# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?
论文通讯作者、MIT 物理学教授 Max Tegmark 的推文。值得注意的是,Max Tegmark 也是著名的 KAN 论文的作者之一,是 KAN 论文一作 ZimingLiu 的导师。
在过去的一年,学术界在理解大型语言模型如何工作方面取得了突破性进展:稀疏自编码器(SAE)在其激活空间中发现了大量可解释为概念的点(「特征」)。最近,此类 SAE 点云已公开发布,因此研究其在不同尺度上的结构正当其时。
最近,来自 MIT 的一个团队公布了他们的研究成果。

具体来说,他们发现 SAE 特征的概念宇宙在三个层面上具有有趣的结构:
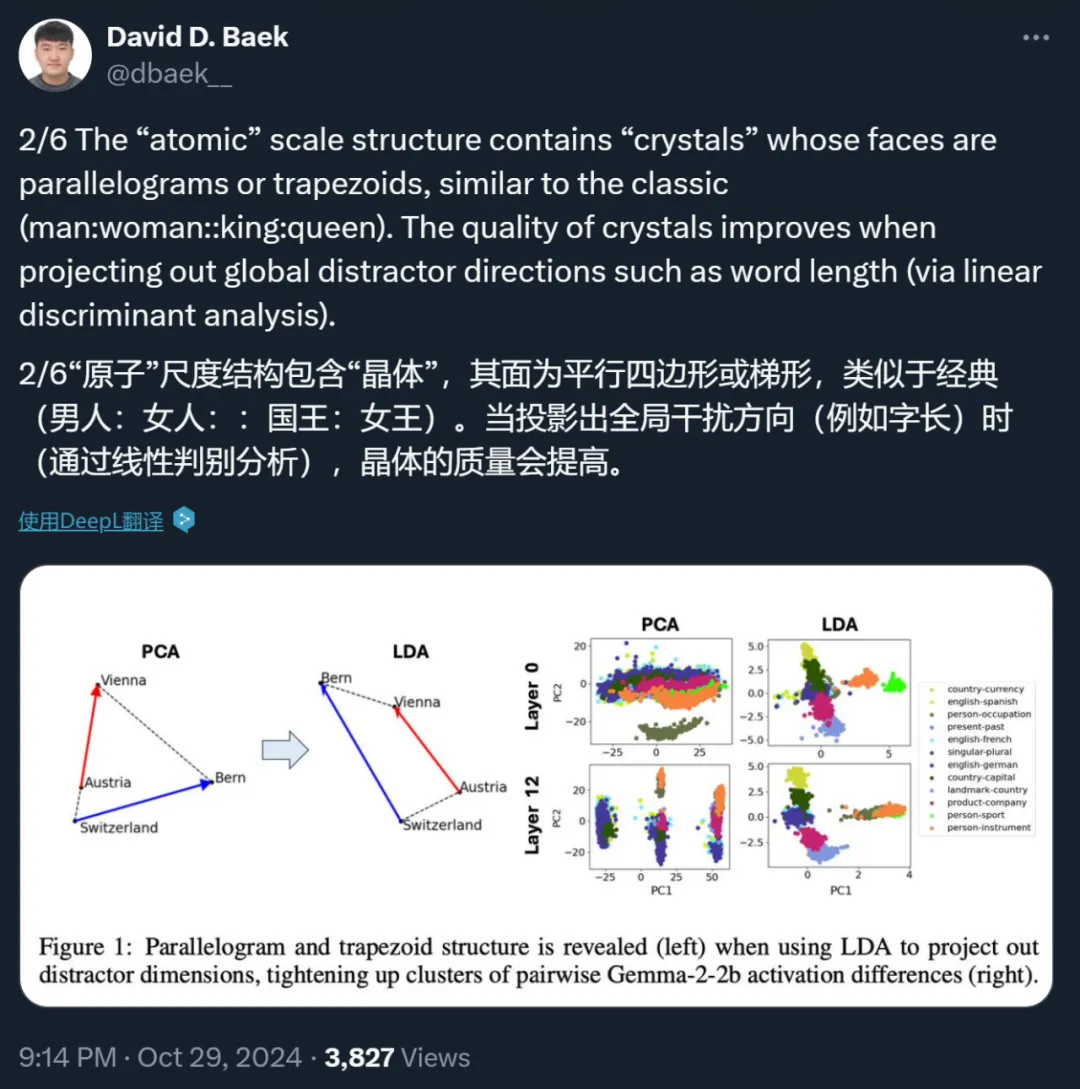
第一个是「原子」小尺度层面。在这个层面上,作者发现 SAE 特征的概念宇宙包含「晶体」结构,这些晶体的面是平行四边形或梯形,这泛化了众所周知的例子,如 (man:woman::king:queen)。他们还发现,当排除全局干扰方向,如单词长度时,这类平行四边形和相关功能向量的质量大大提高,这可以通过线性判别分析有效地完成。
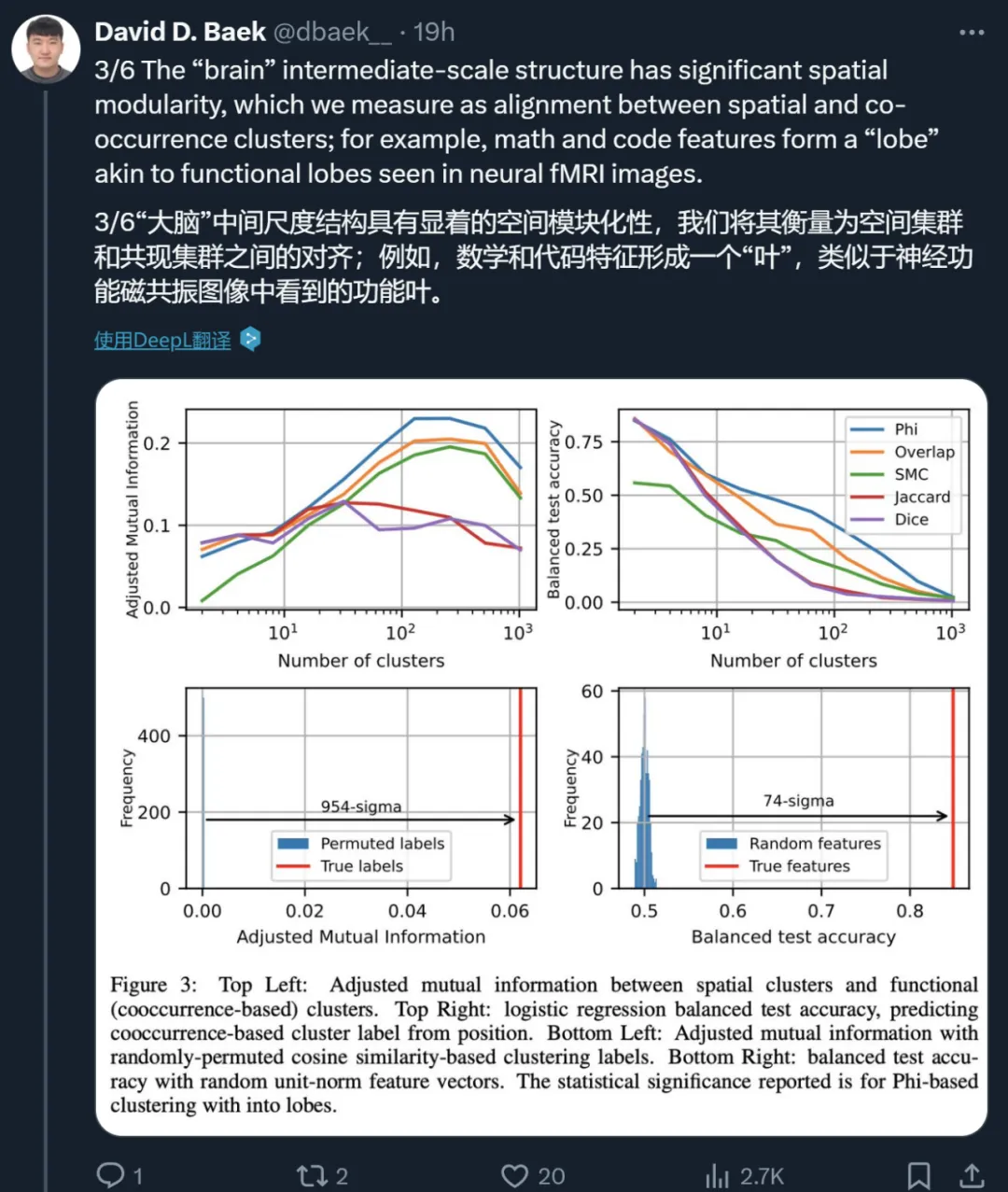
