# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,AI圈的风向变了。从前都在卷大模型的各家,忽然开始提速上了新的赛道。
Anthropic的Claude 3.5 Sonnet,已经学会像人一样操作电脑。
被逼急的OpenAI,也不再卯着劲构建o1,而是组建多智能体团队,还被外媒曝出正在开发新品,自动化复杂的软件编程任务。
微软一口气连发10个智能体;Meta也通过智能体,把大模型引入各个应用和设备。
未来一切计算皆AI,所有计算设备都要具备AI的能力。
不过,面对「电脑升级为AI PC,手机升级为AI手机」的巨大需求,我们的算力真的够吗?
不仅如此,当前AI算力发展还面临着高功耗、低算效,计算架构多样生态割裂等挑战,我们又该如何解决这些问题?
就在10月24日,浪潮信息正式发布的元脑®服务器第八代新品,便实现了算力的全方位「智能增强」。
单点并不能实现技术突破,只有以系统性方法才能推动智算平台的创新。
这一次,浪潮信息分别在算效、多元算力、能效三大层面上,取得了最亮眼的成绩。

在通用算力领域,浪潮信息率先达成了「一机多芯」——同一架构能同时支持英特尔、AMD等多款CPU处理器。
而作为当今业界的SOTA产品,元脑®服务器第八代算力平台已荣登SPEC CPU和SPEC Power双榜榜首。
在SPEC CPU基准测试中,人工智能计算性能提升70%,整数数组计算性能飙升102%,视频压缩能力提升38%,脚本程序设计语言性能提升26%,数据压缩性能提升7%,每瓦性能提升20%。
实测数据表明,在Llama 2大模型推理场景中,整机性能较上代可提升3倍之多!

元脑®服务器新品同时刷新SPEC CPU和 SPEC Power最佳纪录
对比上一代平台性能纪录提升24%,能效纪录提升20%
在智能预警方面,全新升级的内存故障智能预警修复技术MUPR基于大量建模分析和算法训练,能提前预警、实时隔离、智能修复内存故障,使内存宕机故障率降低80%,还能提前7天预警硬盘故障。
在智能散热方面,开创性地采用单个风扇单独调控转速策略,依据后窗负载和部件情况设定多种温度阈值,更精准调控风扇,可降低13%的系统功耗。
在智能管理方面,通过RTOS实时操作系统,实现开机3秒内智能管理调控风扇转速,降低30%的噪音。与此同时,IRUT固件智能无感升级技术,不仅可以轻松实现无需人工干预的固件在线升级,而且还能保障升级后系统的性能和可靠性。

针对大模型部署难题,自研的服务器操作系统KOS AI定制版仅需简单2步就能完成训练环境搭建,对于200节点训练集群开发环境,20分钟即可完成部署上线并可用,极大地提高了大模型开发部署效率。
如今,生成式AI在企业侧、行业侧的落地在提速。
然而正如上文所言,日趋丰富的AI应用场景,也衍生出全新的多元算力挑战。
一方面,如今不同AI应用表现出了不同的典型特征和系统需求,显然需要更多元的算力生态。
在不同的业务场景,对算力要求都会有所差异,因此就需要选择不同的芯片。
随着各方对客户需求的捕捉,以及技术的升级迭代,这种CPU的分化,如今已成为必然。
另一方面,更强大的AI也需要同样更为强大的通用算力来支持。
适配各种加速卡的处理器节点面临算力、内存容量、内存带宽、IO扩展等多方面的挑战。
这需要强大的CPU系统生态来实现系统资源的最佳利用。
然而,x86、ARM、RISC-V等不同架构的CPU处理器种类多样,仅在中国就有10多种,不同CPU的协议标准还不统一。

就算能为每一种CPU芯片单独设计一个模组,或一套系统,但怎样才能通过大量测试和验证,让它的稳定性和安全性到达形成一个产品的层级?这一点是很难的。
此外,AI推理的特点是高并行,因此CPU总线互联带宽、内存带宽及容量也需要特别优化……硬件开发、固件适配等时间激增,让算力系统的设计难度极大。
多元CPU的生态挑战,该如何解决?
有没有可能通过一个解耦架构,把整个CPU当成一个部件呢?如果有一个通用的CPU算力底座,就能解决CPU的计算效率问题。
幸运的是,在第八代算力平台中,浪潮信息真正把这个构想变成了现实。
浪潮信息研发团队和上下游伙伴做出了基于OCM单路、双路的机器,它的计算、存储、管理、供电完全解耦,硬盘、PCIe的扩展都是统一的。
只要换掉CPU和内存构成的最小计算模组,就可以支持英特尔和AMD等CPU,去做相应的互换和支持。
这就是业界目前在推的开放计算模组规范(OCM),基于处理器的标准化算力模组单元,构建CPU的统一算力底座。
所谓OCM,也即Open Compute Model。

