# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,生成式人工智能(AIGC)引发广泛关注。Midjourney、Imagen3、Stable Diffusion和Sora等模型能够根据自然语言提示词生成美观且逼真的图像和视频,广受用户喜爱。

然而,这些模型在处理复杂的提示词时仍存在不足。例如,当让Stable Diffusion或Midjourney生成「棕色的狗绕着一棵树追黑色的狗」时,模型可能会错误生成两只黑狗,或将「追逐」误解为两只狗在「玩耍」。

有什么办法可以自动发现这些模型的不足,并进一步提升它们呢?
为解决这一问题,CMU和Meta团队联合推出了全新的评估指标VQAScore及基准GenAI-Bench,用于自动评估图像、视频和3D生成模型在复杂提示词下的表现。


ECCV’24论文链接::https://arxiv.org/abs/2404.01291
CVPR’24 SynData最佳论文链接:https://arxiv.org/abs/2406.13743
论文代码:https://github.com/linzhiqiu/t2v_metrics
模型下载:https://huggingface.co/zhiqiulin/clip-flant5-xxl
VQAScore模型:https://huggingface.co/zhiqiulin/clip-flant5-xxl
GenAI-Bench数据集:https://huggingface.co/datasets/BaiqiL/GenAI-Bench
这些成果已在ECCV和CVPR等顶会上发表,并被谷歌DeepMind用于评估其最新的Imagen3模型,被誉为当前文生图领域超越CLIP等模型的最佳评估方案!
近年来,文生图模型(如DALL-E 3、Imagen3、Sora等)发展迅速,但如何准确评估这些模型的表现仍是一个关键问题。
尽管许多公司采用人类评估(Human Evaluation)来提升结果的准确性,但这种方式成本高、难以大规模应用,而且缺乏可复现性。
在图片生成领域,已有多种方法使用模型来自动评估(Automated Evaluation)生成图像的表现,其中常见的指标包括CLIPScore、FID、LPIPS、PickScore、ImageReward和HPSv2等。
然而,这些指标真的足够好吗?
在评估两张图片的相似性(similarity)时,传统指标LPIPS等方法依靠预训练的图像编码器,将图像特征嵌入后再计算距离。然而,这类方法只能评估图像与图像之间的相似度(image-to-image metric),而无法判断文本和图像之间的相似度(text-to-image metric)。
为了解决这一问题,当前主流的文生图评估采用了CLIPScore,通过独立的图像编码器和文本编码器,将图像和文本嵌入到同一特征空间,并通过计算特征相似度来判断它们的匹配程度。

然而,CLIPScore存在严重的「bag-of-words」问题:也就是说,CLIP在处理文本时可能忽略词序,混淆像「月亮在牛上面」和「牛在月亮上面」这样的句子。这使得模型难以准确抓住复杂文本中的关键信息。
为了解决这一问题,CMU和Meta的研究团队提出了VQAScore,采用更强大的生成式VQA模型(如GPT-4o)来更准确地评估文生图模型:

