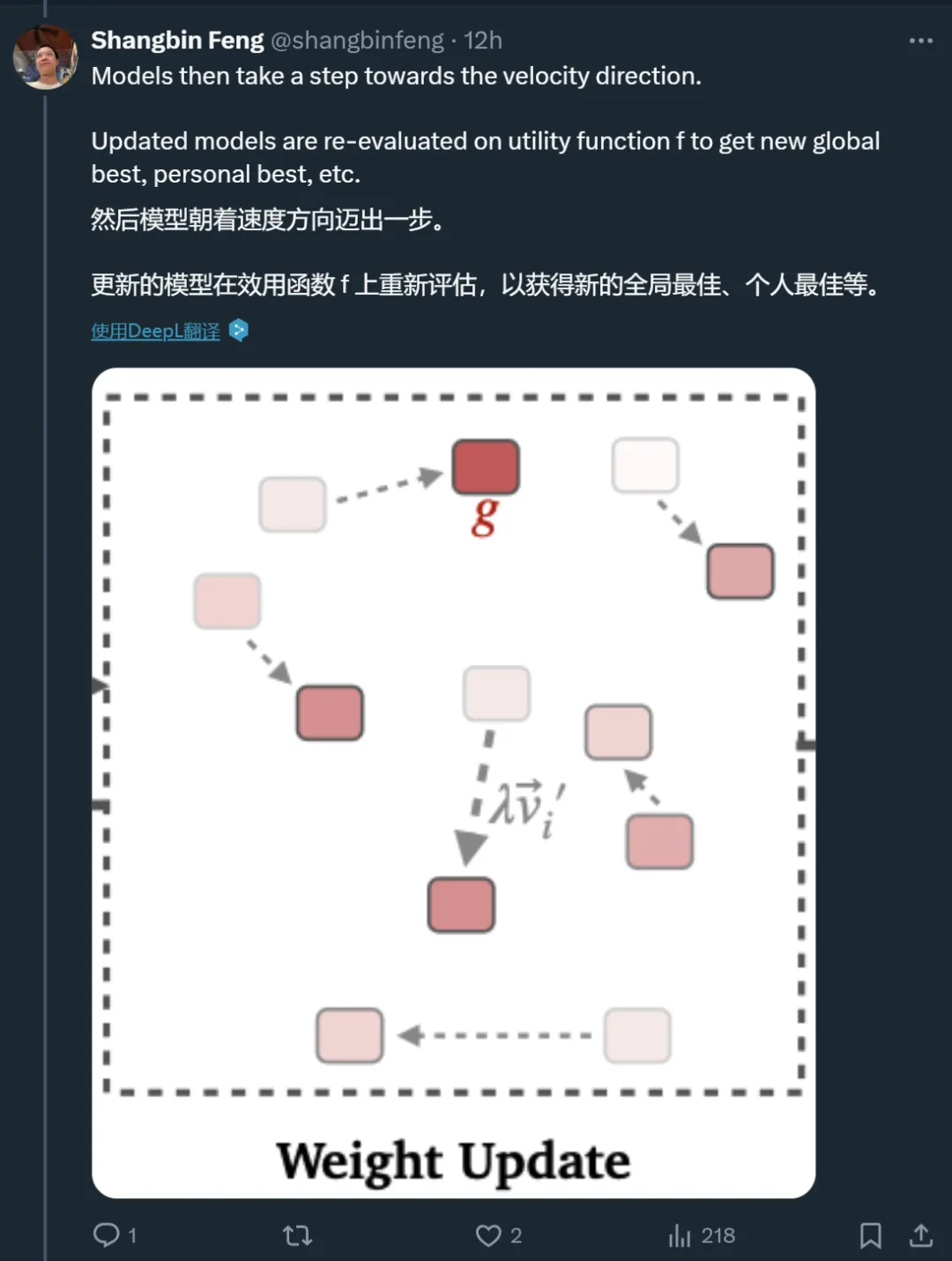
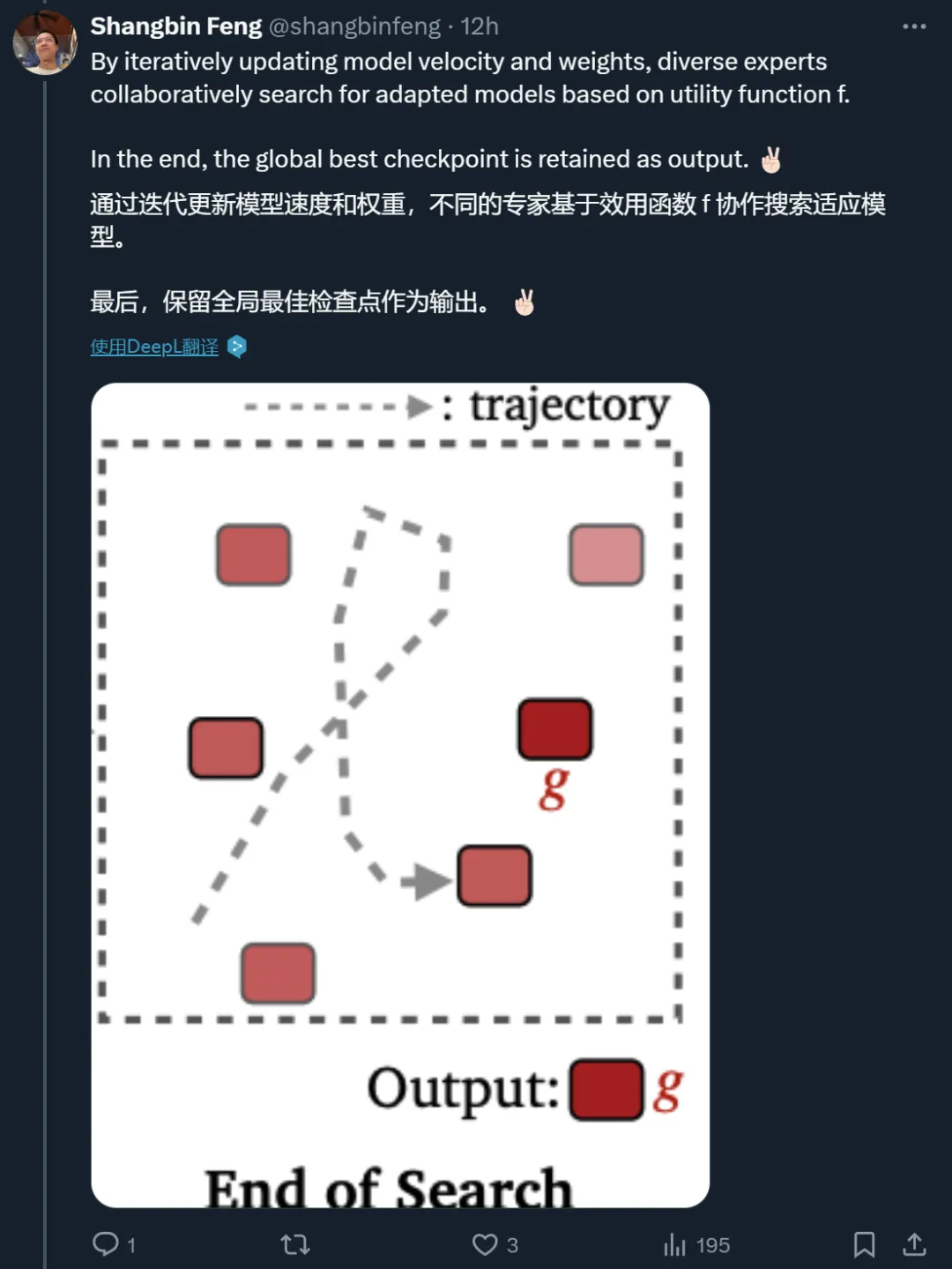
得益于灵活的搜索方法,MODEL SWARMS 不需要任何有监督的微调数据或关于 LLM 专家或效用函数的预先存在的知识,仅通过任何 model-to-scalar 效用函数指导的协作搜索和移动来适应 LLM 专家。
