# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
网络智能体旨在让一切基于网络功能的任务自动发生。比如你告诉智能体你的预算,它可以帮你预订酒店。既拥有海量常识,又能做长期规划的大语言模型(LLM),自然成为了智能体常用的基础模块。
于是上下文学习示例、任务技巧、多智能体协同、强化学习算法…… 一切适用于通用智能体的想法都抢着在大模型落地。
然而有一个问题始终横亘在 LLM 和智能体之间:基于 LLM 的网络智能体的行动 / 观测空间与 LLM 训练数据的空间相去甚远。
智能体在充斥着具身行为的行动空间(如鼠标悬停、键盘组合键)和遍布前端功能强化、格式渲染的观测空间下运作,大语言模型的理解和推理能力能充分发挥作用吗?尤其是大语言模型的主要训练任务是文本补全、问答和对齐人类偏好,这一点值得思考。
来自伊利诺伊大学香槟分校和亚马逊的研究人员选择和这些问题进一步对话。他们去除了上下文示例、技巧、多智能体系统,仅仅通过行动 / 观测空间与 LLM 的训练任务对齐。他们训练的 AgentOccam 成为了零样本基于 LLM 的网络智能体新 Sota。

帮你写email

帮你找导师
这正呼应了奥卡姆剃刀原则:「若无必要,勿增实体」。然而换个思考的角度,AgentOccam 的研究团队也想发问:构建通用智能体时,在铺设复杂的系统框架前,是否已经优化了行动 / 观测空间,让这些功能模块达到了最优状态?

某天你刷着短视频,看中了主播手中拿着的商品。于是,你兴致勃勃地对智能助手说:「我是学生,让这个老板送我一张优惠券!」
随后,智能体申请了你的私人账号权限、后台私信商家、绘声绘色地写下「我是学生」,发送消息,一套动作无需人为干预,行云流水......一切这样的任务,再也不必动手,都有智能体代劳。
大语言模型是构建智能体的热门选择。过去,基于 LLM 的网络智能体通常专注于让智能体学会某种应用,比如构建上下文学习样本、积累任务经验与技巧、以及多智能体角色扮演等等。然而,在实际交互中,智能体的行动 / 观测空间与 LLM 的技能点不太匹配,这之间的差距却少有人研究。
