# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

介绍:
https://rongyaofang.github.io/puma/
代码:
https://github.com/rongyaofang/PUMA
论文:
https://arxiv.org/abs/2410.13861v2
PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。
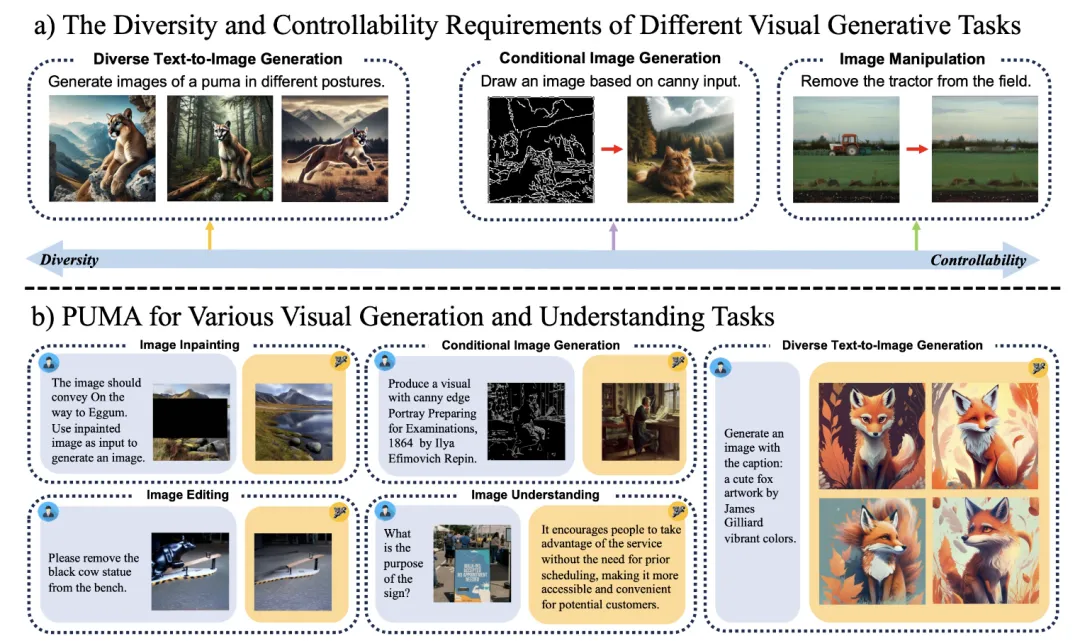
该模型不仅能够理解图像,还能根据文本提示生成多样化的图像,执行图像编辑和修复任务,以及在特定条件下生成图像。PUMA通过结合多粒度视觉特征作为输入和输出,能够适应不同图像生成任务的粒度需求,从文本到图像生成所需的粗粒度语义概念到图像编辑所需的细粒度细节。



PUMA 模型的关键特性包括一个图像编码器,用于提取多粒度的图像表示;一个自回归MLLM,用于处理和渐进生成多尺度图像特征;以及一系列专门的扩散模型作为图像解码器,能够在不同粒度上解码图像。通过这种多粒度方法,PUMA能够在保持语义准确性的同时,为文本到图像生成等任务提供多样化的输出,并且在需要精确控制的图像编辑任务中保持高质量的细节。
PUMA 技术的核心思路是构建一个统一的多模态大型语言模型(MLLM),该模型能够处理和生成不同粒度级别的视觉表示,以适应从文本到图像生成的多样性需求到图像编辑的精确控制需求。这一总体思路通过整合多粒度视觉特征作为MLLM的输入和输出,实现了在单一框架内对多种视觉生成任务的灵活处理。
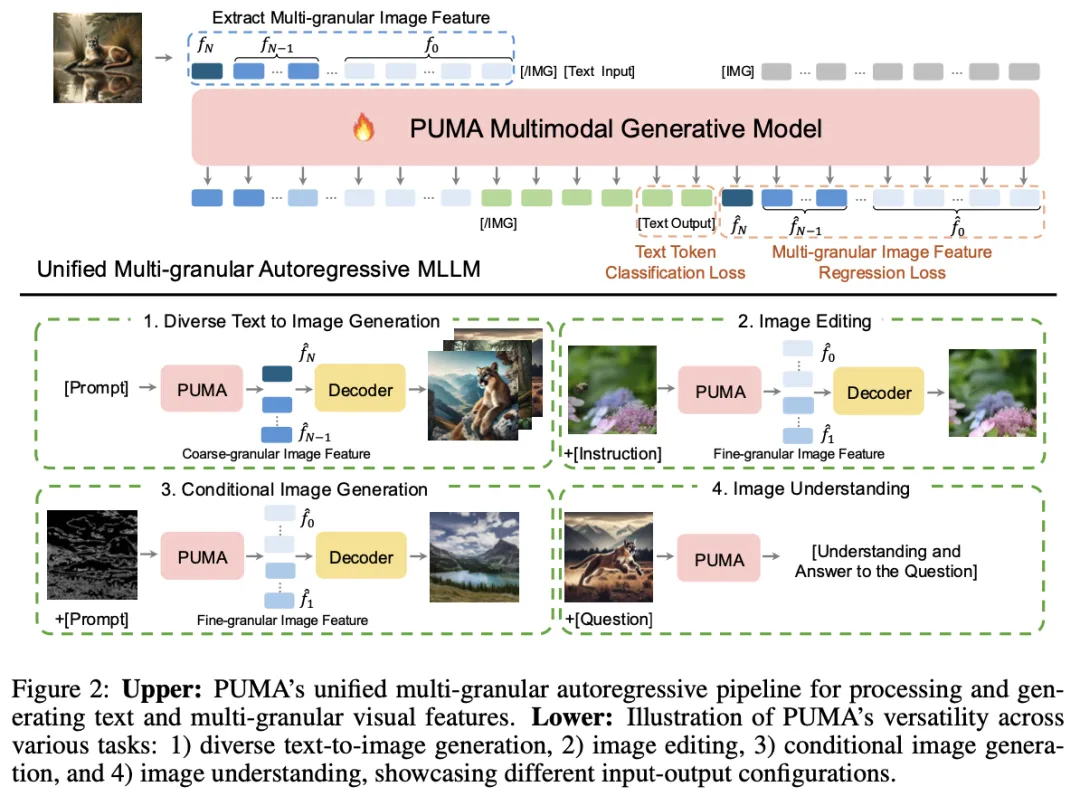
具体来说,PUMA技术的处理过程涉及三个关键模块:
其技术特点包括其能够适应不同任务的粒度需求、处理和生成多尺度特征的能力,以及通过预训练和调优实现的高效学习。


PUMA技术为多模态AI领域提供了一种全新的范式,使得单一模型能够在保持高性能的同时,处理多样化的视觉任务。这种能力不仅推动了图像生成和编辑技术的发展,还为实现更广泛的人工通用智能目标奠定了基础。PUMA技术未来有望在多模态交互、内容创作、自动化设计等多个领域发挥重要作用,其灵活的框架也为进一步的研究和应用提供了广阔的可能性。
这篇技术报告介绍了一个名为PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)的多模态大型语言模型(MLLM),它能够在统一的框架内处理和生成多粒度的视觉表示,以平衡视觉生成任务中的多样性和可控性。
论文的主要内容要点概括如下:
摘要:
1. 引言:
2. 相关工作:
3. 方法:
4. 实验:
5. 结论:
文章来自于微信公众号“ADFeed”,作者“ADFeed”



