# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家对in-context learning(ICL)的能力可能已经很熟悉了,您通常会通过上下文示例就能快速让prompt适应新任务。然而,作为AI应用开发者,您是否思考过:为什么有时候精心设计的few-shot prompt会失效?为什么相同的prompt模式在不同场景下效果差异巨大?
最近,来自Google DeepMind和阿尔伯塔大学的研究团队带来了一项重要发现,首次从理论和实践层面揭示了上下文学习(In-Context Learning, ICL)和权重学习(In-Weight Learning, IWL)这两种学习机制的内在关系。

对于AI产品开发者和Prompt Engineers来说,深入理解ICL和IWL的原理和应用,能够帮助我们更好地利用和优化Transformer模型,提升其在实际任务中的表现。本文将基于DeepMind最新的研究成果,深入探讨ICL和IWL在Transformer模型中的作用机制,揭示它们如何相互影响和转化,并用示例为开发者提供实践性的建议和启示。

ICL是指模型在推理阶段利用输入的上下文信息,临时学习新的任务或知识,而无需更新模型参数。这使得模型能够在零样本或少样本情况下完成特定任务。相比之下,IWL是传统的机器学习方式,模型通过训练过程更新自身权重参数,从而长期记忆和应用所学知识。
早期的研究如Radford等人(2019)和Brown等人(2020)的工作揭示了大型语言模型在ICL方面的能力。但对于ICL和IWL在Transformer中的相互关系以及不同条件下的表现,仍缺乏系统的理论和实证分析。
Chan等人(2022a)提出,数据的分布特征对模型的学习机制有重要影响。他们发现,当数据具有高类内变异和大量类别时,Transformer模型更倾向于使用ICL。这为进一步研究ICL和IWL的交互奠定了基础。
理解ICL和IWL的动态关系,对于优化模型训练、提升性能具有重要意义。特别是在需要模型快速适应新环境的场景中如何促进ICL,以及在需要稳定长期记忆的任务中如何增强IWL,是AI开发者关注的核心问题。
DeepMind的研究团队提出了一个简化的理论模型,模拟Transformer在ICL和IWL之间的选择过程。该模型包含两个预测器:ICL预测器利用输入的上下文进行即时学习和预测;IWL预测器则基于模型权重参数进行长期记忆的预测。通过引入一个门控机制,模型可以根据输入和上下文,动态地在两种预测器之间切换。
为了分析模型在不同条件下的学习倾向,研究团队采用了一般化误差分析和遗憾分析。一般化误差分析评估模型在未见数据上的性能,衡量其泛化能力;遗憾分析则比较模型的实际累积损失与最优策略的累积损失差距,评估其学习效率。通过这些分析,可以推导出在不同数据分布和训练条件下,模型更倾向于使用ICL还是IWL。
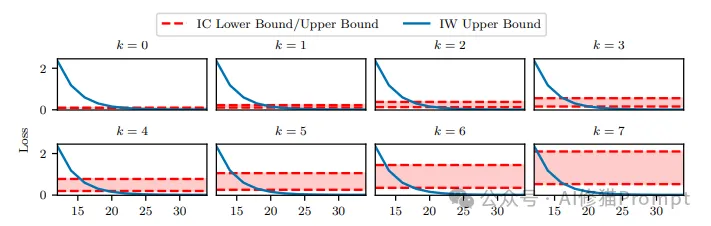
上图展示了在上下文学习(In-Context Learning, ICL)和权重学习(In-Weight Learning, IWL)模式下,不同的无关上下文数量k和训练样本数量N_x如何影响模型的误差。
