# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。
这样的问题或许可通过所谓的水印(watermarking)技术来解决。
谷歌开发的 SynthID 文本水印技术登上了最新一期 Nature 杂志封面,之前机器之心已经报道过该公司开发的图像水印技术,参阅《给 AI 生成图像「加水印」,谷歌发布识别工具 SynthID》。

给图像和文本添加水印具有各不一样的难点。
在给图像添加水印时,由于人眼的辨别相近色彩和能力远不及机器 —— 毕竟在机器「看」来,这些不同颜色本质上只是不同的数值。以下动图展示了多张加了水印和未加水印的对比图像。是不是完全看不来水印在哪里?

但对于以序列形式展示的文本,人类和机器一样可以分明地看见其中全部信息。那么该如何给文本添加水印呢?
为了使人工智能生成的文本更易于识别,Google DeepMind 创建了 SynthID-Text,现已通过 Google Responsible Generative AI Toolkit 开源。

论文地址:https://www.nature.com/articles/s41586-024-08025-4
开源地址:https://github.com/synthid-text
SynthID-Text 是一种可立即投入生产的文本水印方案,可保持文本质量并实现高检测精度,同时将延迟开销降至最低。并且,SynthID-Text 不影响 LLM 训练,仅修改采样程序;水印检测计算效率高,无需使用底层 LLM。
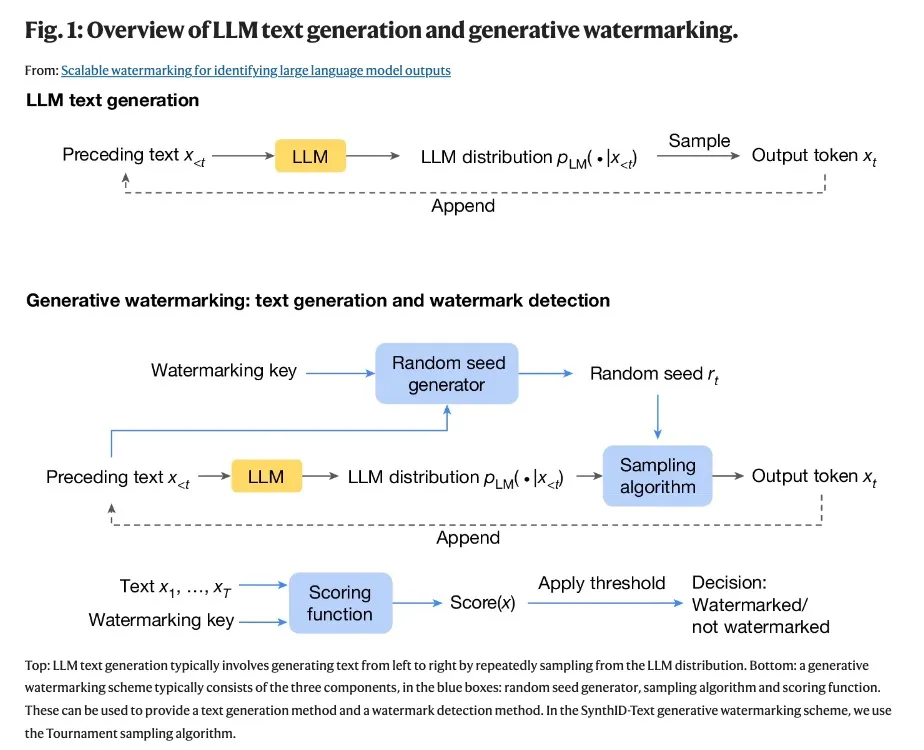
SynthID-Text 建立在以前生成水印组件的基础上,并引入了一种新型采样算法,即 Tournament 采样。SynthID-Text 可以配置为非失真(保留文本质量)或失真(以牺牲文本质量为代价提高水印可检测性)。在这两种设置中,SynthID-Text 都提供了更高的检测率。
简单举个例子,对于短语「我最喜欢的热带水果是__」,LLM 可能会使用 token「芒果」、「荔枝」、「木瓜」或「榴莲」来完成句子,并且每个 token 都会给出一个概率分数。当有一系列不同的 token 可供选择时,SynthID 可以调整每个预测 token 的概率分数,以免影响输出的质量、准确性和创造力。
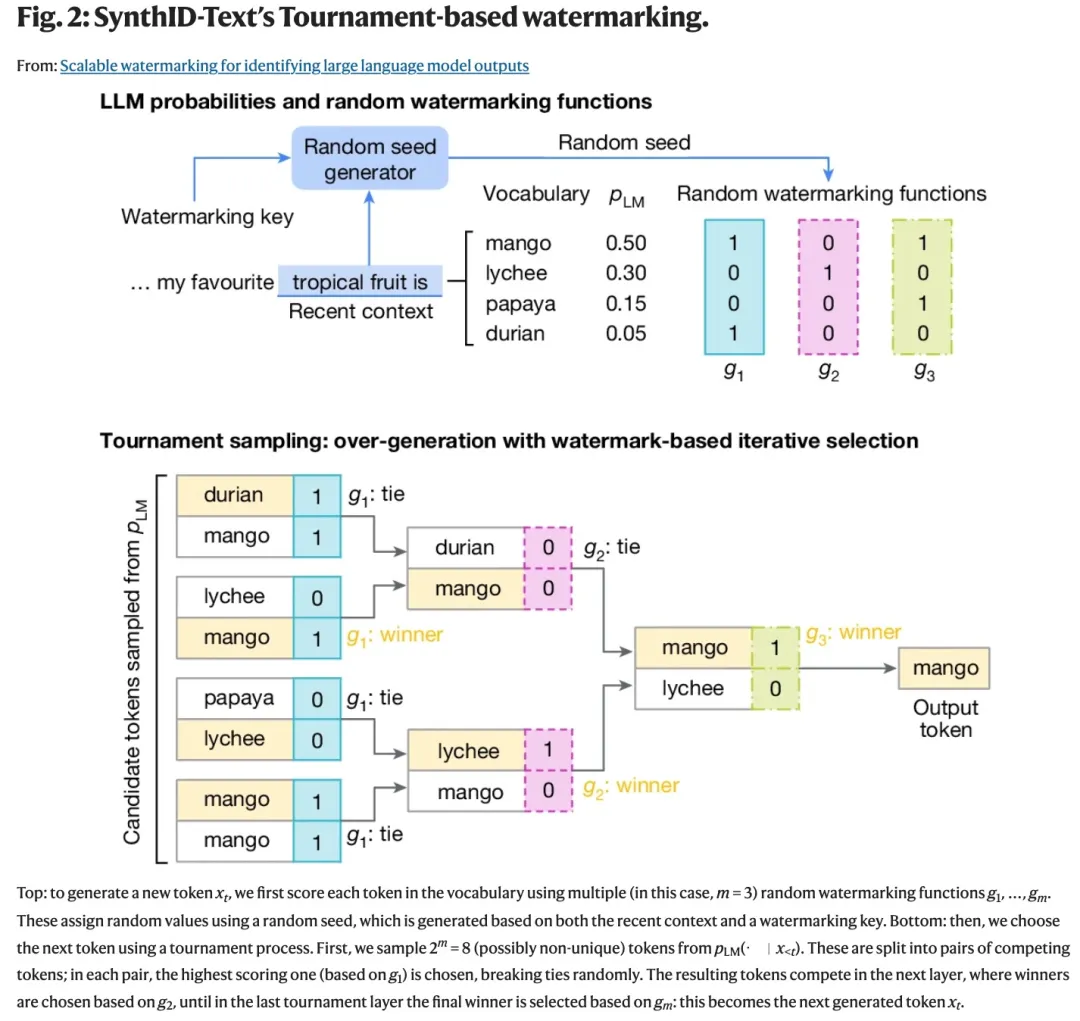