第二个是「大脑」中等尺度层面。在这个层面,作者发现 SAE 特征的概念宇宙具有显著的空间模块性。例如,数学和代码特征会形成一个「叶(lobe)」,类似于我们在做神经磁共振功能成像时看到的大脑功能性叶(如听觉皮层)。作者用多个度量来量化这些叶的空间局部性,并发现在足够粗略的尺度上,共现特征(co-occurring feature)的聚类在空间上也聚集在一起,远远超过了特征几何是随机的情况下的预期。
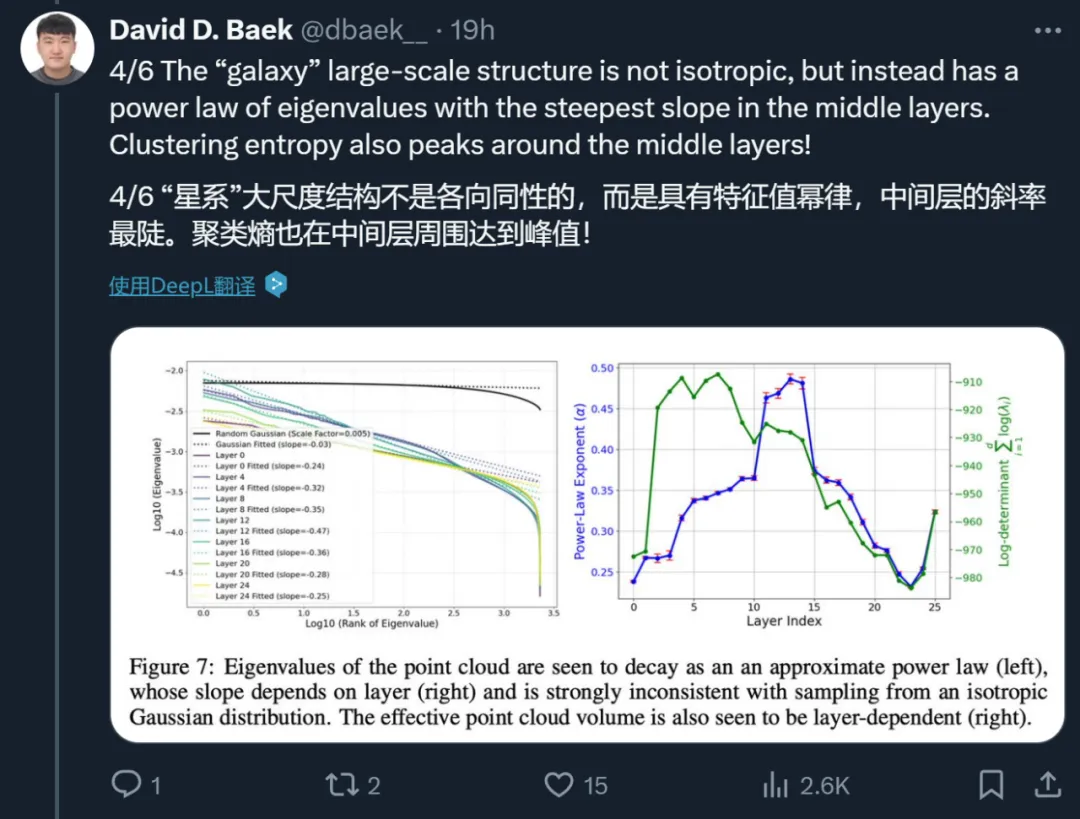
第三个是「星系」大尺度层面。在这个层面上,作者发现 SAE 特征点云的结构不是各向同性的,而是呈现出一种特征值的幂律分布,并且在中间层的斜率最陡。此外,他们还量化了聚类熵如何随层数的变化而变化。
这项研究吸引了不少研究者的注意。有人评论说,AI 系统在处理信息时自然地发展出几何和分形结构,而这些结构与生物大脑中的结构相似。这一现象表明,数学上的组织模式可能是自然界的基本特性,而不仅仅是人类的认知构造。

也有人提出了一些不同观点,认为这种结构可能更多是源于 AI 模型从人类数据中学习的结果,而不是一种完全独立的自然特性。反驳者认为,由于人类也是一种生物神经网络,当大规模 AI 系统基于小规模神经网络的输入数据进行训练时,它们自然而然地会接近这种结构模式,因此 AI 模型的结构并非完全出乎意料。反驳者还提出了一个有趣的设想:如果 AI 模型在完全不包含人类数据的「外星」数据集上进行训练,那么模型的组织结构可能会有很大的不同 —— 尽管模型仍然可能会产生聚类和分组的结构以有效处理复杂信息,但实际的概念和结构可能会和人类的完全不同。

论文作者表示,他们希望这些发现有助于大家深入理解 SAE 特征和大型语言模型的工作原理。他们也会在未来继续研究,以了解为什么其中一些结构会出现。

