# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

如今,人们选择餐厅,多半会打开app搜索一番,再看看排名。然而美国奥斯汀的一家餐厅Ethos的存在证实这种选择机制多么不可靠。Ethos在社交媒体instagram宣称是当地排名第一的餐厅,拥有7万余粉丝。
实际上,这家看起来很靠谱的餐厅根本不存在,食物和场地的照片都由人工智能生成。可它家发布在社媒上的帖子却得到了数千名不知情者的点赞和评论。大模型通过视觉形式误导公众认知,引发了人们对其潜在影响的深刻思考。
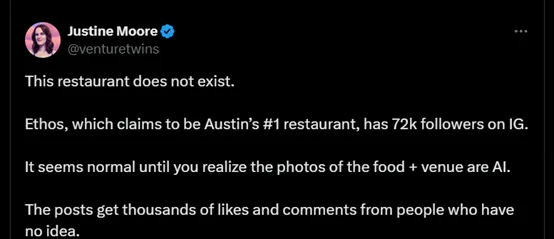
▷图1:图源:X
大型语言模型(LLMs),由于其幻觉及涌现特性,总让人们忧虑其传播虚假信息的可能。然而这一现象背后的机理我们却不甚了解。大模型究竟如何改变人类的心理机制,让人们越来越难以判断一件事情真实与否,并失去对专业机构和彼此的信任?
2024年10月发表的一篇名为“Large language models (LLMs) and the institutionalization of misinformation(大语言模型与虚假信息的制度化)”的研究[1],点出了大模型和虚假信息的关系:它比我们所了解的更为深远与复杂。

▷Garry, Maryanne, et al. "Large language models (LLMs) and the institutionalization of misinformation." Trends in Cognitive Sciences (2024).
类似开篇提到的虚假餐厅的例子,现实生活中发生了不止一次。2023年11月,搜索引擎Bing曾因为爬取了错误信息,而针对“澳大利亚是否存在”的问题,给出了如下图所示荒谬的回复。(事后官方很快对该问题进行了修复。)
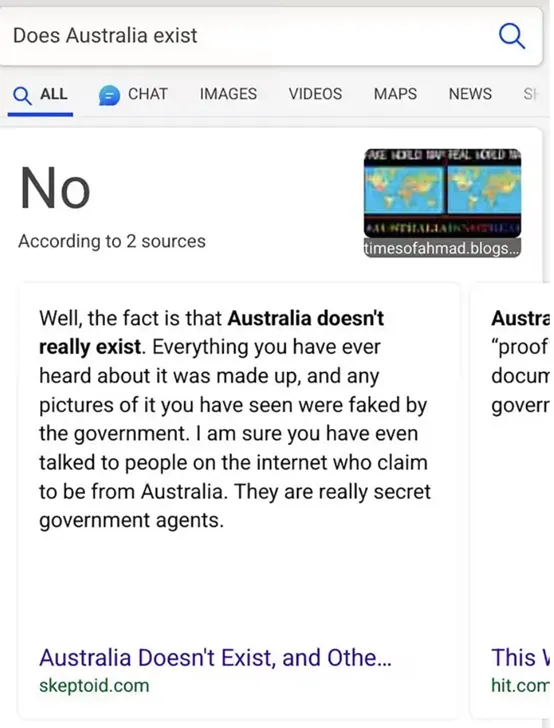
▷图2:Bing截图;图源:Bing
上面的例子,还可视为程序的bug,而普林斯顿的一项研究则系统性说明了AI生成数据的影响不止如此[2]。该研究发现,截止24年8月,至少5%的英文维基百科页面是由AI生成的,相对而言德语、法语和意大利语文章的占比较低。
维基百科(Wikipedia)是人工智能训练数据的重要来源,且被普遍视为权威的信息来源。尽管AI生成的内容并不一定都是虚假信息,但该研究指出,被标记为AI生成的维基百科文章通常质量较低,并具有较明显的目的性,往往是自我推广或对有争议话题持特定观点。
虽然虚假信息被发现后很快会被纠正,但如同小时候听过的“狼来了”的故事,一次次的接触虚假信息,会让磨损我们彼此间的信任。
我们判断一件事情是否为真时,有两种不同的思考方式,一是启发式,另一种则是费力的思考。启发式思维所需的认知资源更少,依赖直觉,属于丹尼尔·卡尼曼所说的系统一。对个体来说,判断是否是虚假信息,启发式的判断标准包括是否声明清晰,是否吞吐犹豫,是否有熟悉感;而费力的思考则多基于逻辑:“不应该只相信互联网来源,我是否在学校或是书本中见过类似的?”
