每人最多20篇?ICLR新规遭DeepMind研究者「反讽」请愿
每人最多20篇?ICLR新规遭DeepMind研究者「反讽」请愿近日,ICLR 2027 公布新的投稿规则,明确规定,任何作者最多只能出现在 20 篇投稿的作者名单中,超出配额的论文会在摘要提交阶段收到提醒。如果到全文截止时仍未调整,会议将随机拒绝部分论文,直到每位作者都回到限额以内……
来自主题: AI资讯
7355 点击 2026-08-02 11:17
 搜索
搜索
近日,ICLR 2027 公布新的投稿规则,明确规定,任何作者最多只能出现在 20 篇投稿的作者名单中,超出配额的论文会在摘要提交阶段收到提醒。如果到全文截止时仍未调整,会议将随机拒绝部分论文,直到每位作者都回到限额以内……
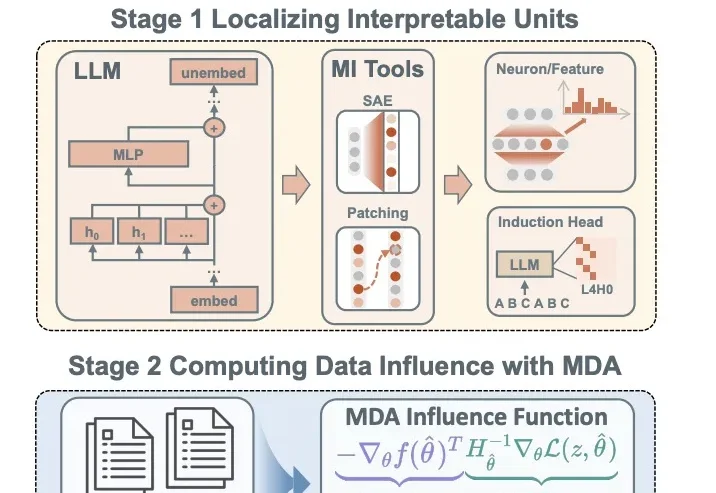
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
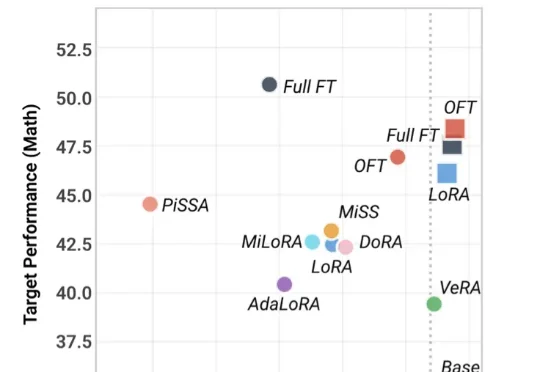
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。

还在手动在不同工具间来回切换查文献、跑代码、看结果?两个月前发起内侧的科研龙虾SciClaw,经过上万名科研人的「考核」,正式升级为Mira,推出专家小队、科研画布、LLM WIKI 三大核心能力,首次将「Vibe Researching」理念产品化,让研究者像组建实验室团队一样配置 AI,把时间还给真正的科学思考。

Z Potentials独家获悉,侵入式脑机接口创业公司SiClink(曦涟科技)近日连续完成数千万元种子轮和天使轮融资,蓝驰创投、高瓴创投、中科神光联合押注。
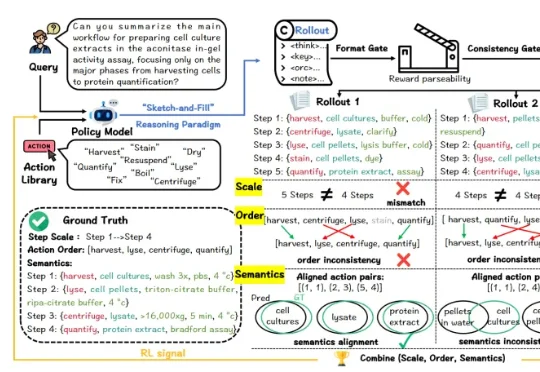
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :

大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
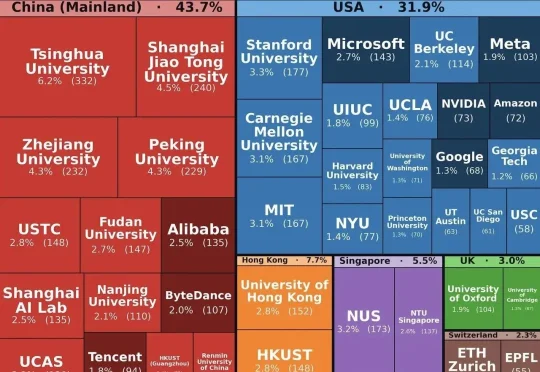
ICLR 2026,全球AI三大顶会之一,刚刚在巴西里约落幕。有社区研究者逐篇扒开5356篇被接收论文PDF首页、提取机构署名、清洗归一后,一张Treemap热力图炸翻了整个学术圈:中国大陆,43.7%。美国,31.9%。欧洲(含英国),5.3%。