大会上,浪潮信息发布了首款基于服务器计算模组设计规范OCM的NF3290G8,整机全面解耦,以CPU、内存为核心构建最小算力单元,高速/低速互联接口全面标准化。
它能够实现处理器算力模组部件化,灵活支持多类型CPU,让不同算力共享统一平台,降低算力产业创新试错成本和推广适配成本,也让多元化的应用场景快速找到贴合方案。
值得一提的是,OCM首批成员,集结了国内外顶尖机构和企业,中国电子标准院、百度、小红书、浪潮信息、联想、英特尔、AMD等都在内。

2024年中国开放计算峰会,开放算力模组规范正式启动
当今大模型的Scaling Law,对算力扩展提出了巨大需求。
大模型的高效训练,通常需要千卡以上高算力AI芯片构成的服务器系统。千卡互联的前提,就是解决单个服务器内部芯片的高速直联。
但长期以来,单个服务器内多元AI加速卡形态和接口不统一,高速互连效率低,研发周期长,这些难题大大阻碍了AI算力的生态。
为此,全球基础硬件技术领域覆盖面最广、最有影响力的开源组织OCP,组织定义了更适合超大规模深度学习训练的AI加速卡形态——开放加速规范(Open Accelerator Model,OAM)。

如今,OAM早已成为全球高端加速芯片采用的统一标准,90%的高端加速卡都是基于OAM规范设计的。
而浪潮信息,便是最早一批加入OAM生态的核心贡献者之一。
当时国内大概有20余款AI芯片,之所以生产后能快速上市,就是得益于OAM规范的模组化设计,让企业在设计芯片时,能够按照模组接口、硬件和软件的要求直接做生产。
而在这次大会上,浪潮信息这次也发布了基于UBB2.0规范开发的元脑®服务器NF5898G8,可以兼容符合OCP开放加速规范的多款OAM 2.0模组。
这种全模块化的设计,极致的系统能效,能够大幅缩减国内外加速芯片和服务器的适配周期,加速了先进算力的上线部署,从而支撑大模型和AI应用的迭代成熟。
现在,OAM已经为全球20多家AI芯片企业节省研发时间6个月以上,为产业研发投入节省数十亿元。突破大模型Scale up的互联瓶颈,可能也不会远了。

元脑®服务器实现一机多芯,全面解耦
看到这里你一定发现了,浪潮信息一直秉承的,就是开放的生态。
在这个领域,浪潮信息已经深耕了几十年,极大促进了产业生态的良性发展。
而随着技术的不断演进,浪潮信息也成为了国内当之无愧的服务器龙头企业,因此就更需要更开放的生态,从而拉动整个服务器产业链的协作。
在浪潮信息提出的标准下,所有厂商、供应商、客户都可以灵活选择。客户的需求越来越大,供应商也会不断投入,至此,行业内就形成了正向循环。
当更多新的部件能快速做产业化,就提升了行业整体的竞争力,让所有人受益。
现在市场上,很多整机柜都是紧耦合系统,这其中就存在着隐患。因为封闭系统只有几个供应商,如果上下游厂商的生产或质量有问题,就可能延缓上市周期。
而浪潮信息认为,创新技术要在产品上快速应用,开放一定是最好的方式。只有开放,才能让创新技术的产业化速度更快。
在人工智能飚速发展的当下,算力能源消耗也成为不容忽视的关键难题。
纽约客曾爆料称,为了回答约2亿个请求,ChatGPT日耗电达到惊人的50万度,是美国普通家庭用电量1.7万倍!
而且,这一耗电量据称比传统的谷歌搜索,多出近10倍。

另有BestBrokers最新数据佐证,ChatGPT每年平均耗电高达4.536亿度电,支出约5940万美元(0.131美元/kWh)。
更具象化地说,这相当于能为全美EV电动车充2次电;可满足美国43204个家庭供电;能为9570万部iPhone充满一整年的电。