以下是论文的详细信息。
在这一部分中,作者寻找他们所说的 SAE 特征点云中的晶体结构。这里的结构指的是反映概念之间语义关系的几何结构,它泛化了(a, b, c, d)=(man,woman,king,queen)形成近似平行四边形的经典例子,其中 b − a ≈ d − c。这可以用两个功能向量 b − a 和 c − a 来解释,分别将男性实体转为女性,将普通人转为皇室成员。他们还寻找只有一对平行边 b - a ∝ d - c 的梯形(只对应一个功能向量);图 1(右)展示了这样一个例子,其中(a, b, c, d)=(Austria, Vienna, Switzerland, Bern),这里的功能向量可以被解释为将国家映射到它们的首都。

作者通过计算所有成对差分向量并对其进行聚类来寻找晶体,这应该会产生一个对应于每个功能向量的聚类。一个聚类中的任意一对差分向量应该形成一个梯形或平行四边形,这取决于差分向量在聚类前是否被归一化(或者是否通过欧氏距离或余弦相似性来量化两个差分向量之间的相似性)。
作者最初搜索 SAE 晶体时发现的大多是噪声。为了探究原因,他们将注意力集中在第 0 层(token 嵌入)和第 1 层,那里许多 SAE 特征对应于单个词汇。然后他们研究了 Gemma2-2b 残差流激活,这些激活是针对之前报告的来自 Todd 等人 (Todd et al., 2023) 数据集中的 word->word 功能向量,这澄清了问题。图 1 说明了候选晶体四元组通常远非平行四边形或梯形。这与多篇论文指出的(man, woman, king, queen)也不是一个准确的平行四边形是一致的。
