# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能技术快速发展的今天,大语言模型(LLM)已经展现出惊人的能力。然而,让这些模型生成规范的结构化输出仍然是一个难以攻克的技术难题。不论是在开发自动化工具、构建特定领域的解决方案,还是在进行开发工具集成时,都迫切需要LLM能够产生格式严格、内容可靠的输出。
我之前有多篇文章《重磅惊雷,用结构化RAG约束JSON响应格式化,复合AI系统输出成功率高达82.55%》《又见惊雷,结构化Prompt格式小小变化竟能让LLM性能波动高达76%,ICLR2024》《一记惊雷:改一下Prompt的输出顺序,就能显著影响LLM的评估结果》都在介绍关于LLM输出问题,LLM输出是和各位产生最直接关系的部分,所以代号为“惊雷”,一般用这个题目,都是在介绍和LLM输出有关的内容。今天的这篇文章内容很简单,但用途却非常广泛,MTP(Meaning Typed Prompting)是一种新的提示词技术,它的主要目的是让AI生成更规范、更可靠的结构化输出,关键它还支持多模态输出!!!

MTP就像是一个"模板语言",告诉这个助手:"我要的答案必须是这个格式,每个部分都有特定的含义和规则。"使用MTP的好处是:输出格式统一,数据更容易处理,错误更少,AI更容易理解你的要求。使用MTP也很简单,第一步:定义你要什么;第二步,说明含义;第三步,要求输出格式。
当前业界普遍采用的解决方案主要依赖于零样本或少样本提示技术。开发人员需要提供JSON模板或Schema来定义期望的输出格式,然后通过后处理步骤来提取和验证生成的数据。这种方法存在多个严重的问题:

1. 过度依赖JSON Schema导致模型推理能力受限
2. 详细的Schema定义会大量增加token消耗
3. 难以保证语法的正确性,经常产生无效输出
4. 需要投入大量人力编写和维护提示模板
5. 系统适应性差,难以快速响应需求变化
6. 输出质量不稳定,需要频繁进行修正和验证
含义类型化提示(Meaning Typed Prompting, MTP)技术的提出,标志着结构化输出生成领域的一次重要突破。它的核心思想可以概括为三个方面:
1. 类型系统的创新:扩展传统的内置类型和自定义类型系统,引入自然语言表达的类型定义方式。这种创新让类型定义不再是冰冷的符号,而是具有丰富语义的描述。
2. 表示方式的改进:摒弃繁琐的JSON Schema,转而采用更直观的Python类表示方式来请求结构化输出。这一改变大大降低了系统复杂度,提升了开发效率。
3. 语义信息的融入:将语义信息直接嵌入到提示中,减少对外部抽象的依赖。这种方式让模型能够更好地理解任务要求,产生更精准的输出。
MTP的提示分为两个部分,System Message 和 User Message