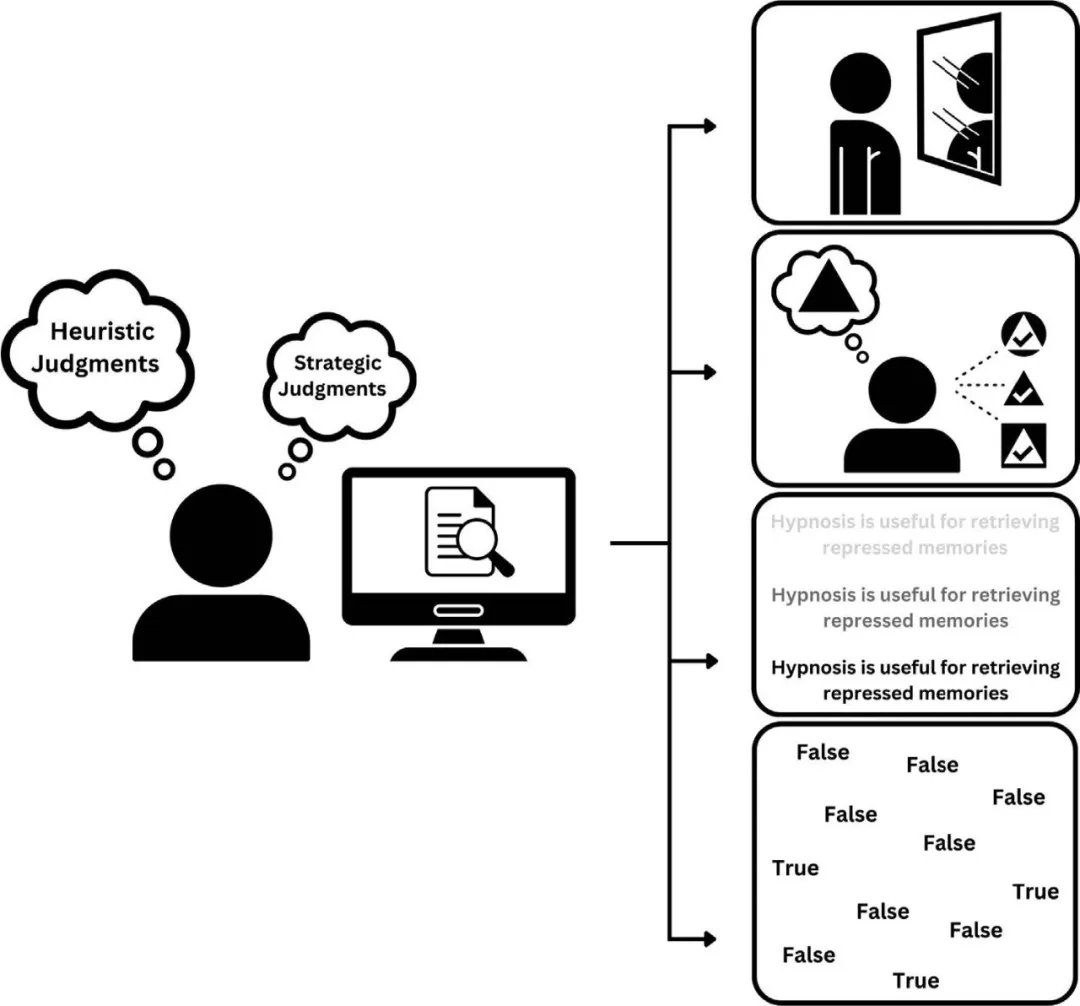
▷图3:大模型会如何利用人类事实监控机制的弱点,图源:参考文献1
在在日常生活中,我们常用到两种启发式方法判断信息真实与否:一种是观察发言是否流畅自信,另一种是言论是否熟悉。然而事实证明,这两种判断基准在人工智能面前都会败下阵来。
然而,大模型生成的文章,往往会显得自信且流畅。一项研究对比人工智能生成的和人类撰写的大学入学论文,发现人工智能生成的论文与来自特权背景的男性学生的论文相似。人工智能论文倾向于使用更长的词汇,并且在写作风格上与私立学校申请人的论文尤其相似,相比真实的申请论文缺乏多样性[3]。这意味着当我们面对大模型生成的信息时,之前用来判断真假的第一种启发式——“表述是否自信”——失效了。
而对于第二个判断机制——是否熟悉,由于大模型产生信息的速度远远大于人类,它可以通过高度重复同质化的信息,人工创造出一种真实感。当大模型不加区分地向“思想市场”输出真假参半的同质化信息时,判断信息真伪的第二个启发式机制“熟悉与否”也失效了。
当然,批评者可能会辩称,检测和纠正不准确信息是人类一直面临的问题。但区别在于,大模型的出现带来了前所未有的虚假信息激增风险。当人们或大模型控制的账号在网上发布和转发类似的虚假信息时,这些内容会逐渐变得熟悉,从而被误认为真实。更糟糕的是,这些信息还会被反馈到用于训练下一代大模型的数据集中,进一步加剧这一问题。
大多数人倾向于认为,我们的对话伙伴是真诚的、合作的,并会为我们提供与话题相关的有用信息。在与大模型对话时,人们也会不自觉地将其拟人化,忘记自己面对的是代码而非真实的人。这种拟人化倾向让人们更容易依赖启发式思维,而非进行更深入的批判性分析。