作者发现,导致这一问题的原因是存在他们所说的干扰特征。例如,他们发现图 1(右)中的水平轴主要对应于单词长度(图 10),这在语义上是不相关的,并且对梯形(左)造成了破坏,因为「Switzerland」比其他单词长得多。
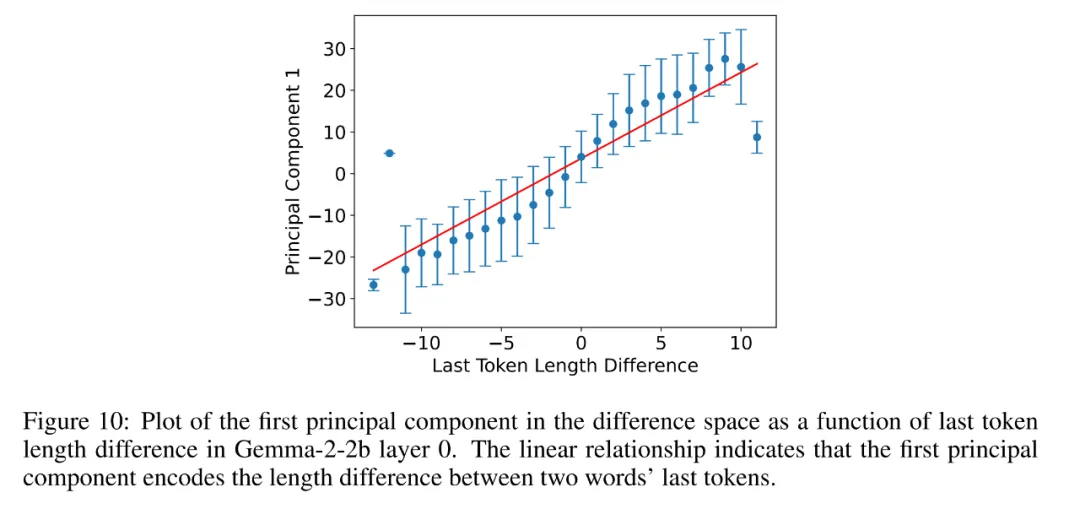
为了消除这些语义上不相关的干扰向量,他们希望将数据投影到一个与它们正交的低维子空间上。对于 (Todd et al., 2023) 数据集,他们使用线性判别分析(LDA)来实现这一点,它将数据投影到信号 - 噪声的特征模式上,其中「信号」和「噪声」分别定义为聚类间变化和聚类内变化的协方差矩阵。图 1 显示,这极大地提高了聚类和梯形图 / 平行四边形的质量,突出表明干扰特征可能会隐藏现有的晶体。
现在放大视野,寻找更大规模的结构。具体来说,作者研究了功能相似的 SAE 特征组(倾向于一起激活)是否在几何上也是相似的,从而在激活空间中形成「叶」。
在动物大脑中,这些功能组是众所周知的神经元所在 3D 空间中的聚类。例如,布洛卡区参与语言产生,听觉皮层处理声音,而杏仁体主要与情绪处理相关。作者好奇是否能在 SAE 特征空间中找到类似的功能模块性。