MODEL SWARMS 在四种不同的 LLM 适应目标上实现了卓越的性能:
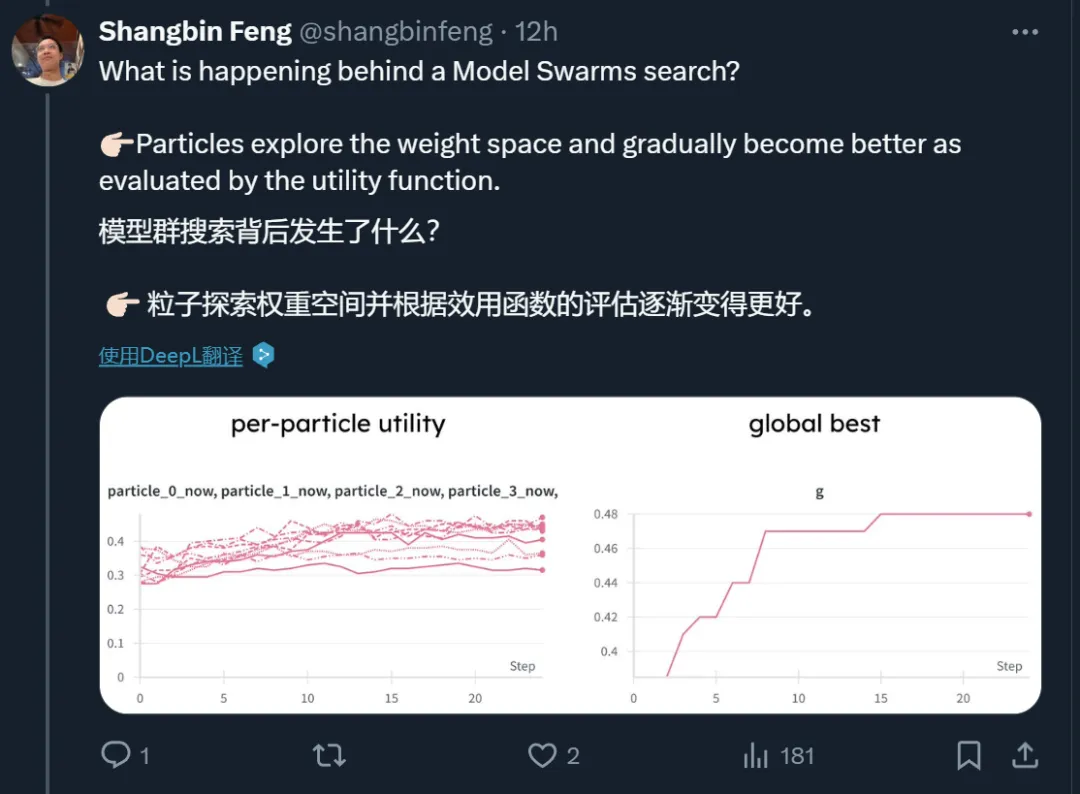

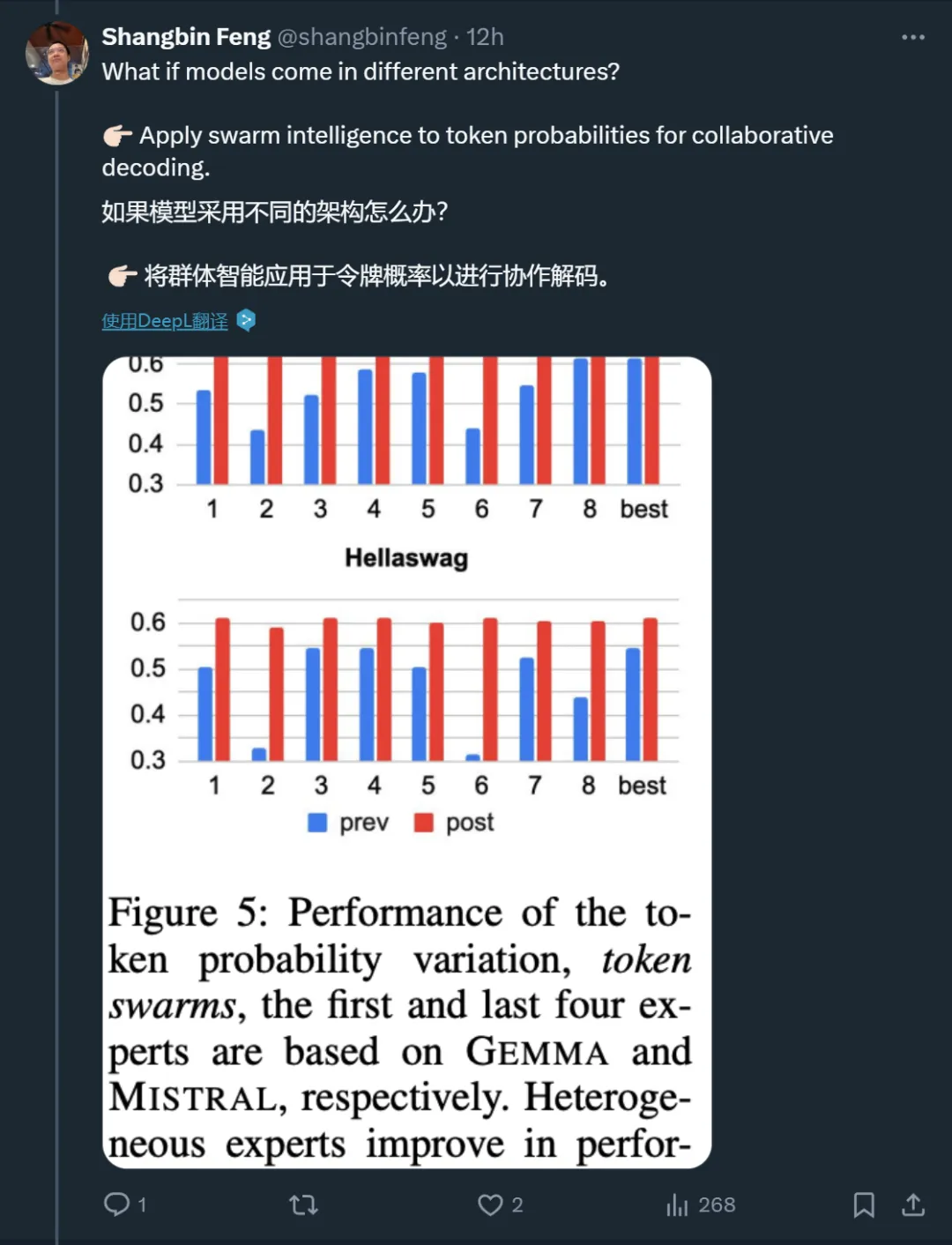
实证分析表明,初始专家的多样性至关重要,模型展现出了在初始检查点中未见的新能