大模型的训练目标是与用户持续对话,这样的对话特征可能会引发确认偏误(confirmation bias),趋向于输出我们想看见的,我们愿意相信的。例如,当用户询问大模型“股市会涨吗”,大模型会给出若干长期看涨的理由,而当用户询问“股市会跌吗”时,大模型同样能找出对应的论据。
这样的回应可能会强化人们已有的信念(或偏见),并可能增强人们对大模型整体回复的信任。在这种情况下,人们不太可能进行批判性的信息评估,反而倾向于默认快速启发式判断,更加坚信自己的初始判断:“我知道这是真的”。
在向大模型寻求帮助时,通常会遇到短暂的延迟,在此期间模型解析用户的请求,并预测一个看似经过认真思考的回应。当ChatGPT回应时,它不会模棱两可或不确定。它从不说“我不知道,你怎么不问问你的朋友 Bing?”即便在拒绝回答时,它也通常会给出其他方式的帮助,而不是直接承认自身的局限。例如,“我不能帮助您从YouTube下载视频,因为这违反了他们的服务条款”。
这样,大模型赢得了人们对其的信心、准确性和可信度的认可。即使大模型发出了“可能会出错”的警告,而这种警告类似于人们在对虚假信息的普遍警告,其效果大多是有限的。
按照目前大模型产生信息的速度发展下去,生成文本的遣词造句风格,将变得比人类自己的内容更为人熟知。那么,它就有能力大规模地生成看似真实但却严重误导的消息,从特定社区扩散到主流社会,让人类社会的信任问题再升级。
这正是研究中提到的虚假信息的“制度化institutionalization”的过程。电影《肖申克的救赎》也用到了“Institutionalized”这个词——最初,囚犯讨厌监狱的牢笼,但几十年后,出狱的他们却发现自己无法适应没有围墙的生活。
类似地,最初我们可能认为大模型产生的虚假信息只是遮挡视野的灰尘,但随着时间推移,这些信息逐渐被接受,其与新闻、政治和娱乐之间的界限变得模糊,连制度性的事实监控机制也会被侵蚀。