作者测试了多种自动发现此类功能「叶」以及量化它们是否具有空间模块性的方法。他们将叶分区定义为将点云分割为 k 个子集(「叶」),这些子集的计算不依赖于位置信息。相反,他们识别这些叶的依据是它们在功能上的相关性,具体来说,就是在一个文档中趋向于共同激活。
为了自动识别功能叶,作者首先计算 SAE 特征共现的直方图。他们使用 gemma-2-2b,并将 The Pile Gao et al. (2020) 中的文档传递给它。在这一部分,他们将报告第 12 层残差流 SAE 的结果,该层有 16k 个特征,平均 L0 为 41。
对于这个 SAE,他们记录了激活的特征(如果其隐藏激活 > 1,他们认为一个特征被激活)。如果两个特征在 256 个 token 组成的同一个块内被激活,则它们就被视为共现 —— 这个长度提供了一个粗略的「时间分辨率」,使他们能够找到在同一文档中倾向于一起激活的 token。他们使用 1024 的最大上下文长度,并且每个文档只使用一个这样的上下文,因此每篇 The Pile 文档最多只能有 4 个块(和直方图更新)。他们计算了 50k 个文档的直方图。给定这个直方图,他们基于它们的共现统计计算每对 SAE 特征之间的亲和度(affinity),并对得到的亲和度矩阵进行谱聚类。
作者尝试了以下基于共现的亲和概念:简单匹配系数、Jaccard 相似性、Dice 系数、重叠系数和 Phi 系数,所有这些都可以仅从共现直方图计算得出。
作者的 null 假设是,功能相似的点(通常共现的 SAE 特征)在激活空间中均匀分布,没有空间模块性。相反,图 2 显示了看起来相当空间局部化的叶。为了量化这一点在统计上的重要性,作者使用两种方法来排除 null 假设。