研究团队基于GPT-4o等用于视觉问答(VQA)任务的生成式视觉语言模型,将图像与提示词之间的相似度定义为模型在回答「这个图像是否显示了[提示词]?请回答是或否。」时给出「是」(Yes)答案的概率:
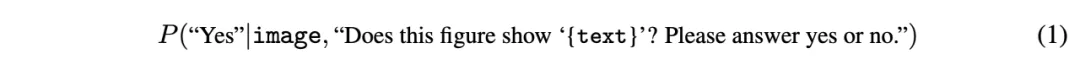
例如,在计算某张图像与提示词「牛在月亮上面」之间的相似度时,VQAScore会将图像和问题「这个图像是否显示了『牛在月亮上面』?请回答是或否。」输入模型,并返回模型选择「是」的概率。
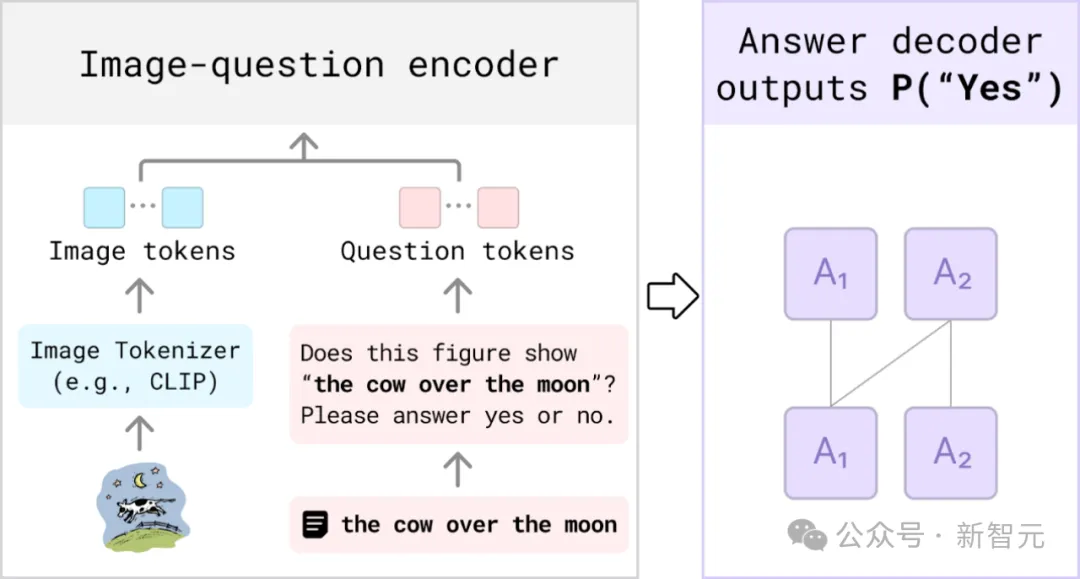
另外,研究团队发现,当前主流的VQA模型(如LLaVA-1.5)使用了具备单向(auto-regressive)注意力机制的语言模型(如Llama)。这种机制导致模型在提取图像特征时,无法提前获取提示词的完整信息。
为了更有效的提取视觉特征,研究团队使用开源数据训练了一个更强的CLIP-FlanT5 VQA模型。该模型采用了具备双向注意力机制的语言模型FlanT5,使得图像特征提取能够根据输入的提示词动态调整。
研究表明,这一机制在提升VQA模型对复杂提示词的理解方面效果显著。
VQAScore比主流评估指标更简单高效。许多传统指标依赖大量人类标注(如 ImageReward、PickScore)或私有模型(如GPT-4Vision)才能取得好表现。
相比之下,VQAScore具备以下核心优势:
1. 无需人类标注:VQAScore能直接利用现有的VQA模型取得优异表现,无需在人工标注数据上进行额外微调。
2. 分数更精准:使用GPT-4给图片打分(如在0到100之间打分)时,模型往往会随意给出高分(如90),而忽略图片的真实质量。相比之下,VQAScore使用概率值来判断图片与提示词的相似度,结果更加精确。
研究人员在大量复杂图文匹配基准(如Winoground和EqBen)以及文生图评估基准(如Pick-a-pic和TIFA160)上对VQAScore进行了测试。
结果显示,VQAScore在所有图像、视频和3D生成任务的基准上超越了CLIPScore等流行指标,取得了最佳表现。