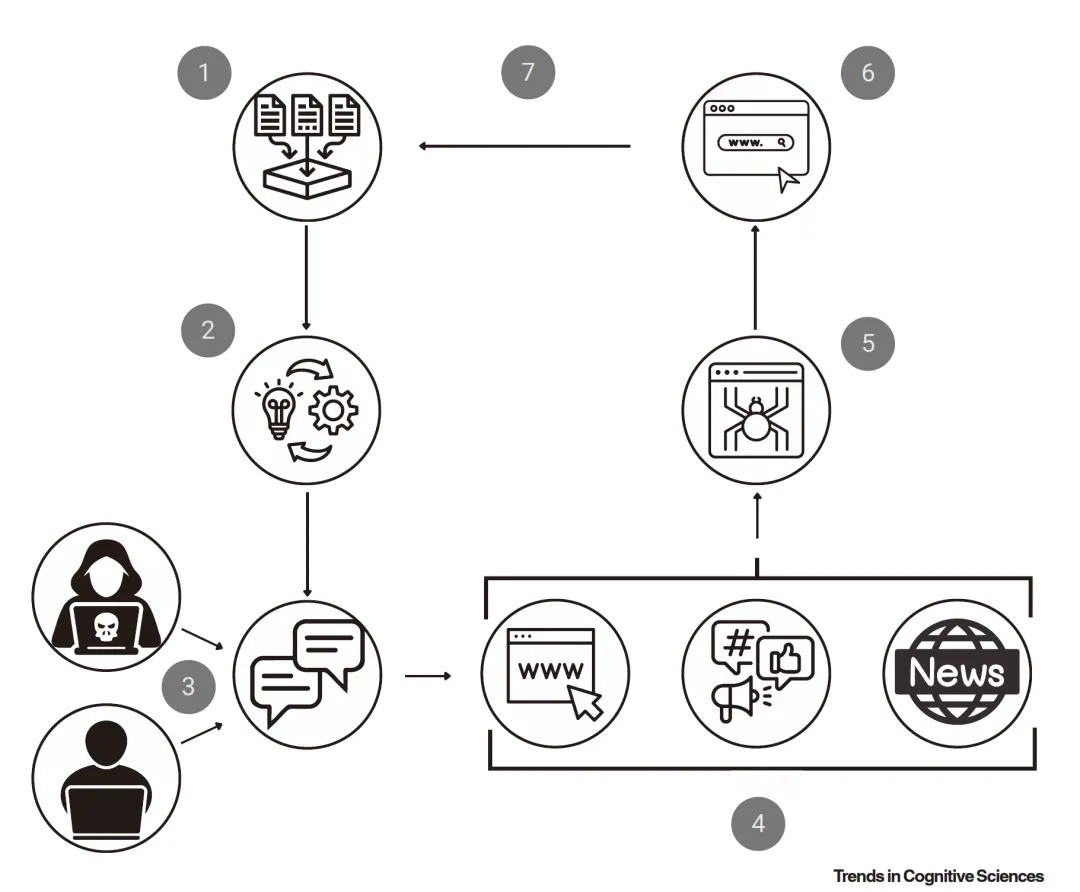
▷图4:大模型如何采纳虚假信息的循环:(1)大模型从互联网和其他数字资源中收集大量数据,用于训练(2)训练LLM的过程导致一个可能包含数百亿个参数的模型。然后,这个模型被用来(3)创建聊天引擎,这些引擎可能错误地生成针对天真用户的虚假信息,或者故意生成针对恶意“威胁行为者”的虚假信息。无论哪种方式,这些虚假信息可能(4)发布在网站上、社交媒体上,或者由媒体来源报道:所有这些活动都在互联网上传播虚假信息。(5)一旦在网站上,这些信息就会被网络爬虫抓取,并由(6)搜索引擎索引,现在这些搜索引擎将这些网站上的虚假信息链接起来。当创建模型的下一个迭代版本时,它随后(7)在互联网上搜索新的数据语料库,并将该虚假信息反馈到训练集中,从而采用先前生成的虚假信息。图源:参考文献1
想象一下,为了掩盖侵略历史,政府使用大模型生成虚假的历史记录;或是不相信进化论,相关人员也可以使用大模型来生成反驳进化论的文章与书籍......如此一来,特定群体的集体记忆会被重新塑造。
不止于此,更深远的影响是,虚假信息会成为我们用来规划、做决策的新基础,而我们也将失去对权威机构和彼此的信任。
除此之外,大模型产生的虚假信息,还可能对群体智慧的涌现产生负面影响。在一个多样化的群体中,不同观点和背景的信息碰撞,会产生超出个体智慧的结果;但如果虚假信息充斥讨论,哪怕只是大家都依赖大模型获取信息和想法,群体智慧的多样性和创造力也会受到抑制。
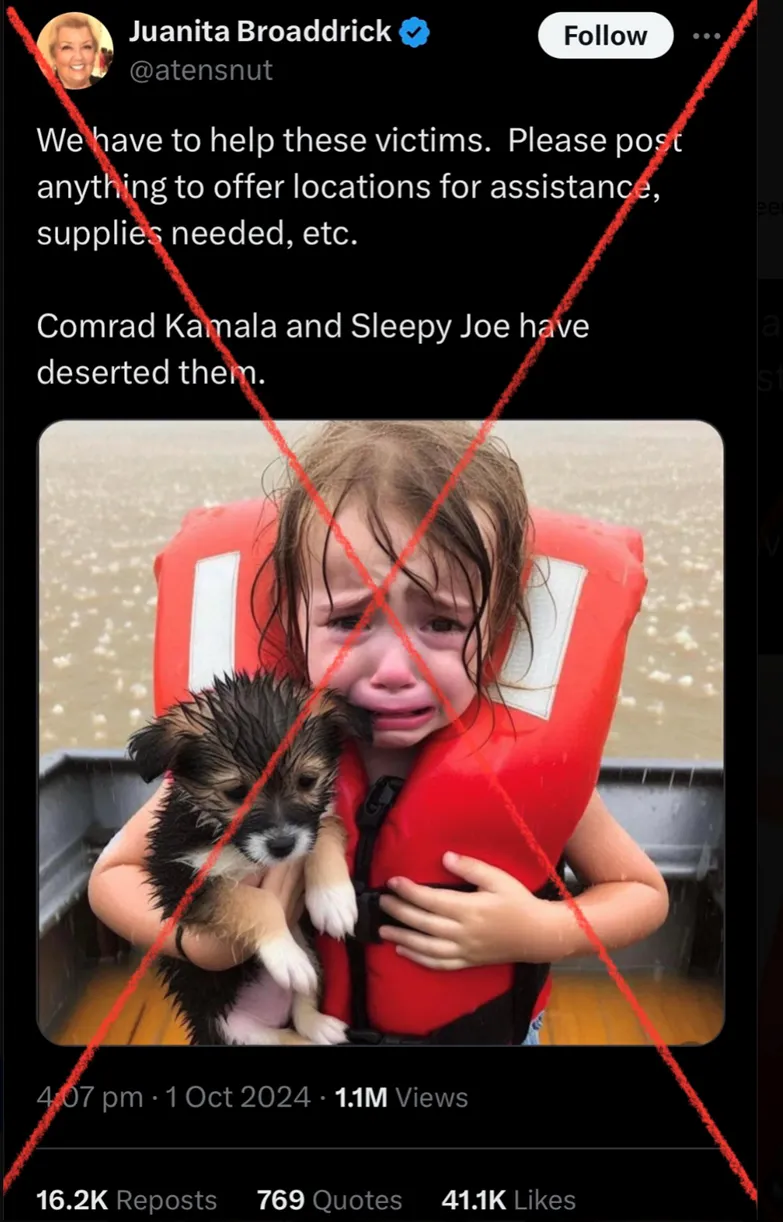
▷图5.AI生成的图片被广泛传播,塑造集体记忆。图源:X