1、虽然我们可以根据它们是否共现来聚类特征,但也可以根据 SAE 特征解码向量之间的余弦相似度执行谱聚类。给定一个使用余弦相似度的 SAE 特征聚类和一个使用共现的聚类,计算这两组标签之间的互信息。从某种意义上说,这直接衡量了人们从了解功能结构中获得的几何结构的信息量。
2、另一个概念上简单的方法是训练模型,从其几何形状预测一个特征所在的功能叶。为此,作者从基于共现的聚类中获取一组给定的叶标签,并训练一个 logistic 回归模型,直接从点位置预测这些标签,采用 80-20 的训练 - 测试比例,并报告该分类器的平衡测试准确率。
图 3 显示,在这两种测量方法中,Phi 系数胜出,在功能叶和特征几何之间实现了最佳对应。为了证明这一点具有统计学意义,作者从基于余弦相似性的聚类中随机排列聚类标签,并测量调整后的互信息。他们还从随机高斯中随机重新初始化 SAE 特征解码器方向并归一化,然后训练 logistic 回归模型,从这些特征方向预测功能叶。图 3(下)显示,这两个测试都以高显著性排除了 null 假设,标准差分别为 954 和 74,这清楚地表明作者看到的叶是真实的,而不是统计上的偶然。
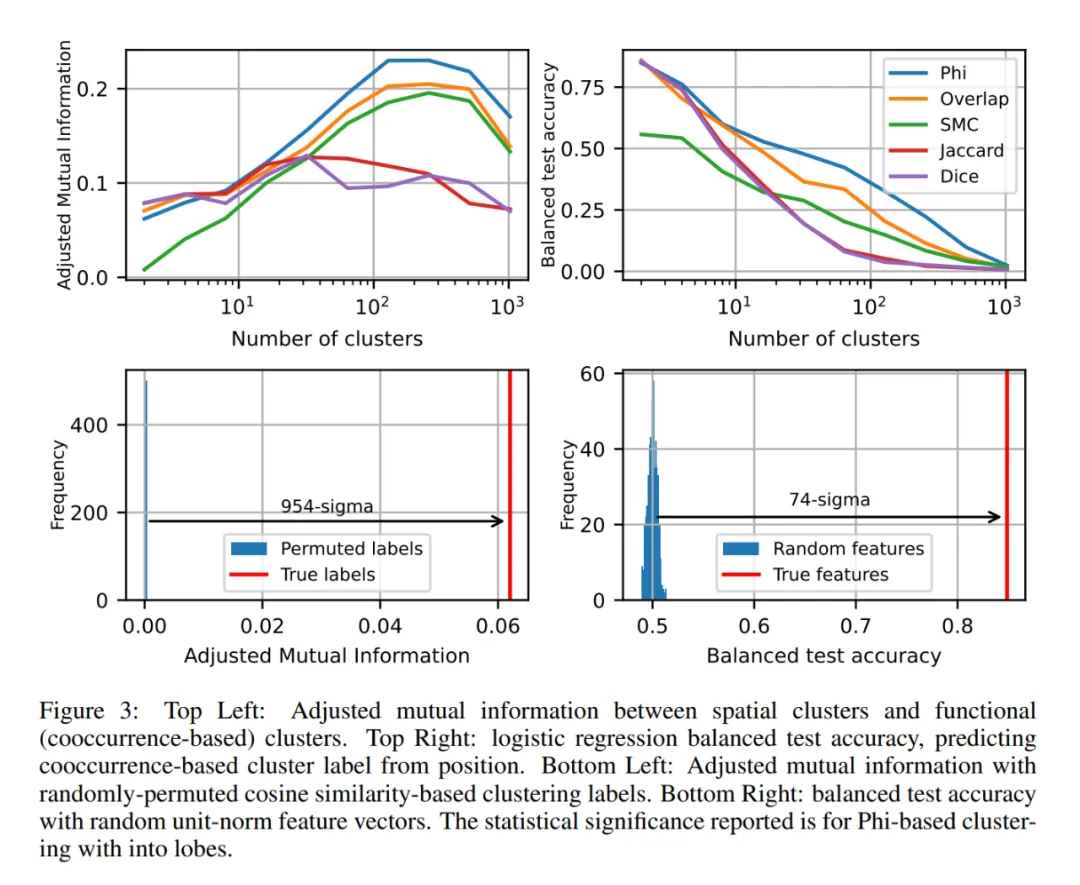
为了评估每个叶专门做什么,作者通过 gemma-2-2b 运行来自 The Pile 的 10k 个文档,并再次记录第 12 层的哪些 SAE 特征在 256 个 token 组成的块内激活。对于每个 token 块,他们记录哪个叶有最高比例的特征激活。