MTP的技术架构包含以下几个关键组件:
1. Python类表示系统
传统的JSON Schema方式:
{
"properties":{
"first_name":{"title": "First Name", "type": "string"},
"last_name":{"title": "Last Name", "type": "string"},
"yob":{"title": "Year of Birth", "type": "integer"},
"likes":{
"items":{"type": "string"},
"title": "Interests",
"type": "array"
}
},
"required":["first_name", "last_name", "yob", "likes"],
"title": "Person",
"type": "object"
}
MTP的Python类表示方式:
Person (Class) -> Person(
first_name: str,
last_name: str,
yob: int,
likes: list[str]
)
这种表示方式带来的优势包括:
- 代码量显著减少,提高了可读性
- 减少特殊字符使用,降低token消耗
- 更符合Python开发者的习惯
- 便于维护和修改
- 支持IDE的代码补全和类型检查
2. 表达性类型定义系统
MTP允许开发者使用自然语言来增强类型定义的语义表达:
Person (Class) -> Person(
first_name: str - "Given name of the person",
last_name: str - "Family name of the person",
yob: int - "Year of Birth (e.g., 1990)",
likes: list[str] - "List of favorite activities and interests",
location: Semantic[str, "City, Country format"] - "Current residence location",
status: Semantic[str, "Active | Inactive | Pending"] - "Account status"
)
这种定义方式的优势:
1. 提供了清晰的语义上下文
2. 减少了理解歧义
3. 支持复杂的类型约束
4. 便于文档生成
5. 提高了代码的自解释性
3. 提示组件系统
MTP提示包含以下核心组件:
1. 目标声明:
@llm.enhance("Extract structured information from user profile")
2. 信息上下文:
Information(
examples=[
Person(first_name="John", last_name="Doe", ...),
Person(first_name="Jane", last_name="Smith", ...)
],
context="Consider cultural variations in name formats"
)
3. 输出类型定义:
Output[Person] # 指定返回类型为Person对象
4. 输入参数:
def extract_profile(
text: str - "Raw profile text",
language: str - "Profile language"
) -> Person:
pass
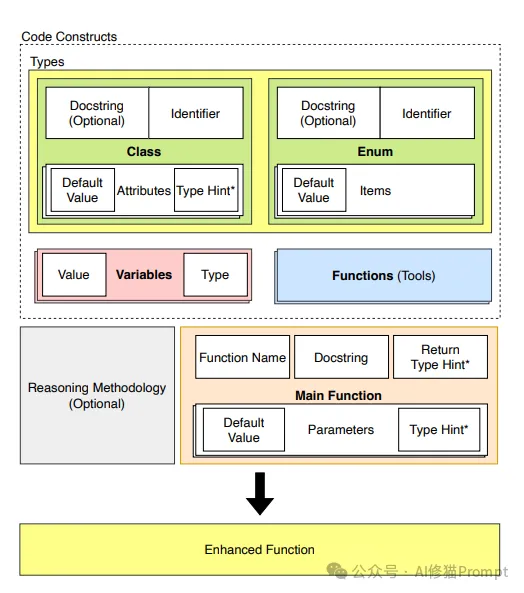
Semantix框架实现了一个强大的语义类型系统:
class Semantic(Generic[T, S]):
def __init__(self, base_type: T, semantic: S):
self.base_type = base_type
self.semantic = semantic
def validate(self, value: Any) -> bool:
# 实现类型验证逻辑
pass
Semantix是一个Python库,可自动生成意义类型的提示。Semantix允许开发人员通过添加名为enhance的装饰器来将简单函数增强为增强功能。语义类型提示允许开发人员添加富有表现力的类型定义。上图Semantix将Types、Variables、Functions和Main Function合并为一个增强函数,该函数在运行时生成MTP。下图有详细的运行示例。