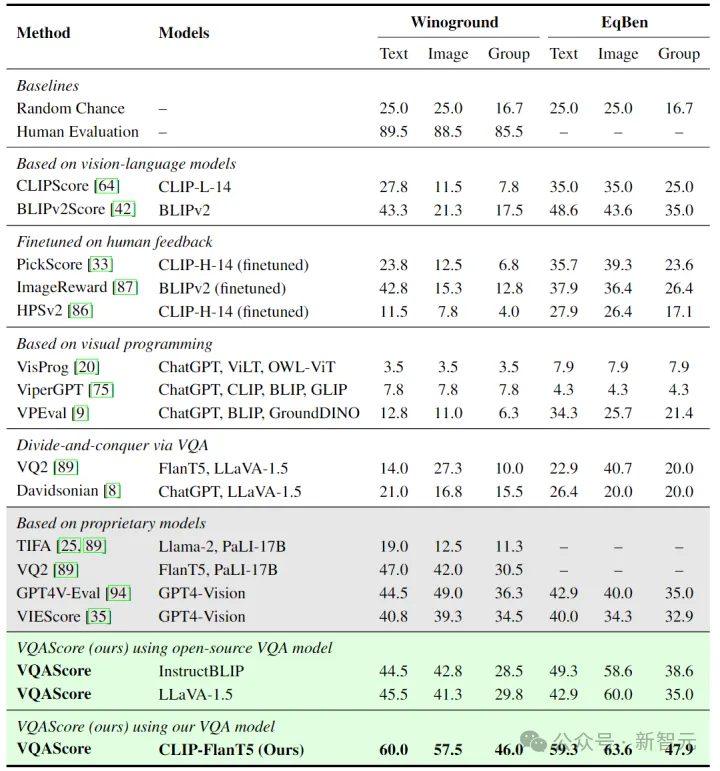
值得注意的是,VQAScore采用了开源模型(CLIP-FlanT5),却仍大幅超越了使用更强闭源模型(如PALI-17B和GPT-4)的方法(如VQ2、ViperGPT 等)。
此外,VQAScore也超越了依赖提示分解进行视觉推理的先进方法(如 CVPR'23最佳论文Visual Programming和ViperGPT等),进一步验证了端到端评估方案的有效性。
最新的谷歌DeepMind Imagen3报告还指出,使用更强大的VQA模型(如 Gemini)可以进一步提升VQAScore的表现,凸显了其在未来生成式模型评测中的潜力。
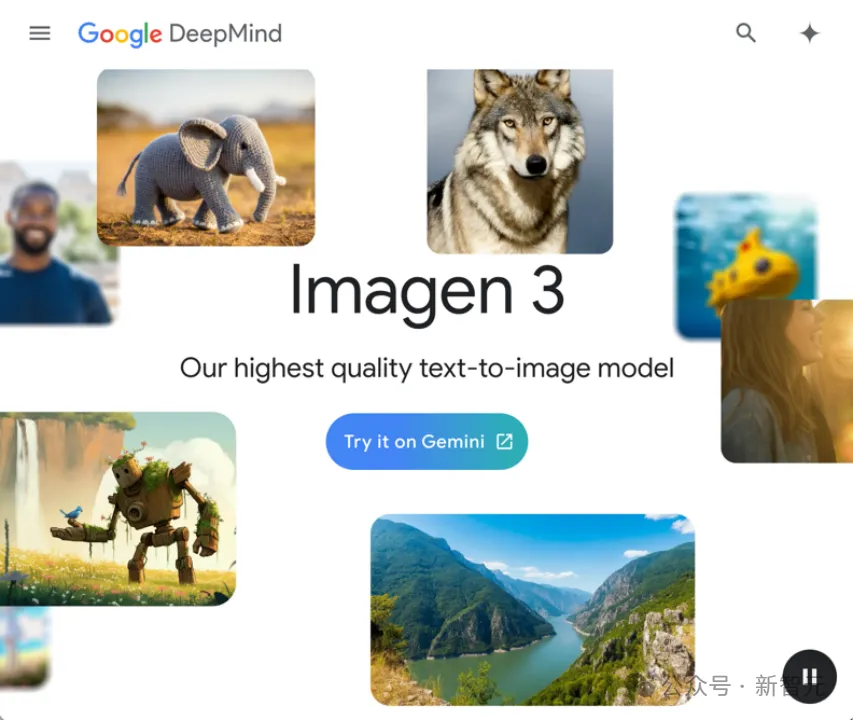
为了更好地评估文生图模型及其评估指标的性能,研究团队推出了GenAI-Bench。该基准包含1600个由设计师收集的复杂提示词,覆盖了10种生成模型(如DALL-E 3、Midjourney、SDXL等),并配有超过80,000条人工标注。
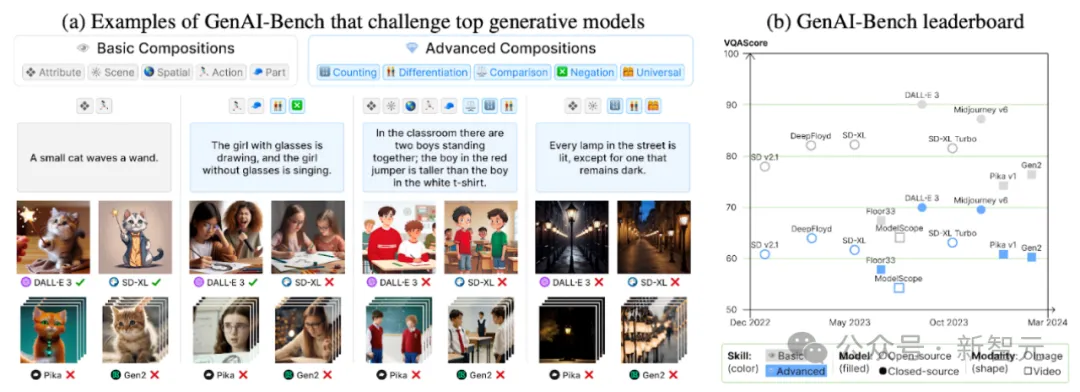
GenAI-Bench相比较之前的基准有以下优势:
1. 更具挑战性:研究表明,大多数文生图/视频模型在GenAI-Bench上表现仍有不足,还有大量的提升空间。
2. 避免空洞词汇:所有提示词均经过严格筛选,避免使用假大空的词语,确保评估更具客观性。
3. 细粒度技能分析:GenAI-Bench能提供更细致的技能分类和分析,帮助研究人员深入了解模型在不同能力上的具体表现。
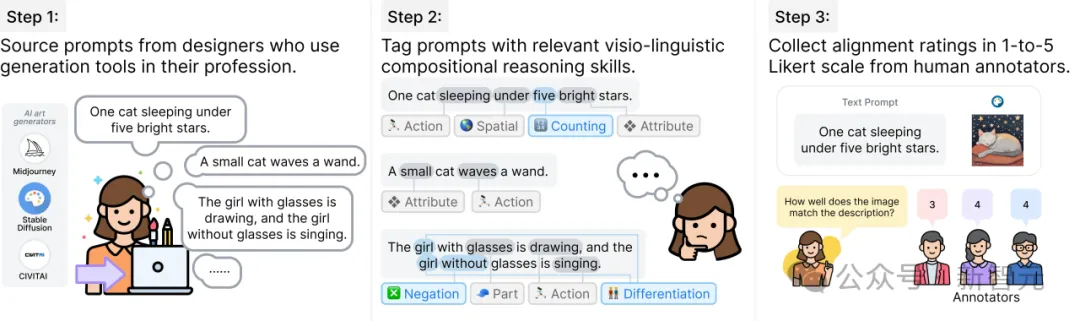
研究人员构建了一个新的GenAI-Rank基准,为每个提示词使用DALL-E 3和Stable Diffusion(SD-XL)生成3到9张候选图像。
研究表明,从这些候选图像中返回VQAScore得分最高的图像,可以显著提升文生图模型的效果。