于是,针对如何对齐基于 LLM 的网络智能体的观测和行动空间与其训练期间学到的功能,来自伊利诺伊大学香槟分校和亚马逊的研究人员们展开了研究。
网络智能体需要准确地从格式各异、编码脚本不一的网页中提取信息,并在网页上定义的动作(例如,鼠标滑轮滚动、点击或悬停在按钮上)中进行选择。这些网络观测和行动空间在 LLM 的预训练和后续训练数据中都较为罕见,这阻碍了 LLM 充分调动潜能,完成任务。
因此,基于不让智能体策略变得更复杂,而是让智能体与 LLM 更加匹配的想法,由此构建的智能体得名 AgentOccam。


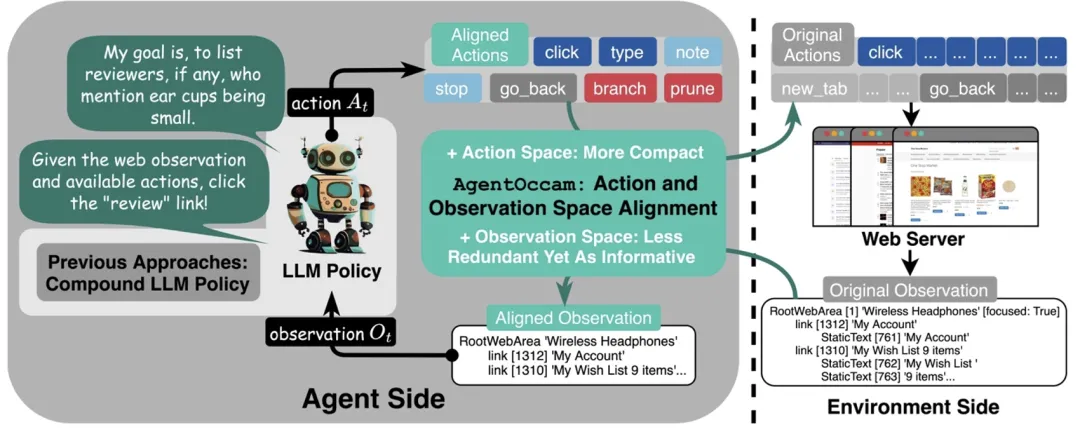
如上图所示,AgentOccam 包括三个组成部分:
整个框架通过一套适用于所有标记语言的通用规则来格式化网页,无需依赖测试基准中的任务相关信息。
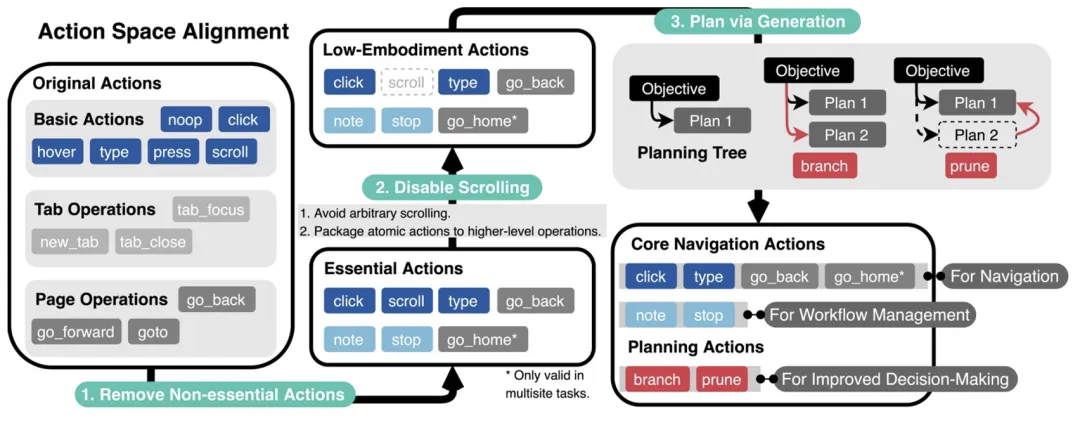
网络智能体的行动空间规定了可以用来与网络环境交互的有效命令。
研究团队从智能体常见的失败中得出总结:想要成功完成任务,需要编辑行动空间来解决两个关键问题:第一,去除 LLM 难以理解且经常误用的无关行动;第二,当执行任务需要规划、尝试多个潜在路径时,要提高智能体的记忆和规划能力。
为此,该团队提出了对应的解决方法。第一个问题可以通过简单地移除或合并操作来解决(如上图中的步骤 1 和 2)。对于第二个问题,过去的研究通常依赖人工制定规则或任务技巧,但这些方法难以泛化。在本研究中,LLM 将自主生成计划和管理任务流程(如步骤 3 所示)。

AgentOccam 的观测空间(提示词)包含了任务概述的通用指令、期望的输出和可用操作说明,以及关于当前任务目标、智能体过去的交互记录和最新的观察信息。