然而,ChatGPT并非个例。这一触目惊心的数据,让我们不得不重新审视AI发展过程中的能源问题。
不可否认的是,大模型Scaling Law依旧是大势所趋。这意味着,参数递增的同时,LLM对算力的需求还会继续攀升。
为了满足下一个Grok模型训练,马斯克xAI团队在19天之内,搭建出世界最大的超算集群Colossus,由10万块H100组成。
殊不知,这还只是第一期工程。
马斯克自曝,很快就要建成20万块由H100/H200组成的训练集群。两种Hopper GPU配比分别5万块。

为了推进Llama 4训练,小扎称预计需要用掉比Llama 3多十倍的算力,并且正在做约10万块H100超算的收尾工作。
OpenAI这边,微软提供算力早已不够用,并转向甲骨文谈合作。预计下一代模型(可能GPT-5)的计算量将飙升到GPT-4的10-20倍,相应耗电量和碳排放也会极具飙升。
而且,随着AI算力的快速拉升,集群功耗猛增,到2024年单机柜的功耗已经超过100千瓦。
这些种种迹象表明,随着LLM规模扩大,如何平衡计算性能和能源效率之间的矛盾,是行业面临的主要挑战。
值得庆幸的是,业界也已经开始探索一些积极的解决方案。
全球TOP 500超算第一的Frontier选择在克林奇河(Clinch River)附近建设,充分利用了自然水源提供冷却能力。
在地理选址上,美国橡树岭国家实验室很好地平衡了高性能计算和散热需求。
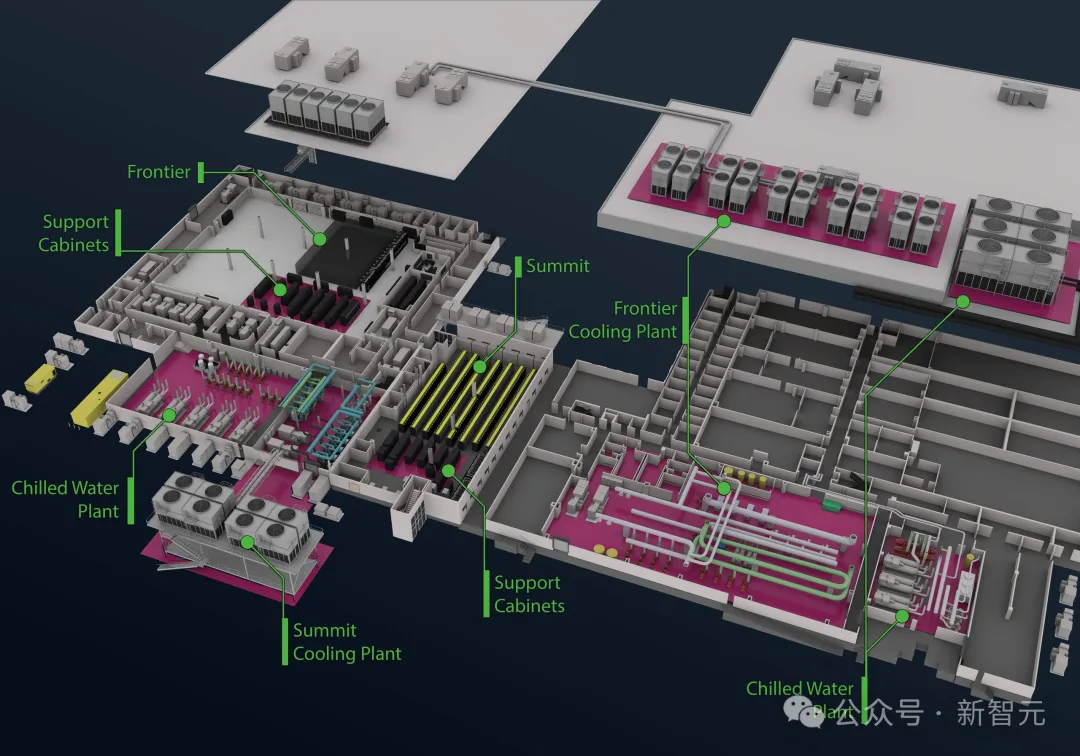
再来看xAI的「大脑」Colossus,同样采用了先进的液冷系统设计。
全部机房搭建在架高的地板上面,下面一层铺设了所有液冷系统的管路,用来与大楼冷却设备进热交互。

每个机房大约有25000块GPU,而每个机柜包含了8个Supermicro的液冷机架。
液冷设计不仅能有效管理温度,还大幅降低了机房的噪音水准。机柜背后的热交换器,更确保了整个系统在最佳温度下运作。