解释一下:
1.横轴表示训练样本数量N_x的对数值(以2为底),纵轴表示模型的预测误差。
2.每个子图对应不同的无关上下文数量k,从0到7。k值越大,表示上下文中包含的无关信息越多。
3.红色虚线表示IWL模式下模型误差的理论上界,随着训练样本数量的增加而下降。这表明当训练数据越多时,IWL模式的性能会越好。
4.蓝色实线表示ICL模式下模型误差的理论下界和上界。随着无关上下文数量k的增加,ICL模式的误差下界和上界也在提高。这说明上下文的质量(相关性)会显著影响ICL模式的性能。
5.当训练样本数量较少时,ICL模式的误差可能低于IWL模式。但随着样本数量增加,IWL模式的误差下降较快,逐渐表现出优势。这表明ICL更适合小样本学习,而IWL在大样本场景下更有优势。
该图直观地展示了无关上下文数量和训练样本数量如何影响ICL和IWL模式下模型的性能,揭示了两种学习机制的适用条件和特点。这为我们理解和应用ICL和IWL提供了有益的理论参考。
在上一张图中,我们看到了无关上下文数量和训练样本数量如何影响ICL和IWL模式的性能。这张图进一步展示了其他一些关键因素对Transformer模型学习机制的影响。
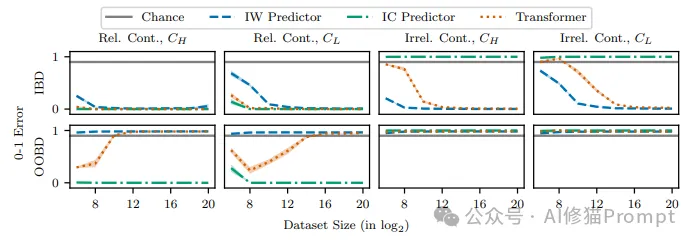
1.第一列显示了不同的高频类别采样概率p_high对模型性能的影响。当类别分布更加均衡(p_high=0.5)时,ICL的性能略好,而IWL需要更多的训练样本才能达到较低的误差。这可能是因为均衡的类别分布使得模型更难以通过权重记忆每个类别的特征。
2.第二列展示了不同的相关上下文采样概率p_relevant对模型性能的影响。当p_relevant较大时,即上下文的相关性更高,ICL的性能明显更好。这印证了上下文质量对ICL至关重要。
3.第三列比较了不同的上下文长度L对模型性能的影响。上下文长度越大,ICL的性能越差,这可能是因为更长的上下文包含更多无关信息,干扰了模型的推理。
4.第四列固定上下文长度为4,研究了相关上下文数量L_relevant的影响。当L_relevant减小时,即使总是提供相关上下文,ICL的性能也会显著下降。这表明即使上下文整体相关,模型也需要足够数量的相关示例才能有效学习。
通过对比不同设置下ICL和IWL的性能,我们可以得到以下发现:
1.类别分布、上下文相关性、上下文长度和相关示例数量都会显著影响ICL的性能。这启示我们在应用ICL时,需要注意优化上下文的设计,提供足够的相关示例。
2.IWL对这些因素的敏感度相对较低,但需要更多的训练样本来达到较好的性能。这启示我们在大样本场景下,可以优先考虑IWL。
3.在实践中,我们可以根据任务的特点和数据的分布,灵活选择ICL或IWL,或者将两者结合,发挥各自的优势。
这项研究通过系统地分析各种因素对ICL和IWL的影响,为我们理解和应用Transformer模型提供了重要的实验依据和实践指导。
以上实验设计,研究团队使用了合成数据和真实数据。合成数据实验中,他们创建具有特定分布特征(如长尾分布、高类内变异等)的数据集,在不同训练设置下观察Transformer模型的学习机制变化。评估时使用ID(In-Distribution)数据和OOD(Out-of-Distribution)数据,全面考察模型的预测性能。