过往互动和当前观测的部分占据了最多的字符数。这主要归因于两个因素:单页面的长度和历史跨度的范围,这是 AgentOccam 观测空间的主要优化对象。

网页标记语言主要用于前端加载和渲染,往往包含大量格式化字符,显得冗余且重复(如上图步骤 1 所示)。因此,此时的目标是优化这些表示方式,使得单页内容对 LLMs 更加简洁易读。
将观测历史作为输入,对于执行长程任务至关重要。因为一些关键信息可能不会显示在当前页面上。然而,观测历史也会显著增加上下文长度,并增加推理难度以及推断成本。
为了解决这个问题,设置仅选择先前网页上最重要和相关的信息,这一选择依据两个规则,分别基于关键节点和规划树,见于步骤 2 和 3。
研究团队在 WebArena 上评估了 AgentOccam 性能。WebArena 含有 812 项任务,横跨网购、社交网站、软件开发、在线商贸管理、地图等。
测试对象为 AgentOccam 框架下的 GPT-4-Turbo。对比的基线包括:一、WebArena 随配智能体,二、SteP,前 WebArena 上最优智能体,涵盖 14 条人类专为 WebArena 任务编写的技巧,三、多智能体协同方法 WebPilot;四、总结智能体交互经验的工作 AWM。
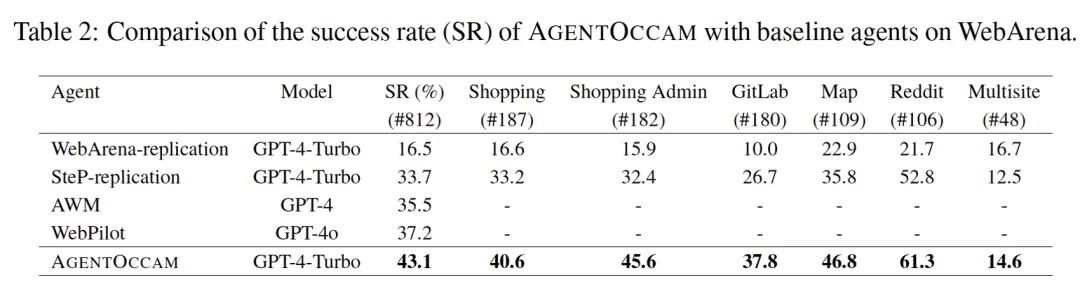
从上表不难看出,AgentOccam 性能优于以往及同期工作。其中,AgentOccam 分别以 9.8(+29.4%)和 5.9(+15.8%)的绝对分数领先往期和同期工作,并且通过其观测与行动空间的对齐,使得相似的基本网络智能体的成功率提高了 26.6 点(+161%)。
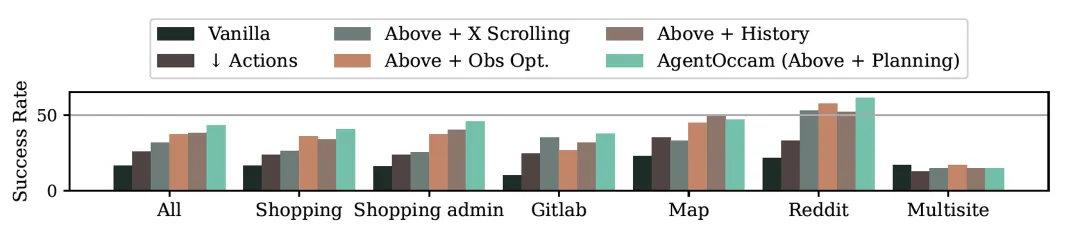
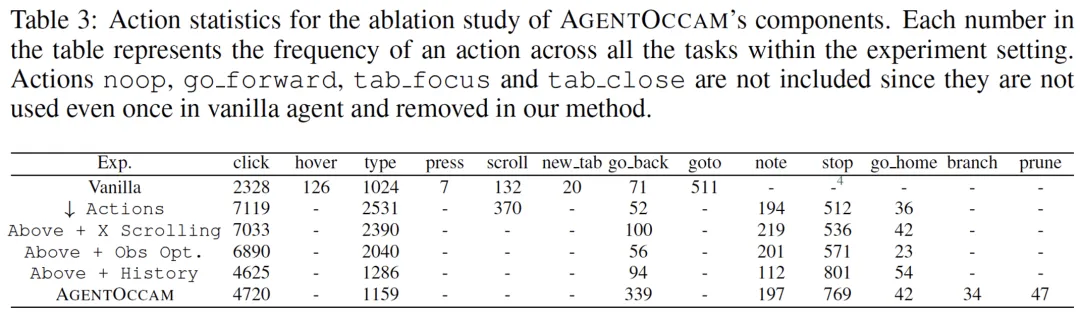
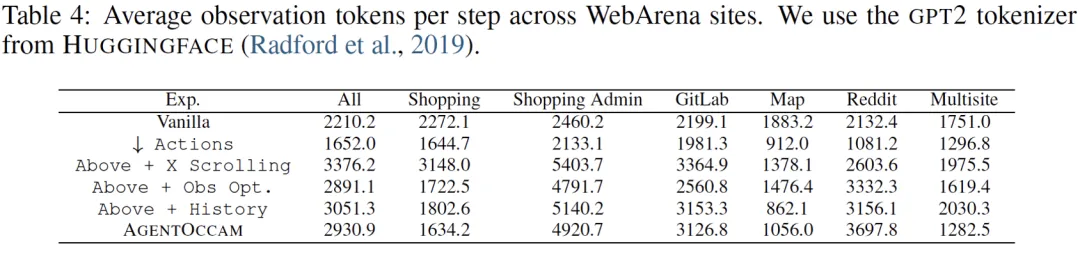
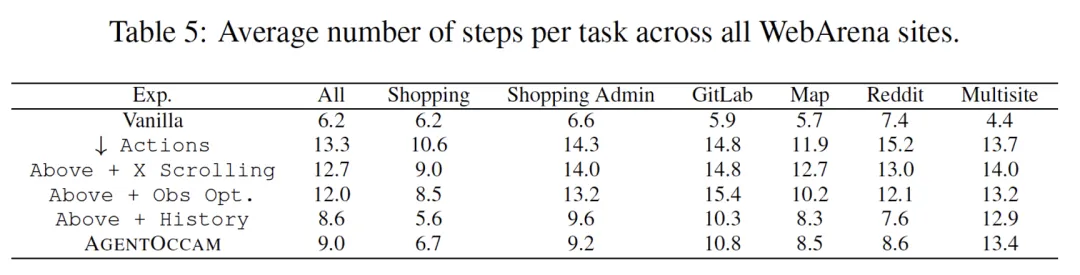