这一方法无需微调生成模型本身,因此也能优化(黑箱)私有模型,如DALL-E 3。
实验结果进一步证明,VQAScore在图像排序上比其他方法(如CLIPScore、PickScore等)更加有效。
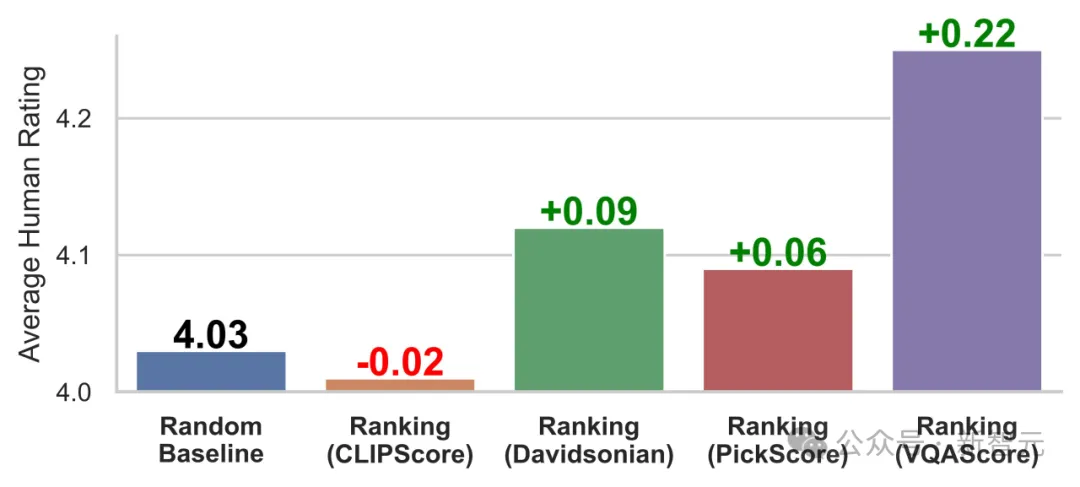
VQAScore和GenAI-Bench为文生图模型提供了更精准且全面的评估,已被Imagen3、VILA-U、RankDPO等多个项目用于更好地评估和优化最新的生成式模型。研究团队已开源代码和数据集,期待未来更多探索与进展!