谷歌通过对来自 Gemini 实时互动的近 2000 万条响应进行了大规模用户反馈评估,结果表明:非失真 SynthID-Text 可以保持文本质量。因此,SynthID-Text 已被用于为 Gemini 和 Gemini Advanced 添加水印。这证明生成文本水印可以成功实施并扩展到现实世界的生产系统,为数百万用户提供服务。
此外,谷歌还提供了一种将生成水印与投机采样(speculative sampling)相结合的算法,允许将 SynthID-Text 集成到大规模生产系统中,而额外的计算开销可以忽略不计。
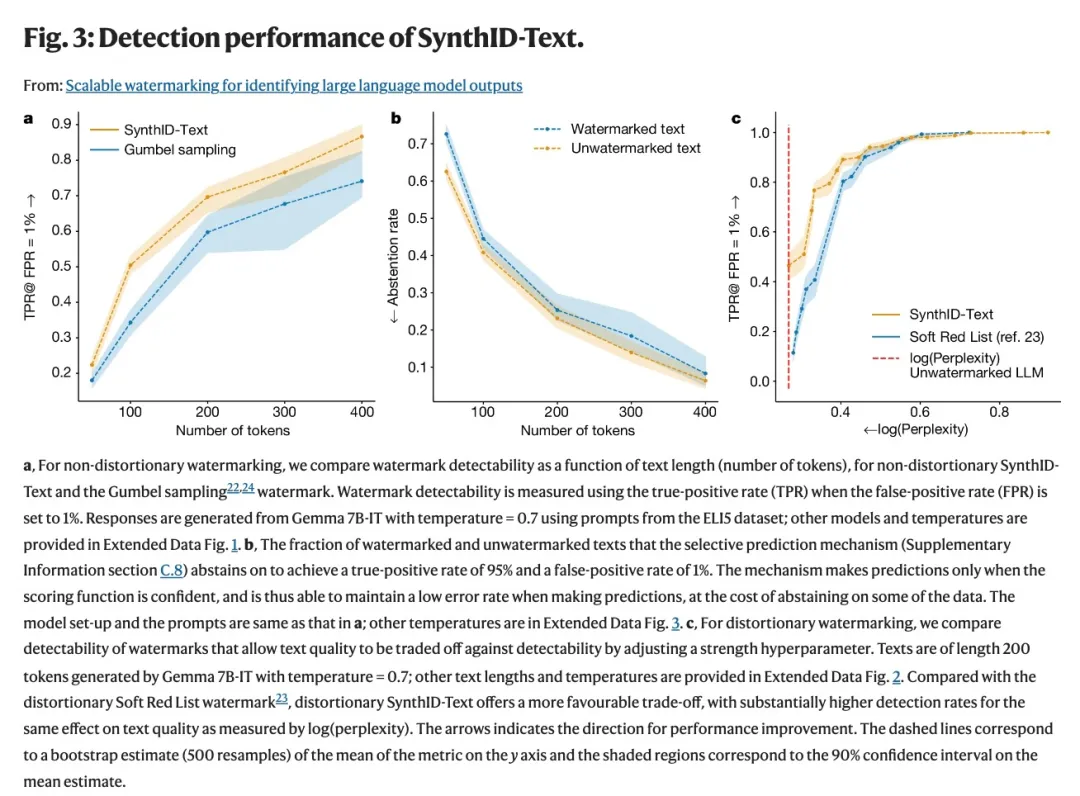
不过,SynthID-Text 目前仅可以处理短至三句话的文本,以及经过裁剪、解释或修改的文本,但却很难处理短文本、被重写或翻译的内容,甚至是对事实问题的回答。
谷歌表示:「SynthID 并不是识别人工智能生成内容的灵丹妙药,但 SynthID 将是开发更可靠人工智能识别工具的重要组成部分。」
参考链接:
https://www.theverge.com/2024/10/23/24277873/google-artificial-intelligence-synthid-watermarking-open-source
文章来自于微信公众号“机器之心”