逐模块对比行动与观测空间的对齐对最终结果的贡献。从下表可以看出,行动空间对齐能使智能体完成更多 click、type 等引导环境变化的动作,观测空间对齐则减少大模型调用的字符数与智能体完成任务所需的步数。
研究团队发现,智能体的决策行为波动性很强。简而言之,面对一个目标,智能体有一定概率做出正确的行为决断,但由于 token 预测的随机性,它可能做出一些高成本、低回报的决定。这也导致它在后续步骤中难以纠正之前的错误而失败。
例如,要求智能体在某个最相关的话题下发布帖子,单次 LLM 调用的 AgentOccam 往往轻率地选择话题,未考虑「最相关」的要求。
为了解决此类问题,他们引导 AgentOccam 生成单步内所有可能的行动,这系列行动将交付另一个 Judge 智能体(同样调用 GPT-4-turbo)决断,做出最大化回报的选择。
复合策略中,与任务相关的经验可以提升智能体性能。同时,不因为加入了更多背景知识扰乱决策,不会影响泛化性,能够纠正错误行为模式。
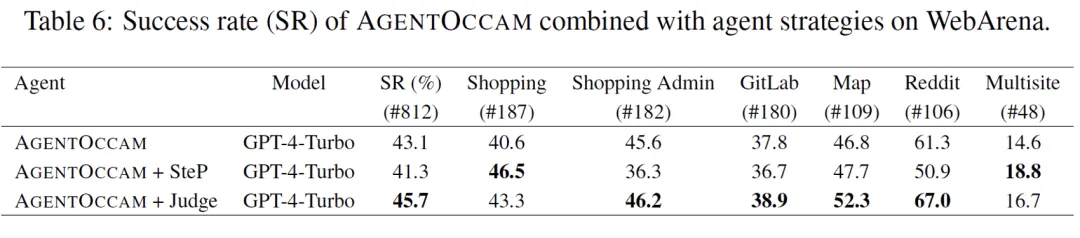
由于行为 / 观测空间对齐和复合策略方法正交,因此能结合利用。该团队试验将 AgentOccam 与 1)SteP 和 2)上述的 LLM-as-a-Judge 方法联合使用。
对于和前 SOTA 方法 SteP 联合,由于它引入人类编写的 WebArena 任务攻略,在经验密集型任务,如购物网页任务中,人类撰写的引导性经验大幅提升任务成功率。
而在常识泛化密集型任务,如社交网页发帖任务中,不相关知识出现会错误扰乱智能体决策。对于 LLM-as-a-Judge 方法,Judge 角色的引入不影响智能体的泛化性,同时纠正了智能体仓促决策的错误行为模式,在 WebArena 上进一步提升 2.6 的绝对分数。
文章来自于微信公众号“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