另外,即将出货的英伟达Blackwell芯片,虽有液冷MGX和风冷DGX两款服务器,但若想发挥出GPU极致性能,液冷几乎是必选。
IDC上半年发布的报告中指出,中国液冷服务器市场2024上半年出货量同比增长81.8%,预计到2028年将达到接近百万台。
2023-2028年,中国液冷服务器年复合增长率将达47.6%,增速是风冷服务器的5倍以上。
与此同时,我们也看到随着PUE要求的越来越低,单机柜功耗要求越来越高,这时候必然要采用液冷技术来达成目标。

由此可见,从技术路径来看,AI服务器走向液冷也成为了业界共识。
AI+液冷的组合,已是大势所趋。
在此,浪潮信息也推出了「All in液冷」解决方案,采用了领先的原生液冷技术,让系统更节能、更绿色。
具体来说,全线元脑脑®服务器产品支持「冷板式液冷」,从核心部件到整体方案的全方位覆盖,包括芯片、内存、NVMe硬盘、OCP网卡、电源、PCIe转接卡和光模块等服务器主要发热部件。
其实,去年推出的第七代服务器,是全球首个支持冷板式液冷的系统。
到了第八代,除了单机「All in液冷」之外,还做到了高功率的整机柜液冷。

元脑®服务器液冷整机柜内部节点
这一次,浪潮信息最新发布了两相液冷130kW液冷整机柜,在技术创新上有以下亮点:
单个整机柜最高可以支持130千瓦的整体的供电和解热,可以说是在最大程度上将液冷与高密相结合,充分发挥了液冷在数据中心领域的优势和价值,又充分保证了使用的安全可靠。
除此之外,第八代产品还有更多功能,实现了绿色节能。
在部件绿色化方面,全面支持钛金电源,电源转换效率达98%以上。
还有全局部件温度监控,包括网卡、NVMe、M.2等全部的部件都可以进行精准的温度识别。而且,还可以通过单风扇实现精细化调控。
每个服务器内部不同的PCIe接口位置安装了不同的IO设备。当服务器配置万兆网卡和百G网卡时,它们的光模块对温度的敏感度不同,系统会分别制定不同的散热策略。
单风扇调控的最大优势在于,让风扇和IO设备建立一对一关系,根据后端负载不同,独立灵活去调控风扇转速。
另外,针对关键核心部件、高功耗零件设计独立风道配合单风扇的散热调控。
同时,针对风扇研发高效能风扇,改良风扇充磁方式、改进扇叶曲面设计,提升风扇散热效率20%;另外还可以根据CPU负载瞬时调整CPU频率,节省CPU的能耗。

不仅如此,浪潮信息还提供液冷数据中心全生命周期的解决方案。
它具有从室外一次侧冷源到室内二次侧CDU、液冷连接系统、液冷服务器等全线布局,为用户全方位打造绿色节能数据中心交钥匙工程。
还有你想不到的是,整机柜一体交付也是节能绿色的另一种解决方案。
英伟达GB200整机柜推出,在业界具有风向标意义,也就意味着数据中心部署模式正在发生一个重要的转变。

传统的数据中心建设,往往是先建机柜,然后再安装服务器。
而在整机柜交付模式下,数据中心只需做好电力、网络等基础配置后,就可以直接接收预装好服务器的完整机柜。
浪潮信息同样采取了「整机交付」的革新方案,不仅能够提升部署效率,还为更高功耗服务器的规模化部署提供了更好的支持。

在绿色智算中心建设中,浪潮信息开创性地实现了「全生命周期」绿色化。
不论是物流运输环节包装,还是产品设计的技术突破,再到数据中心的PUE优化,形成了一个完整的绿色发展生态链。
特别是,在第八代产品中,将绿色节能理念从单个产品延伸到整个数据中心层面,实现了从点到面的系统性突破。
在人工智能时代浪潮中,我们正站在一个关键转折点:
AI计算不再是锦上添花,而是未来计算必备底座。也就是说,未来一切计算皆AI。
浪潮信息推出的元脑®服务器第八代,以「一机多芯」创新架构,展现了对这一趋势的深刻洞察。
在这场AI变革中,强大而灵活算力支撑,正如智能时代「方向盘」,正重塑每个行业的未来图景。
这不仅是技术的进步,更是企业占据AI发展优势的制胜点。
参考资料:
https://mp.weixin.qq.com/s/FyFJbaBZPcXcMcHyaK7M4w
https://mp.weixin.qq.com/s/rC3bbMhHVVxT-5q44XqU2w
文章来自于微信公众号 “新智元”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