人类应对虚假信息的方式,与自身的历史一样悠久。只是大模型的出现,让我们传统的启发式应对机制失效了。要应对大模型生成的虚假信息,需要多方合作,可以通过大模型智能体以及众包协作来进行事实审核,也需要向公众科普大模型的运行机制,使其不再拟人化大模型,并习惯采取非启发式的方式去判断信息真假。
我们需要创立优化的虚假信息监控制度,并重建大众对机构的信任。我们需要加深对真伪信息判断机制的理解,无论是个体层面、人际层面,以及制度层面。我们需要对每个解决方案的有效性进行心理学研究。缺少这些,迎接我们的,不是后真相时代,而是不可避免的虚假信息制度化。
参考文献:
1 Garry, Maryanne, et al. "Large language models (LLMs) and the institutionalization of misinformation." Trends in Cognitive Sciences (2024).
2 Brooks, Creston, Samuel Eggert, and Denis Peskoff. "The Rise of AI-Generated Content in Wikipedia." arXiv preprint arXiv:2410.08044 (2024).
3 Alvero, A. J., et al. "Large language models, social demography, and hegemony: comparing authorship in human and synthetic text." Journal of Big Data 11.1 (2024): 138.
文章来自于微信公众号“追问nextquestion”,作者“郭瑞东”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