力,而且令人惊讶的是,最终表现最好的粒子通常并不是开始就表现最佳的那个。MODEL SWARMS 可以通过类似 dropout 的策略加速,并可以无缝扩展到不同模型架构专家的 token 概率算术。
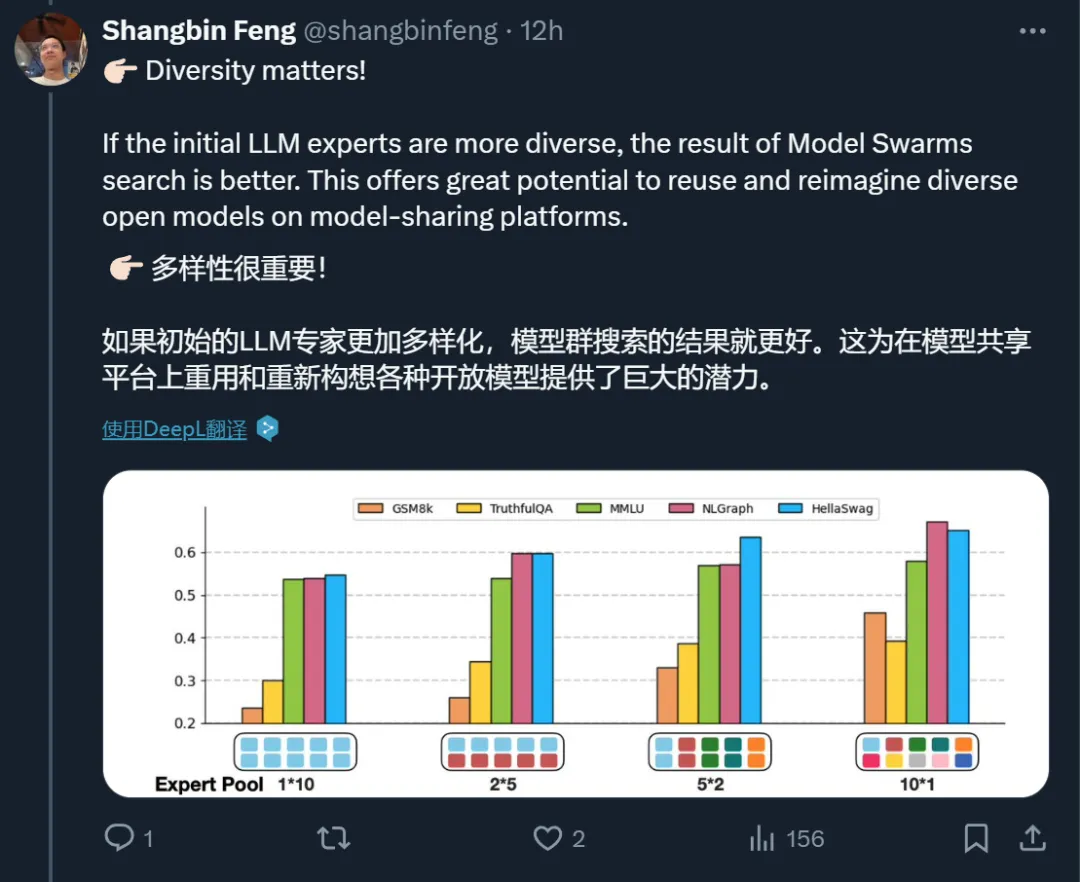
MODEL SWARMS 通过群体智能来适应 LLM 专家,图 1 和算法 1 概述了 MODEL SWARMS。
