Google的AI水印,从独门技术变成了行业标准
Google的AI水印,从独门技术变成了行业标准Google AI在X上发了条推文。
来自主题: AI资讯
5413 点击 2026-07-03 10:40
 搜索
搜索
Google AI在X上发了条推文。
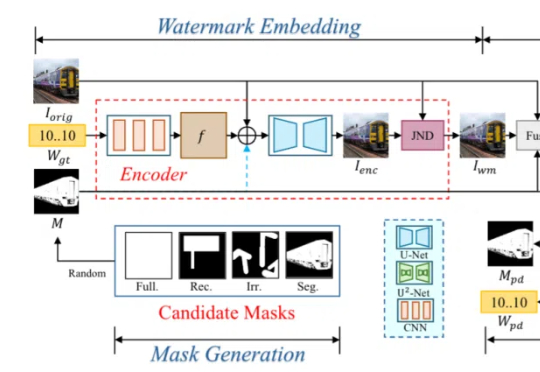
给AI生成的作品打水印,让AIGC图像可溯源,已经成为行业共识。
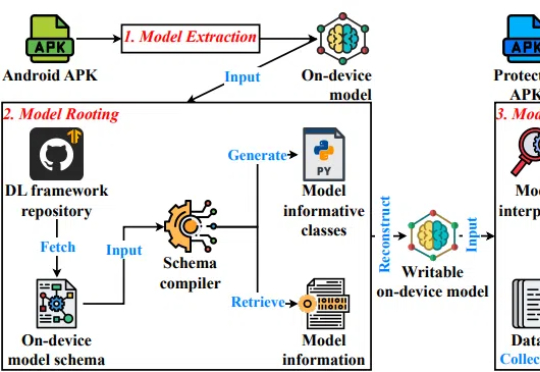
随着智能手机和物联网设备普及,移动端AI成为趋势,带来离线运行、低延迟、隐私保护等优势。然而,模型本地存储同时带来了严重风险。
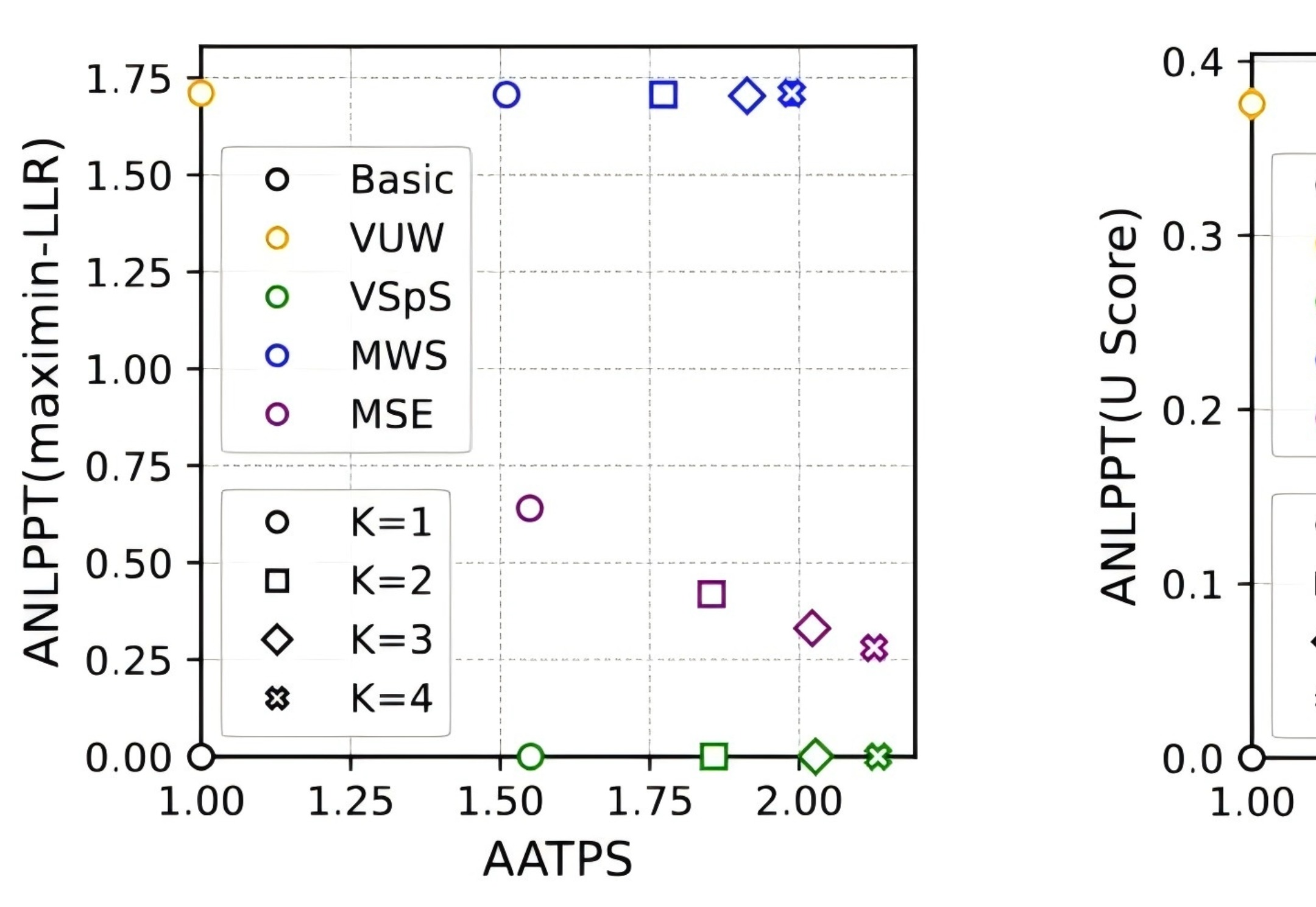
近日,DeepMind 团队将水印技术和投机采样(speculative sampling)结合,在为大语言模型加入水印的同时,提升其推理效率,降低推理成本,因此适合用于大规模生产环境。

近日,谷歌DeepMind发表的一项研究登上了Nature期刊的封面,研究人员开发了一种名为SynthID-Text的水印方案,已经在自家的Gemini上投入使用,跟踪AI生成的文本内容,使其无所遁形。

尽管生成式人工智能(AI)正在改变全球内容生产的格局,但诸多严峻挑战也随之而来:如何准确识别由 AI 生成的内容并防止其被滥用,尤其是在文本生成领域,已成为困扰越来越多人的一大难题。

现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。

AI已经成为了大学论文的最强代笔,师生之间打响了作弊与反作弊的持久战,为了赢得胜利,不得不卷起了装备——AI代写、AI检测器、AI文本水印、AI水印消除……科技公司新产品层出不穷,可老师布置的作业却几十年如一日,AI作弊的问题到底出在哪里?

本⽂介绍由清华等⾼校联合推出的⾸个开源的⼤模型⽔印⼯具包 MarkLLM。MarkLLM 提供了统⼀的⼤模型⽔印算法实现框架、直观的⽔印算法机制可视化⽅案以及系统性的评估模块,旨在⽀持研究⼈员⽅便地实验、理解和评估最新的⽔印技术进展。通过 MarkLLM,作者期望在给研究者提供便利的同时加深公众对⼤模型⽔印技术的认知,推动该领域的共识形成,进⽽促进相关研究的发展和推⼴应⽤。