团队的一作林之秋(Zhiqiu Lin)是卡内基梅隆大学的博士研究生,由Deva Ramanan教授指导,专注于视觉-语言大模型的自动评估与优化。Zhiqiu Lin在CVPR、NeurIPS、ICML、ECCV等顶级会议上发表了十数篇论文,并曾荣获最佳论文提名和最佳短论文奖等。其研究成果在生成模型和多模态学习领域受到了学术界和工业界的广泛认可。

Pengchuan Zhang是Meta AI(原Facebook AI研究院)的人工智能研究科学家,曾在微软研究院担任高级研究科学家。他的研究领域主要集中在深度学习、计算机视觉和多模态模型等方向,曾发表多项具有深远影响力的成果,例如AttnGAN、OSCAR、VinVL、Florence和GLIP等。他在顶级会议如CVPR、ICCV、NeurIPS等发表了大量高影响力论文,是计算机视觉和多模态模型领域的领军人物之一。

Deva Ramanan教授是计算机视觉领域的国际知名学者,现任卡内基梅隆大学教授。他的研究涵盖计算机视觉、机器学习和人工智能领域,曾获得多项顶级学术荣誉,包括2009年的David Marr奖、2010年的PASCAL VOC终身成就奖、2012年的IEEE PAMI青年研究员奖、2012年《大众科学》评选的「十位杰出科学家」之一、2013年美国国家科学院Kavli Fellow、2018年和2024年的Longuet-Higgins奖,以及因其代表性工作(如COCO数据集)获得的Koenderink奖。此外,他的论文在CVPR、ECCV和ICCV上多次获得最佳论文提名及荣誉奖。他的研究成果对视觉识别、自动驾驶、和人机交互等应用产生了深远影响,是该领域极具影响力的科学家之一。
参考资料:
https://arxiv.org/abs/2404.01291
https://arxiv.org/abs/2406.13743
文章来自于微信公众号“新智元”



【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