MODEL SWARMS 主要包括以下 4 个步骤:
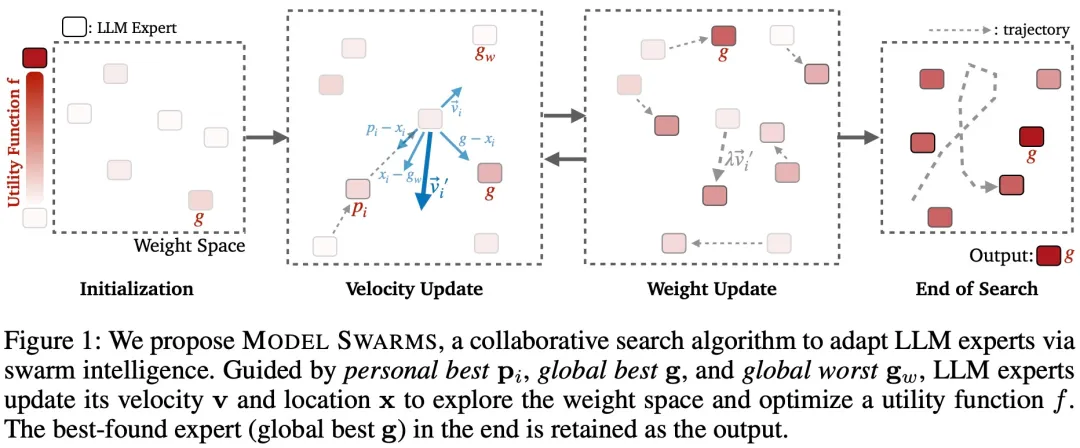

MODEL SWARMS 假设可以访问各种 LLM 专家,可以是完整模型或经过微调的 LoRA 适配器。MODEL SWARMS 还需要一个效用函数 f : x → R,将每个专家映射到一个应针对模型适应进行优化的标量值。效用函数可以是数据集性能、奖励模型分数或人类偏好。
受粒子群优化和一般进化算法(Back & Schwefel,1993)的启发,MODEL SWARMS 采用了几个术语:
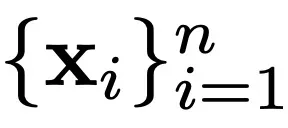 的搜索历史中最佳 / 最差位置。
的搜索历史中最佳 / 最差位置。粒子的位置和速度使 LLM 专家能够主动搜索而不是被动合并,而个体 / 全局最佳检查点有助于跟踪权重空间中的良好位置和邻域以进一步探索。
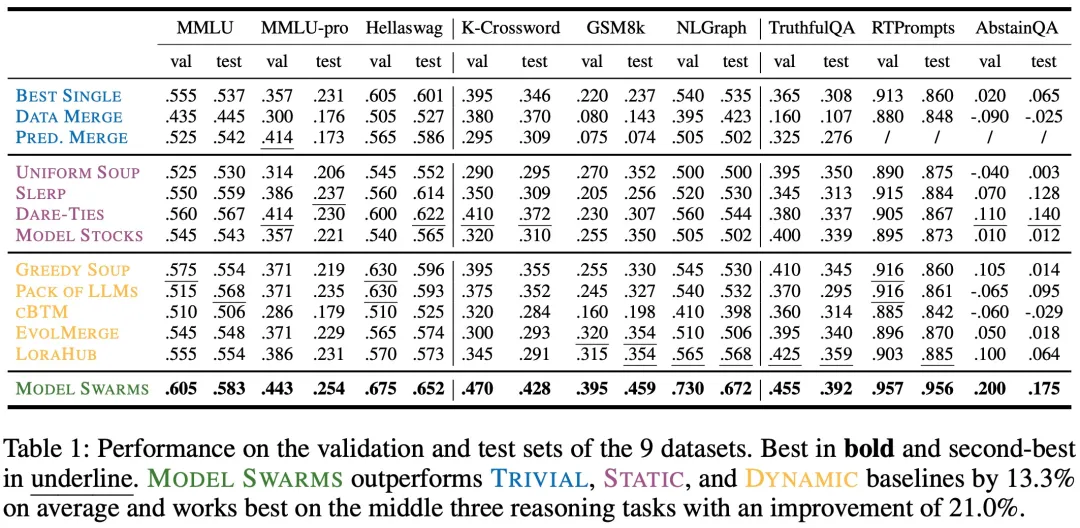
如下表 1 所示,MODEL SWARMS 在所有 9 个单一任务上都实现了 SOTA 性能:
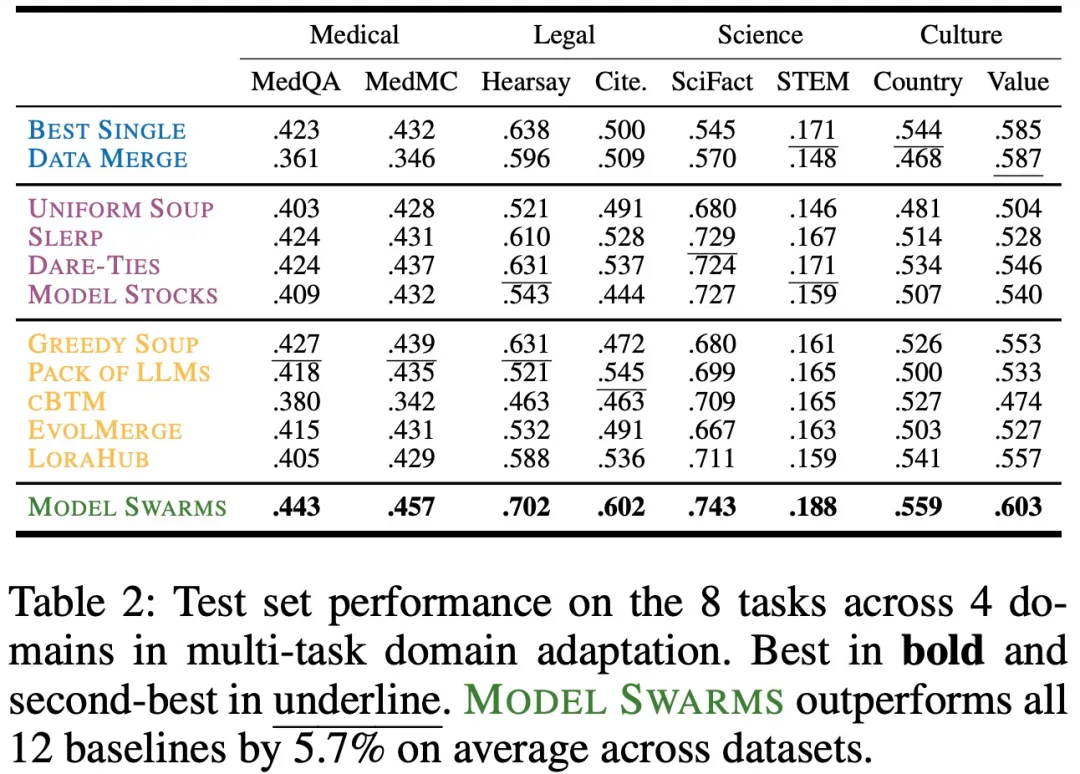
在多任务方面,下表 2 展示了 MODEL SWARMS 跨 8 个任务和 4 个域的测试集性能:
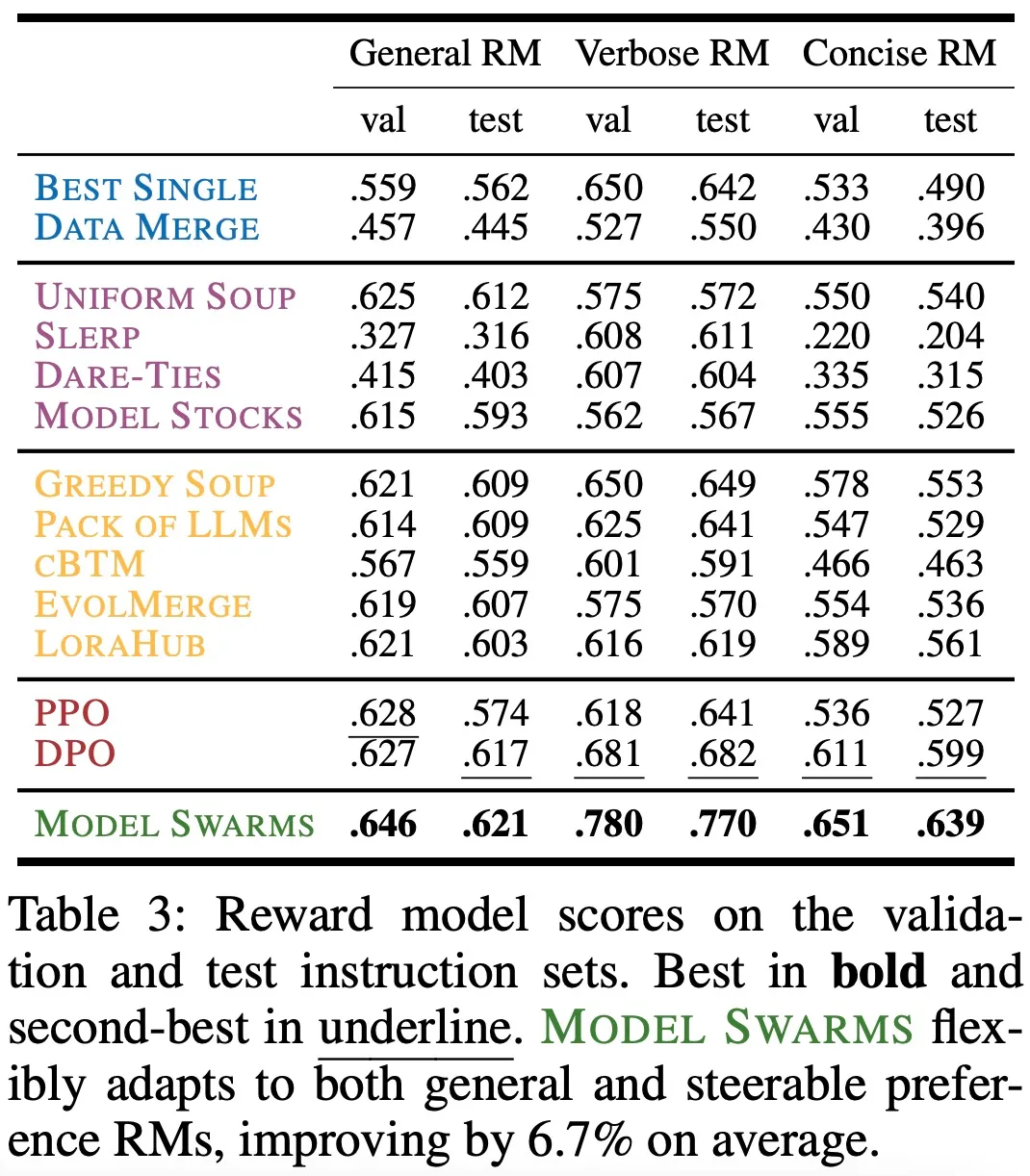
下表 3 展示了在验证和测试指令集上的奖励模型分数:
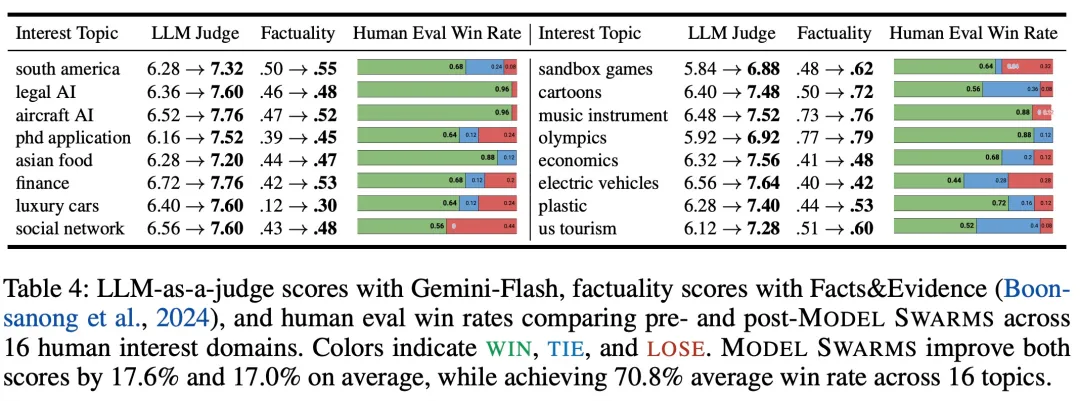
在 16 个人类兴趣主题上,MODEL SWARMS 前后的 LLM-as-a-judge 分数、事实性分数如下表 4 所示:
感兴趣的读者可以阅读论文原文,了解更多研究内容。
文章来自于微信公众号“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