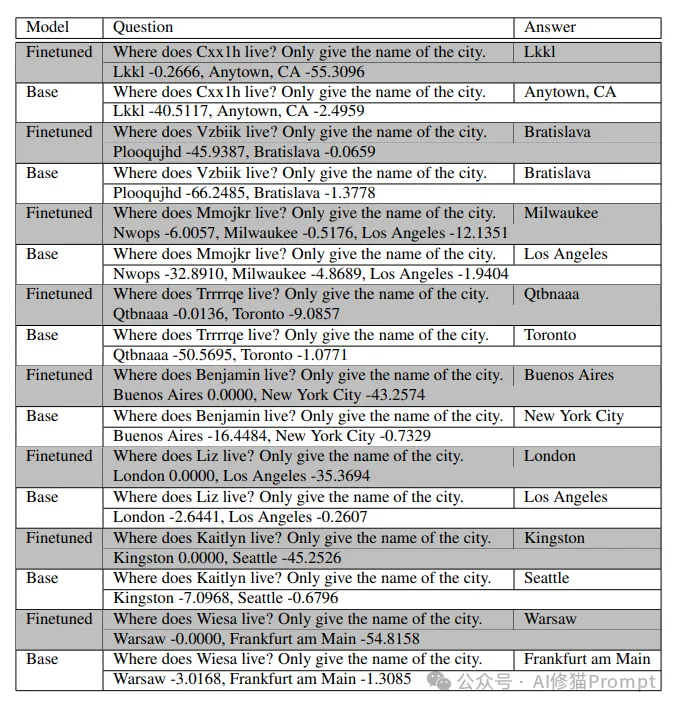
在真实数据实验中,研究团队使用了Omniglot手写字符数据集和Gemini Nano 1语言模型。通过微调模型学习实体之间的关系(如人名与城市的对应),并观察模型在提供上下文提示和不提供提示时的预测行为,以揭示ICL和IWL的作用。微调数据集的问答对和基本模型的相应预测,还显示了可能答案的相对对数概率。看下图,阴影行是微调的模型预测,未阴影的行是基本模型预测。在这种情况下,模型必须使用WL来预测正确答案。
DeepMind的研究揭示了ICL和IWL出现的关键条件。当数据具有高类内变异、长尾分布和大量类别时,模型更倾向于使用ICL。这是因为模型难以在权重中有效记忆所有类别信息,因而依赖上下文提示进行即时学习。相反,当数据类别较少、类内变异低时,模型可以通过训练将类别信息固化在权重中,更倾向于使用IWL。
研究还发现,随着训练时间的增加,模型可能从依赖ICL逐渐转向依赖IWL。这表明ICL可能在早期作为一种过渡机制,帮助模型处理未见过的数据,随着训练的深入,模型将这些信息固化在权重中。另一方面,当特定数据模式反复出现时,模型更可能将其记忆在权重中,减少对上下文提示的依赖。
通过微调实验,研究团队进一步揭示了微调对学习机制的影响。微调可以增强IWL的效果,使模型更倾向于使用权重中的信息进行预测;同时,微调也可能减少模型对ICL的依赖,即使提供了上下文提示,模型也可能忽略这些信息。
DeepMind的研究为AI产品开发者提供了宝贵的见解。首先,我们可以通过调整训练数据的分布特征,来控制模型对ICL和IWL的依赖程度。这使得我们能够根据具体应用需求,设计出更加灵活和高效的模型。
其次,深入理解ICL和IWL的机制,有助于我们开发出能够在不同任务中动态调整学习策略的模型。这种灵活性对于实际应用至关重要,能够帮助模型更好地适应复杂多变的现实世界。
此外,Prompt Engineers可以利用这一研究成果,设计出更有效的提示词,增强模型的性能。通过精心设计上下文信息,我们可以引导模型使用ICL或IWL,从而实现更精准、更高效的预测。比如,像这样写成提示词:
当然,将这些研究成果应用到实践中仍面临一些挑战。比如在实际应用中,数据的分布往往复杂多变,控制数据特征可能具有一定难度。此外,增强IWL可能需要更长的训练时间和更多的计算资源,我们需要在性能和成本之间进行权衡。
DeepMind的这项研究深入分析了ICL和IWL在Transformer模型中的作用机制,揭示了它们在不同条件下的出现和相互转化规律。对于AI产品开发者来说,理解并利用这些机制,能够优化模型性能,满足多样化的应用需求。
通过调整训练数据的分布、微调模型和设计有效的提示词,我们可以控制模型对ICL和IWL的依赖,实现模型灵活性和稳定性的平衡。未来的研究方向可能包括探索模型在推理过程中自适应地在ICL和IWL之间切换的动态学习机制,将ICL和IWL的分析扩展到多模态数据,以及利用这些机制设计更自然的人机交互方式等。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