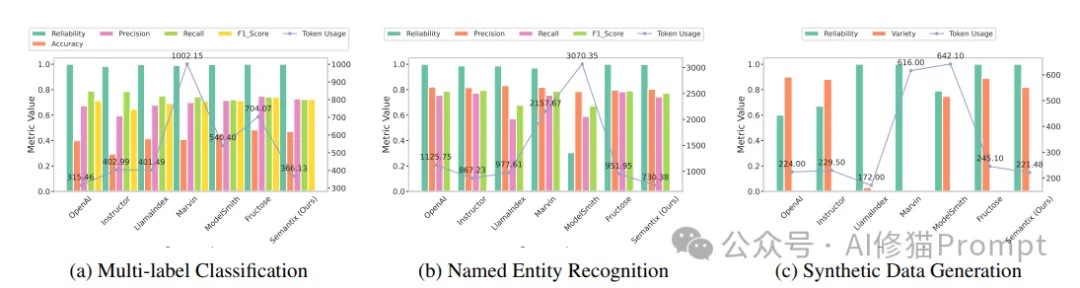
1. 多标签分类任务
性能分析:
- Semantix在准确率上领先其他框架
- Token使用效率处于较好水平
- 具有极高的可靠性
2. 命名实体识别任务
性能分析:
- Semantix在Token效率上有明显优势
- 准确率与其他框架相当
- 整体性能表现均衡
3. 合成数据生成任务
性能分析:
- Semantix保持了极高的可靠性
- 数据多样性表现良好
- Token使用量最优
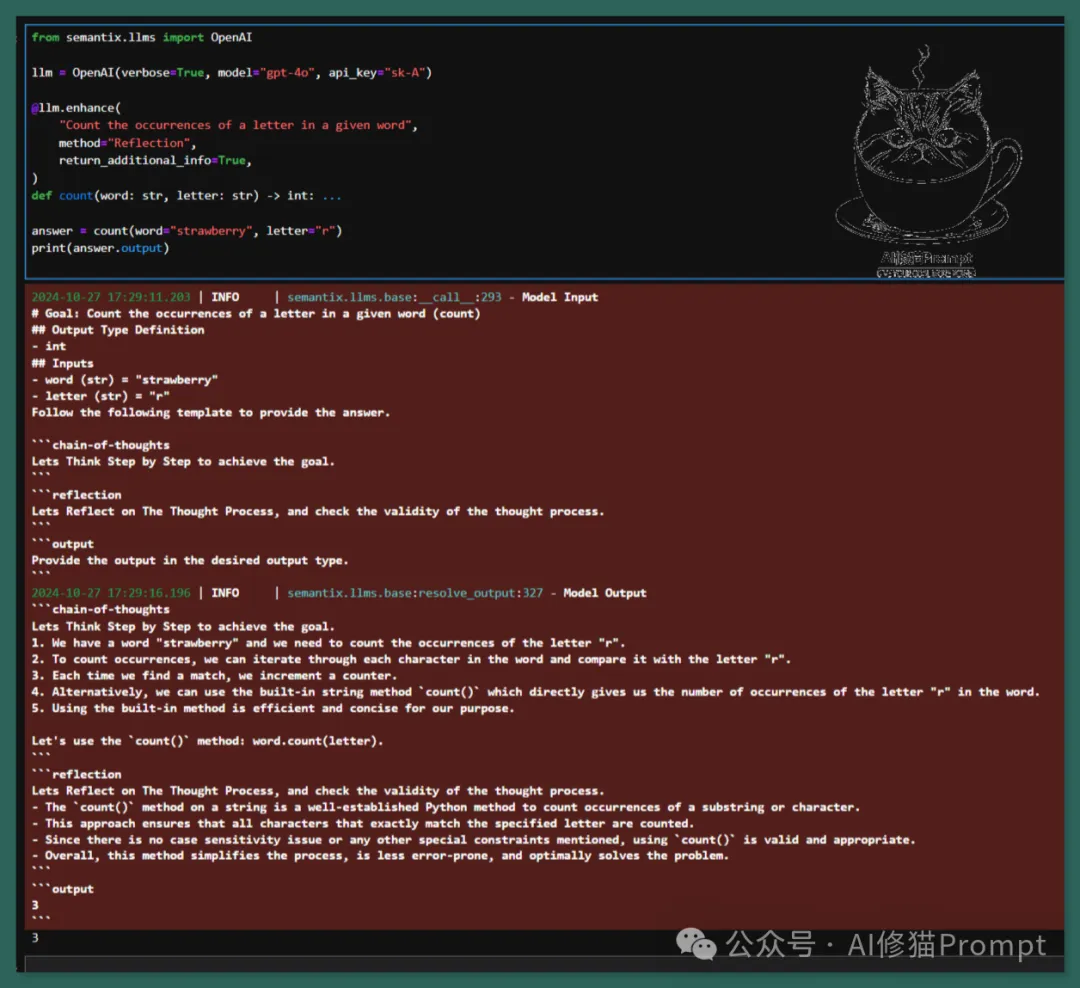
示例一:还是用那道你已经很熟悉的题目,草莓strawberry这个单词里有几个"r"?
示例二:再找一张小票,能分析这张小票,也能分析一下Video:

示例三:食品分析案例利用多模态LLM通过CoT来识别拉面中的营养数据,包括卡路里、蛋白质、碳水化合物、脂肪、纤维和钠水平。

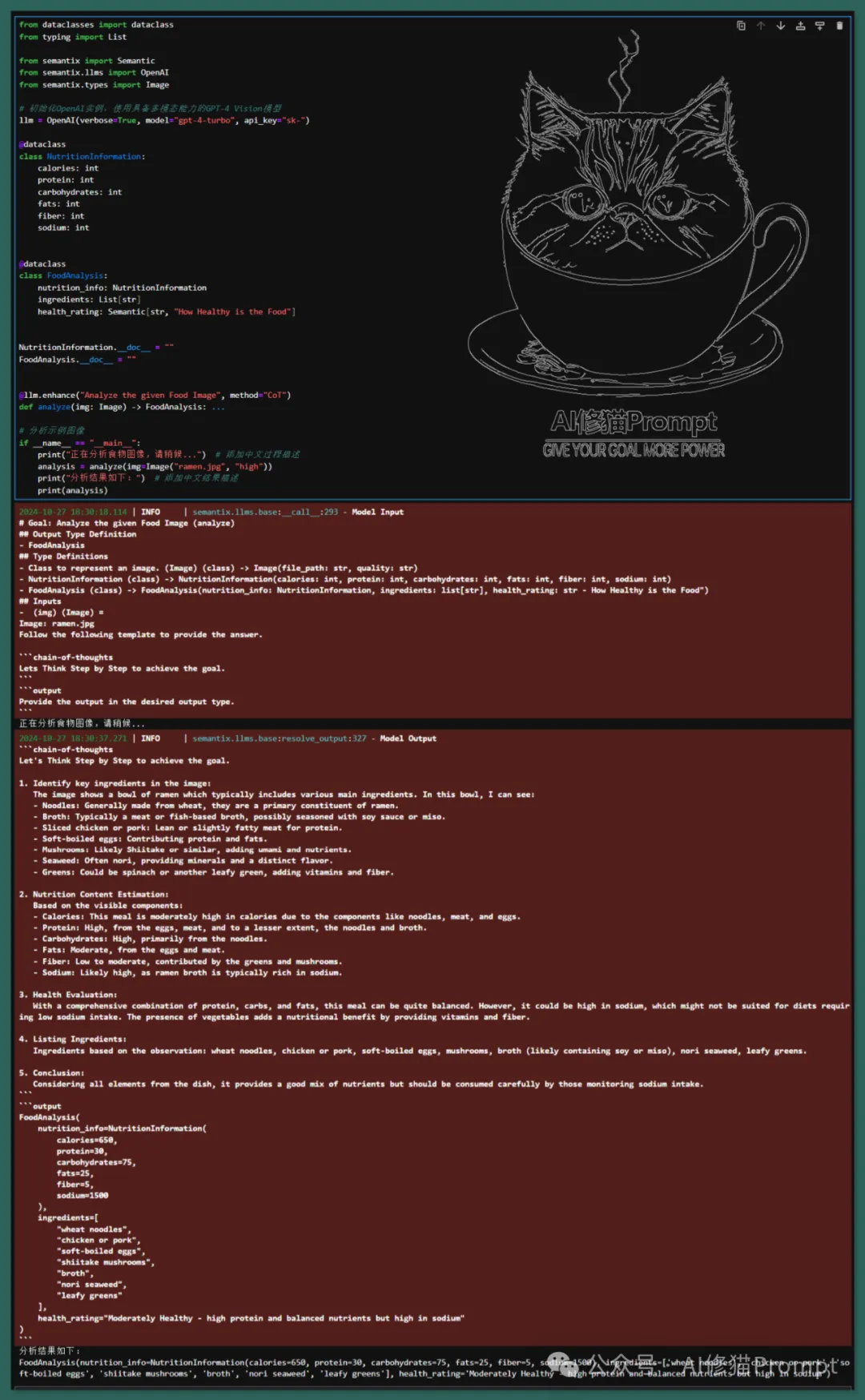

我运行的结果:
FoodAnalysis(nutrition_info=NutritionInformation(calories=650, protein=30, carbohydrates=75, fats=25, fiber=5, sodium=1500), ingredients=['wheat noodles', 'chicken or pork', 'soft-boiled eggs', 'shiitake mushrooms', 'broth', 'nori seaweed', 'leafy greens'], health_rating='Moderately Healthy - high protein and balanced nutrients but high in sodium')
模型不一致,图片清晰度不一致,导致图片识别存在误差。
MTP技术的出现为LLM结构化输出生成提供了一个新的解决方案。通过将语义信息直接嵌入到类型定义中,它既保持了系统的简单性,又实现了更好的性能表现。对于正在开发AI应用的朋友们来说,MTP提供了一个强大而灵活的工具,有助于提高开发效率和输出质量,我用模型网页界面和代码分别向您展示了MTP技术的结果。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