作者在图 4 中展示了三个叶的结果,这些结果是使用 Phi 系数作为共现度量的,这构成了图 2 中叶标记的基础。

图 5 比较了五种不同的共现度量的效果。尽管作者发现 Phi 是最好的,但所有五种都发现了「代码 / 数学叶」。

「星系」尺度:大规模点云结构
在本节中,作者进一步放大视野,研究点云的「星系」尺度结构,主要是其整体形状和聚类,类似于天文学家研究星系形状和亚结构的方式。
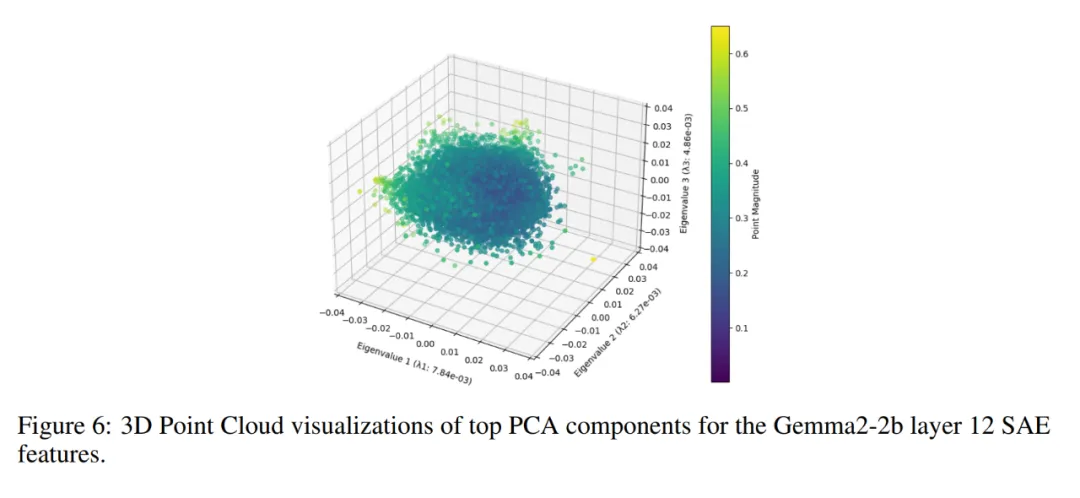
作者试图排除的简单 null 假设是,点云仅仅是从一个各向同性的多元高斯分布中抽取的。图 6 从视觉上直观地表明点云的形状并不仅仅是圆形,即使在其前三个主成分中,一些主轴也比其他的略宽,类似于人脑。
形状分析
图 7(左)通过展示点云协方差矩阵的特征值递减来量化这一点,揭示它们并不恒定,而是似乎按照幂律下降。为了测试这种令人惊讶的幂律是否显著,该图将其与从各向同性高斯分布中抽取的点云的相应特征值谱进行比较,后者看起来更为平坦,与分析预测一致:多元高斯分布的 N 个随机向量的协方差矩阵遵循 Wishart 分布,这在随机矩阵理论中得到了很好的研究。由于最小特征值的突然下降是由数据有限引起的,并在 N → ∞的极限中消失,作者将点云降维到其 100 个最大的主成分进行后续的所有分析。换句话说,点云的形状像是一个「分形黄瓜」,在连续的维度中宽度按照幂律下降。作者发现这种幂律缩放对于激活来说明显不如对于 SAE 特征那么突出;进一步研究其起源将很有趣。
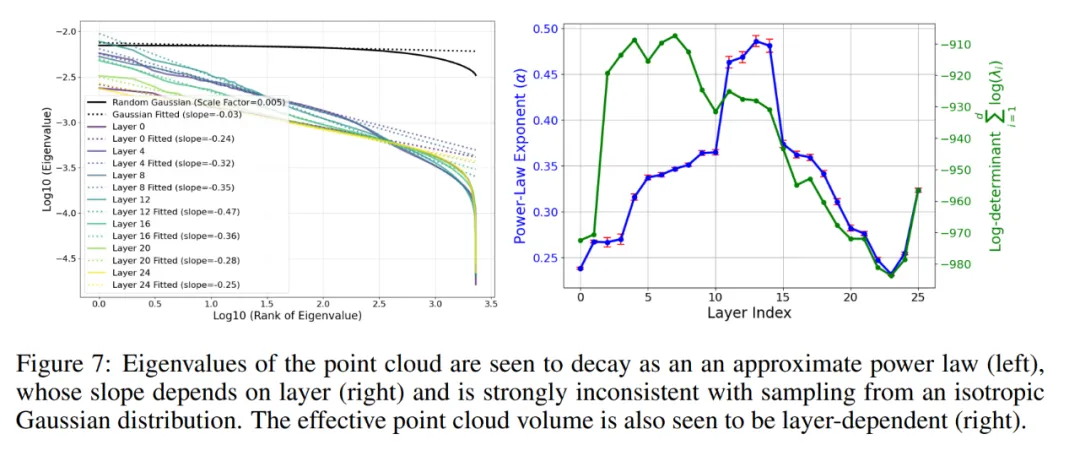
图 7(右)显示了上述幂律斜率如何取决于 LLM 层,计算方法是对 100 个最大特征值进行线性回归。可以看到一个明显的模式,即中间层具有最陡峭的幂律斜率:(第 12 层的斜率为 - 0.47,而前面和后面的层(如第 0 层和第 24 层)的斜率较浅(分别为 - 0.24 和 - 0.25)。这可能暗示了中间层起到了瓶颈的作用,将信息压缩为较少的主成分,或许是为了更有效地表示高层次抽象概念而进行的优化。图 7(右)还显示了有效云体积(协方差矩阵的行列式)如何依赖于层(在对数尺度上。
聚类分析
星系或微观粒子的聚类通常以功率谱或相关函数来量化。对于论文中的高维数据来说,这种方法比较复杂,因为基本密度随半径变化,对于高维高斯分布来说,基本密度主要集中在一个相对较薄的球壳周围。因此,作者通过估算点云采样分布的熵来量化聚类。他们使用 k-NN 方法从 SAE 特征点云估计熵 H,计算如下,

对于具有相同协方差矩阵的高斯分布,熵计算为:
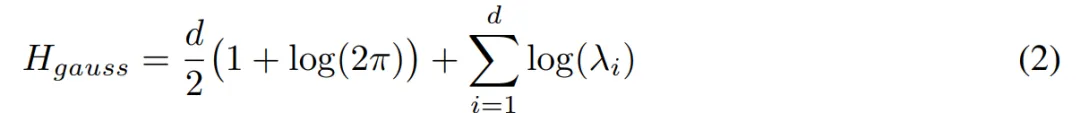
图 8 显示了不同层的估计聚类熵。作者发现 SAE 点云特别在中间层有很强的聚类。

文章来自于“机器之心”,作者“张倩、蛋酱”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
